没有完美的数据插补法,只有最适合的
数据缺失是数据科学家在处理数据时经常遇到的问题,本文作者基于不同的情境提供了相应的数据插补解决办法。没有完美的数据插补法,但总有一款更适合当下情况。
我在数据清理与探索性分析中遇到的最常见问题之一就是处理缺失数据。首先我们需要明白的是,没有任何方法能够完美解决这个问题。不同问题有不同的数据插补方法——时间序列分析,机器学习,回归模型等等,很难提供通用解决方案。在这篇文章中,我将试着总结最常用的方法,并寻找一个结构化的解决方法。
插补数据vs删除数据
在讨论数据插补方法之前,我们必须了解数据丢失的原因。
1、随机丢失(MAR,Missing at Random):随机丢失意味着数据丢失的概率与丢失的数据本身无关,而仅与部分已观测到的数据有关。
2、完全随机丢失(MCAR,Missing Completely at Random):数据丢失的概率与其假设值以及其他变量值都完全无关。
3、非随机丢失(MNAR,Missing not at Random):有两种可能的情况。缺失值取决于其假设值(例如,高收入人群通常不希望在调查中透露他们的收入);或者,缺失值取决于其他变量值(假设女性通常不想透露她们的年龄,则这里年龄变量缺失值受性别变量的影响)。
在前两种情况下可以根据其出现情况删除缺失值的数据,而在第三种情况下,删除包含缺失值的数据可能会导致模型出现偏差。因此我们需要对删除数据非常谨慎。请注意,插补数据并不一定能提供更好的结果。
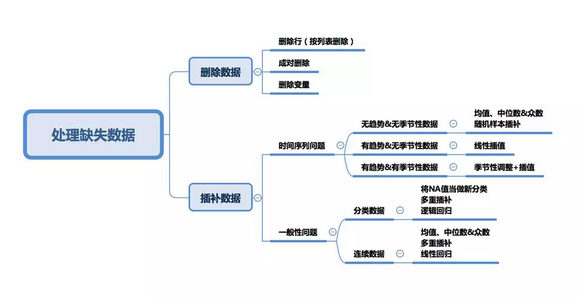
删除
列表删除
按列表删除(完整案例分析)会删除一行观测值,只要其包含至少一个缺失数据。你可能只需要直接删除这些观测值,分析就会很好做,尤其是当缺失数据只占总数据很小一部分的时候。然而在大多数情况下,这种删除方法并不好用。因为完全随机缺失(MCAR)的假设通常很难被满足。因此本删除方法会造成有偏差的参数与估计。

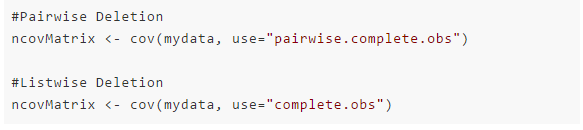
成对删除
在重要变量存在的情况下,成对删除只会删除相对不重要的变量行。这样可以尽可能保证充足的数据。该方法的优势在于它能够帮助增强分析效果,但是它也有许多不足。它假设缺失数据服从完全随机丢失(MCAR)。如果你使用此方法,最终模型的不同部分就会得到不同数量的观测值,从而使得模型解释非常困难。

观测行3与4将被用于计算ageNa与DV1的协方差;观测行2、3与4将被用于计算DV1与DV2的协方差。
删除变量
在我看来,保留数据总是比抛弃数据更好。有时,如果超过60%的观测数据缺失,直接删除该变量也可以,但前提是该变量无关紧要。话虽如此,插补数据总是比直接丢弃变量好一些。

时间序列分析专属方法
前推法(LOCF,Last Observation Carried Forward,将每个缺失值替换为缺失之前的最后一次观测值)与后推法(NOCB,Next Observation Carried Backward,与LOCF方向相反——使用缺失值后面的观测值进行填补)
这是分析可能缺少后续观测值的纵向重复测量数据的常用方法。纵向数据在不同时间点跟踪同一样本。当数据具有明显的趋势时,这两种方法都可能在分析中引入偏差,表现不佳。
线性插值。此方法适用于具有某些趋势但并非季节性数据的时间序列。
季节性调整+线性插值。此方法适用于具有趋势与季节性的数据。
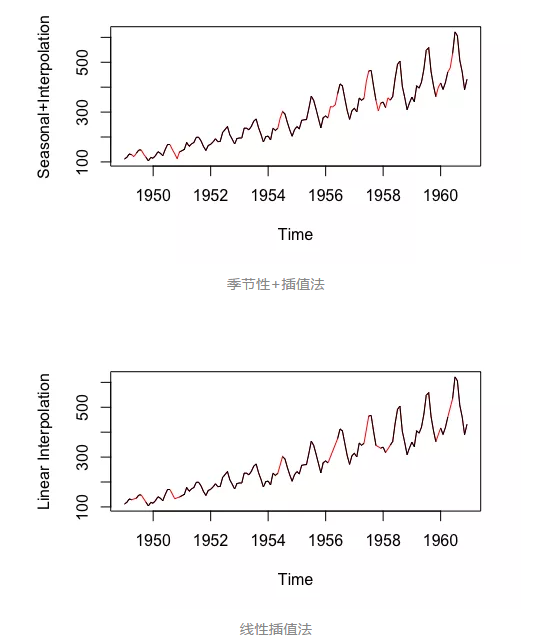
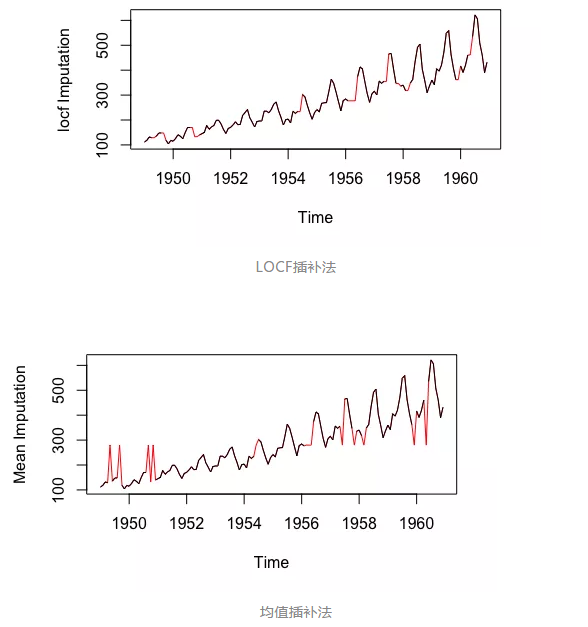
注:以上数据来自imputeTS库的tsAirgap;插补数据被标红。

均值,中位数与众数
计算整体均值、中位数或众数是一种非常基本的插补方法,它是唯一没有利用时间序列特征或变量关系的测试函数。该方法计算起来非常快速,但它也有明显的缺点。其中一个缺点就是,均值插补会减少数据的变化差异(方差)。

线性回归
首先,使用相关系数矩阵能够选出一些缺失数据变量的预测变量。从中选择最靠谱的预测变量,并将其用于回归方程中的自变量。缺失数据的变量则被用于因变量。自变量数据完整的那些观测行被用于生成回归方程;其后,该方程则被用于预测缺失的数据点。在迭代过程中,我们插入缺失数据变量的值,再使用所有数据行来预测因变量。重复这些步骤,直到上一步与这一步的预测值几乎没有什么差别,也即收敛。
该方法“理论上”提供了缺失数据的良好估计。然而,它有几个缺点可能比优点还值得关注。首先,因为替换值是根据其他变量预测的,他们倾向于“过好”地组合在一起,因此标准差会被缩小。我们还必须假设回归用到的变量之间存在线性关系——而实际上他们之间可能并不存在这样的关系。
多重插补
1、插补:将不完整数据集缺失的观测行估算填充m次(图中m=3)。请注意,填充值是从某种分布中提取的。模拟随机抽取并不包含模型参数的不确定性。更好的方法是采用马尔科夫链蒙特卡洛模拟(MCMC,Markov Chain Monte Carlo Simulation)。这一步骤将生成m个完整的数据集。
2、分析:分别对(m个)每一个完整数据集进行分析。
3、合并:将m个分析结果整合为最终结果。
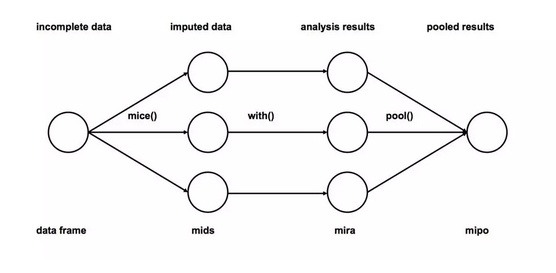
来源:

这是迄今为止最优选的插补方法,因为它非常易于使用,并且在插补模型正确的情况下它不会引入偏差。
分类变量插补
1、众数插补法算是一个法子,但它肯定会引入偏差。
2、缺失值可以被视为一个单独的分类类别。我们可以为它们创建一个新类别并使用它们。这是最简单的方法了。
3、预测模型:这里我们创建一个预测模型来估算用来替代缺失数据位置的值。这种情况下,我们将数据集分为两组:一组剔除缺少数据的变量(训练组),而另一组则包括缺失变量(测试组)。我们可以用逻辑回归和ANOVA等方法来进行预测。
4、多重插补法。
KNN(K近邻)
能够用于数据插补的机器学习方法有很多,比如XGBoost与Random Forest,但在这里我们讨论KNN方法,因为它被广泛应用。在本方法中,我们根据某种距离度量选择出k个“邻居”,他们的均值就被用于插补缺失数据。这个方法要求我们选择k的值(最近邻居的数量),以及距离度量。KNN既可以预测离散属性(k近邻中最常见的值)也可以预测连续属性(k近邻的均值)。
根据数据类型的不同,距离度量也不尽相同:
1、连续数据:最常用的距离度量有欧氏距离,曼哈顿距离以及余弦距离。
2、分类数据:汉明(Hamming)距离在这种情况比较常用。对于所有分类属性的取值,如果两个数据点的值不同,则距离加一。汉明距离实际上与属性间不同取值的数量一致。
KNN算法最吸引人的特点之一在于,它易于理解也易于实现。其非参数的特性在某些数据非常“不寻常”的情况下非常有优势。
KNN算法的一个明显缺点是,在分析大型数据集时会变得非常耗时,因为它会在整个数据集中搜索相似数据点。此外,在高维数据集中,最近与最远邻居之间的差别非常小,因此KNN的准确性会降低。

在上述方法中,多重插补与KNN最为广泛使用,而由于前者更为简单,因此其通常更受青睐。

时间:2018-10-23 16:59 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:
最新文章

热门文章














