Kafka 在行动:7步实现从RDBMS到Hadoop的实时流传输

对于寻找方法快速吸收数据到Hadoop数据池的企业, Kafka是一个伟大的选择。Kafka是什么? 它是一个分布式,可扩展的可靠消息系统,把采取发布-订阅模型的应用程序/数据流融为一体。 这是Hadoop的技术堆栈中的关键部分,支持实时数据分析或物联网数据货币化。
本文目标读者是技术人员。 继续读,我会图解Kafka如何从关系数据库管理系统(RDBMS)里流输数据到Hive, 这可以提供一个实时分析使用案例。 为了参考方便,本文使用的组件版本是Hive 1.2.1,Flume 1.6和Kafka 0.9。
如果你想看一下Kafka是什么和其用途的概述, 看看我 在Datafloq 上发布的一篇早期博客。
Kafka用武之地:整体解决方案架构
下图显示了在整体解决方案架构中,RDBMS的业务数据传递到目标 Hive 表格结合了 Kafka , Flume和Hive交易功能。
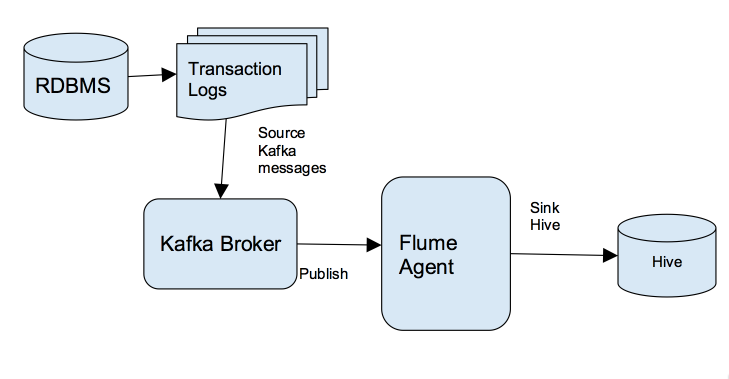
7步实时流传输到Hadoop
现在深入到解决方案的详细信息,我会告诉你如何简单几步实时流输数据到Hadoop。
1. 从关系数据库管理系统(RDBMS)提取数据
所有关系数据库都有一个记录最近交易的日志文件。 我们的传输流解决方案的第一步是,在能够传到Hadoop的信息格式中获得这些交易。 讲完提取机制得单独占用一篇博文–所以 如果你想了解更多此过程的信息, 请联系我们。
2. 建立Kafka Producer
发布消息到Kafka主题的过程被称为“生产者”。“主题”是Kafka保存的分类消息。 RDBMS的交易将被转换为Kafka话题。 对于该例,让我们想一想销售团队的数据库,其中的交易是作为Kafka主题发表的。 建立Kafka生产者需要以下步骤:

3. 设置 Hive
接下来,我们将在Hive中创建一张表,准备接收销售团队的数据库事务。 在这个例子中,我们将创建一个客户表:

为了让Hive能够处理交易, 配置中需要以下设置:
hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.dbtxnmanager
4.设置Flume Agent,从Kafka到Hive流传输
现在让我们来看看如何创建Flume代理,实现从Kafka主题中获取数据,发送到Hive表。
遵循步骤来设置环境,然后建立Flume代理:

接着,如下创建一个log4j属性文件:

然后为Flume代理使用下面的配置文件:

5.开启Flume代理
使用如下命令开启Flume代理:
$ /usr/hdp/apache-flume-1.6.0/bin/flume-ng agent -n flumeagent1 -f ~/streamingdemo/flume/conf/flumetohive.conf
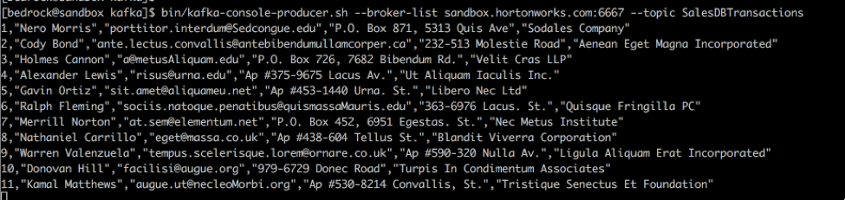
6.开启Kafka Stream
如下示例,是一个模拟交易消息, 在实际系统中需要由源数据库生成。 例如,以下可能来自重复SQL交易的Oracle数据流,这些交易已提交到数据库, 也可能来自GoledenGate。

7.接收Hive数据
以上所有完成, 现在从Kafka发送数据, 你会看到,几秒之内,数据流就发送到Hive表了。
文 | Rajesh Nadipalli

时间:2018-10-10 22:26 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















