大数据时代,“未来战警”应该长什么样?
“老和山极客”团队用大数据开发了一套智能警务系统,看看数据侠们心中的“未来战警”是什么模样。

“未来战警”:一个智能警务平台
说起“未来战警”,脑海中首先浮现的是浑身钢筋铁骨,拿着高科技装备威风凛凛的的模样。不过这种设定显然观赏性大于实用性,对于解决真正的城市犯罪问题,还是得真正的数据侠出马。
在“老和山极客”团队眼里,“未来战警”不是个体,而是一个基于先进算法的人工智能平台,通过自然语言处理、机器学习等方法建立起犯罪预控预与调配机制。这样一个智能平台,被叫做“云沪卫”。
下图是云沪卫展示的警力调度图,你们可以先感受一下:
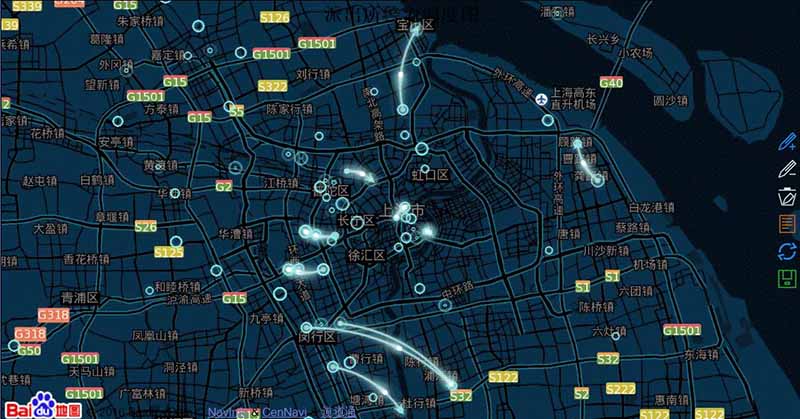
(图片来源:老和山极客)
在开发时,“老和山极客”团队主要使用了SODA开放的犯罪数据、派出所数据等资源,此外他们还融合了百度API的地理信息数据、上海天气数据、交通卡数据、网络舆情数据等,打造了一个基于数据挖掘和机器学习技术,通过自学习实现犯罪监控、热点预测和警力调配的智能警务系统。
“老和山极客”团队觉得,在大数据时代,智能警务系统对改善城市治安有巨大作用。实际上,在美国已经出现了如Predpol等智能警务系统,它们能够帮助警察预测犯罪、智能调配警力等,帮助一些地区的抢劫犯罪率和入室盗窃犯罪率降低了15%到30%,还减少了日常的巡逻开支。
不过,中国的警务系统与国外有较大差异,云沪卫这个平台又是如何适应中国国情的呢?
“定制”词库深度学习,计算犯罪热度
基于自然语言处理的文本分析技术,是“老和山极客”处理中国警务数据的核心方法之一。
要搭建这个云沪卫平台,首先要收集犯罪记录,计算犯罪事件发生的“热度”。原始的派出所出警日志数据数量庞大,而且具有重复性、事件并发性与语言模糊性的特点,很难让机器去识别他们。
于是,与很多使用自然语言处理技术的团队相似,“老和山极客”也是先将文本转化成向量,再利用半监督学习的方法对文本进行分词和聚类。
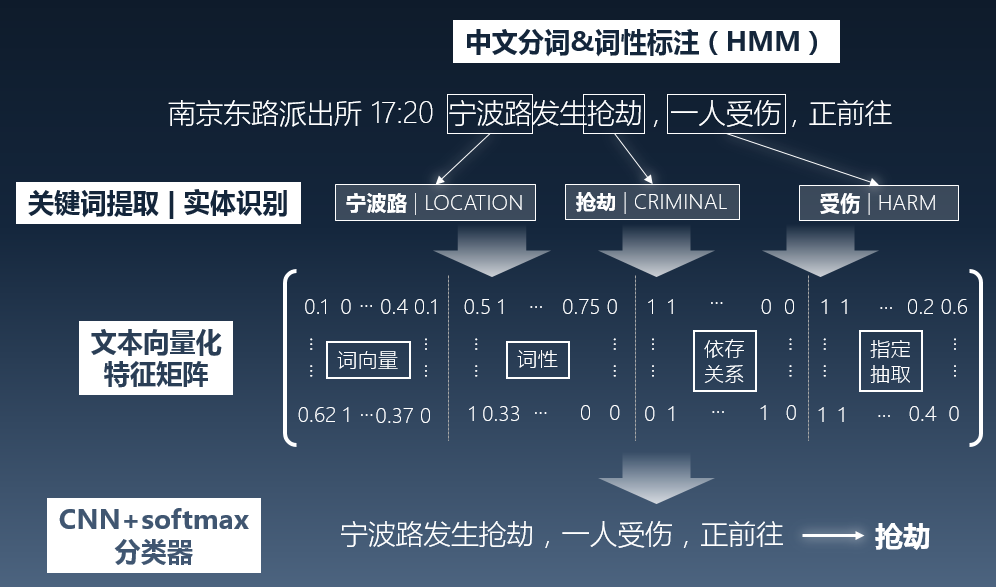
(图片来源:老和山极客)
在机器学习阶段,由于网络上目前没有中文犯罪信息词库,“老和山极客”团队邀请了一些业内专家,亲自来标定了训练文本词库。在复赛阶段,他们标定了8万条训练样本;决赛阶段,他们添加了新的微博数据,把训练量扩大到了十倍,达到80万条文本。充足的样本数据能够极大优化机器学习的精度。结果表明,9类犯罪事件中,6类事件的分类准确率都在95%以上,其余3类也超过了85%。
接下来,团队根据类型对每一次的案件进行了量化打分,然后对每个派出所每个时段的分数进行统计求和,计算出犯罪热度。
核心算法帮助制作犯罪预测地图
要实现对犯罪热点的预测,仅有犯罪热度的数据显然是不够的,“老和山极客”团队还采集了包括:日期属性、区域属性、时间段、交通、人流、摄像头数据、天气、历史数据等9个特性信息,精准描述犯罪事件的各个维度。
团队采用了GBDT (Gradient Boosting Decision Tree)算法作为预测犯罪热点的算法原型。GBDT又叫 MART(Multiple Additive Regression Tree),是一种迭代的决策树算法。该算法由多棵决策树组成,所有树的结论累加起来做最终答案。近年来,GBDT算法在预测类比赛中凭借优异的性能表现突出,常用来做预测、分类等工作,也适用于类别特征较多的样本。
云沪卫将之前搜集到的9个特征纳入GBDT算法进行统计学习,得到了预测模型。
下图展示的就是一个模拟的实时上海犯罪热点预测图:
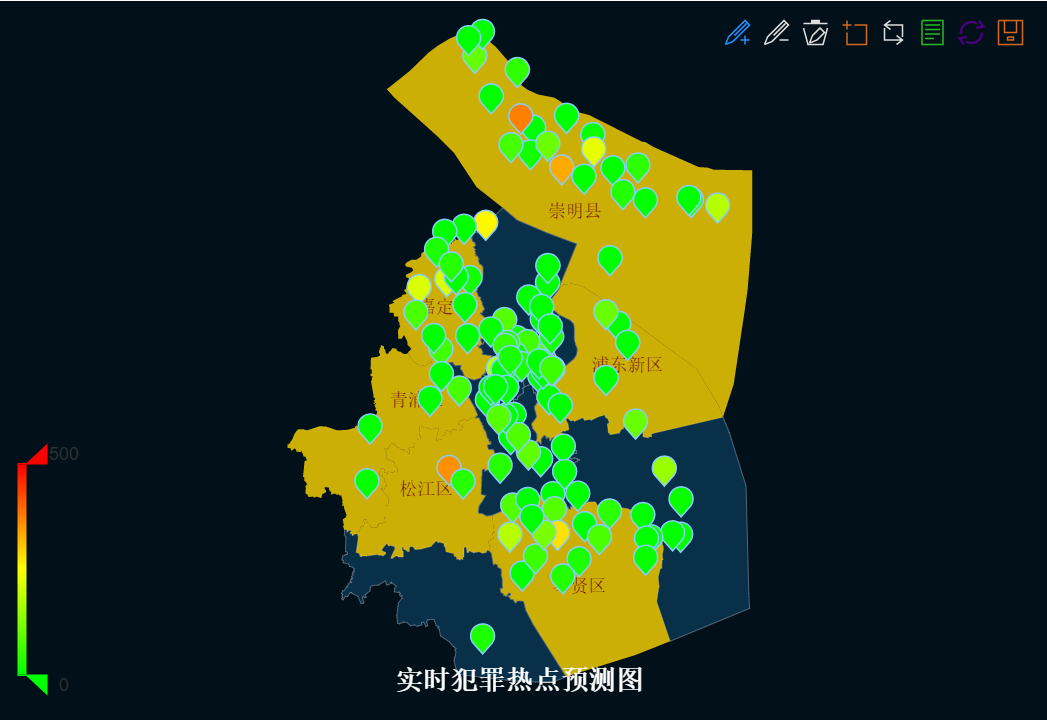
(图片来源:老和山极客)
虽然目前已经开发出了测试版原型,但是如果要真正应用这套警务系统,“老和山极客”团队坦言,还需要更多真实的数据。如果接下来继续有实时数据的支撑,搜集到的数据就能够被系统自动分析纳入预测模型中,不断优化调整预测结果,实现对实时犯罪热点的预测。
“警务数据是非常敏感的数据信息,如果使用不当,甚至会造成很严重的安全后果。”“老和山极客”队长宣羿表示,对于这类敏感数据的安全问题,在创造价值的同时,也需要警方、政府等官方机构用更完善的标准来衡量把控。
接下来,云沪卫希望能和警方等政府部门合作,在保证数据安全的情况下,使用更真实、完整的数据对平台进行优化改进。另一方面,他们还会再平台上开通舆情监控、举报监控等功能,让普通民众也参与到城市安全的建设中去,加强警民联动,打造一个真正的“未来战警”。

时间:2018-10-09 22:57 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















