学会用Spark实现朴素贝叶斯算法
第一部分:回顾以前的一篇文章
简单之极,搭建属于自己的Data Mining环境(Spark版本)很多朋友也亲自动手搭建了一遍,当然也遇到不少困难,我都基本一对一给予了回复,具体可以查看原文。
下面的实践也主要是基于上述部署的环境来进行开发。
第二部分:初步学习Spark与数据挖掘相关的核心知识点
对于这部分的介绍,不扩展到Spark框架深处,仅仅介绍与大数据挖掘相关的一些核心知识,主要分了以下几个点:
初步了解spark
- 适用性强:它是一种灵活的框架,可同时进行批处理、 流式计算、 交互式计算。
- 支持语言:目前spark只支持四种语言,分别为java、python、r和scala。但是个人推荐尽量使用原生态语言scala。毕竟数据分析圈和做数据科学研究的人群蛮多,为了吸引更多人使用spark,所以兼容了常用的R和python。
与MapReduce的差异性
- 高效性:主要体现在这四个方面,提供Cache机制减少数据读取的IO消耗、DAG引擎减少中间结果到磁盘的开销、使用多线程池模型来减少task启动开销、减少不必要的Sort排序和磁盘IO操作。
- 代码简洁:解决同一个场景模型,代码总量能够减少2~5倍。从以前使用MapReduce来写模型转换成spark,这点我是切身体会。
理解spark离不开读懂RDD
- spark2.0虽然已经发测试版本和稳定版本,但是迁移有一定成本和风险,目前很多公司还处于观望阶段。
- RDD(Resilient Distributed Datasets), 又称弹性分布式数据集。
- 它是分布在集群中的只读对象集合(由多个Partition构成)。
- 它可以存储在磁盘或内存中(多种存储级别),也可以从这些渠道来创建。
- spark运行模式都是通过并行“转换” 操作构造RDD来实现转换和启动。同时RDD失效后会自动重构。
从这几个方面理解RDD的操作
- Transformation,可通过程序集合、Hadoop数据集、已有的RDD,三种方式创造新的RDD。这些操作都属于Transformation(map, filter, groupBy, reduceBy等)。
- Action,通过RDD计算得到一个或者一组值。这些操作都属于Action(count, reduce, saveAsTextFile等)。
- 惰性执行:Transformation只会记录RDD转化关系,并不会触发计算。Action是触发程序执行(分布式) 的算子。
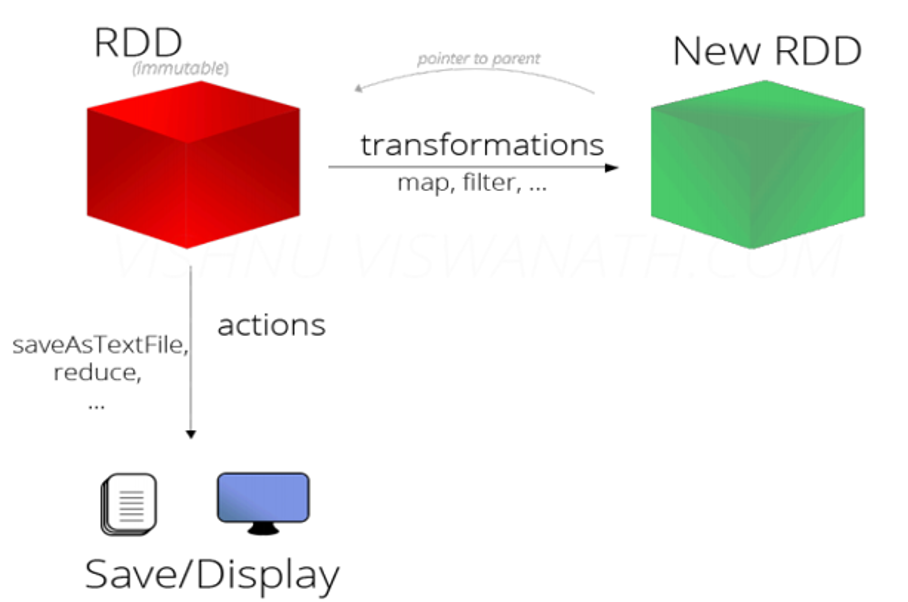
一张图概括RDD
知晓Spark On Yarn的运作模式
除了本地模式的spark程序测试,大部分工作都是基于Yarn去提交spark任务去执行。因此对于提交执行一个spark程序,主要有以下流程的运作模式。(提交任务:bin/spark-submit --master yarn-cluster --class …)

一张图知晓运作模式
懂得spark本地模式和yarn模式的提交方式(不讨论Standalone独立模式)
如果说上述的概念、执行流程和运作方式目的在于给做大数据挖掘的朋友一个印象,让大家不至于盲目、错误的使用spark,从而导致线上操作掉坑。那最后的本地模式测试和集群任务提交是必须要掌握的知识点。
- 本地模式(local):单机运行,将Spark应用以多线程方式直接运行在本地,通常只用于测试。我一般都会在windows环境下做充足的测试,无误以后才会打包提交到集群去执行。慎重!
- YARN/mesos模式:运行在资源管理系统上,对于Yarn存在两种细的模式,yarn-client和yarn-cluster,它们是有区别的。
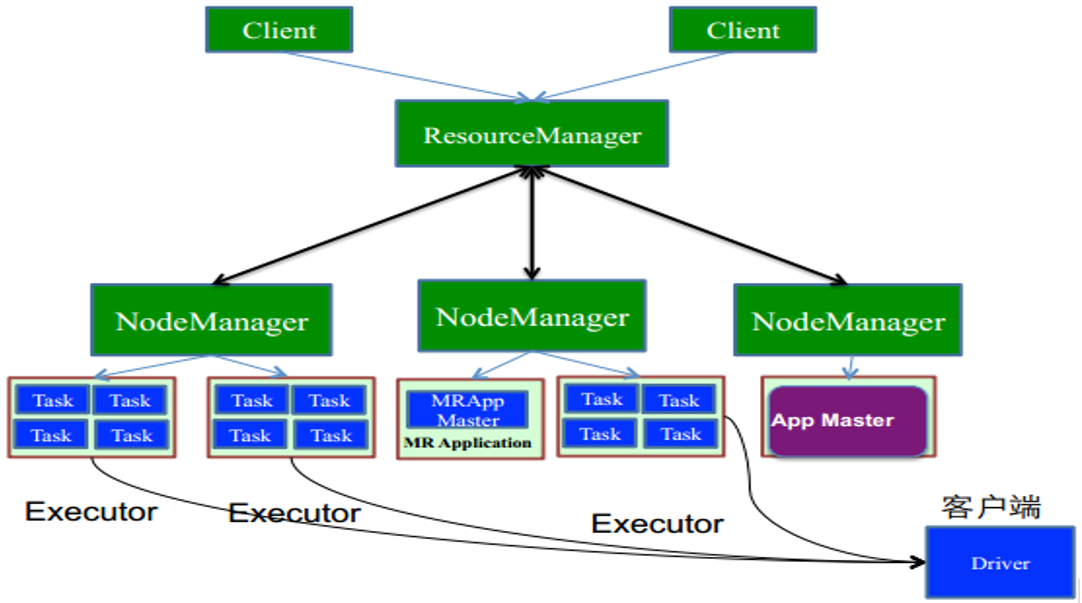
一张图知晓yarn-client模式
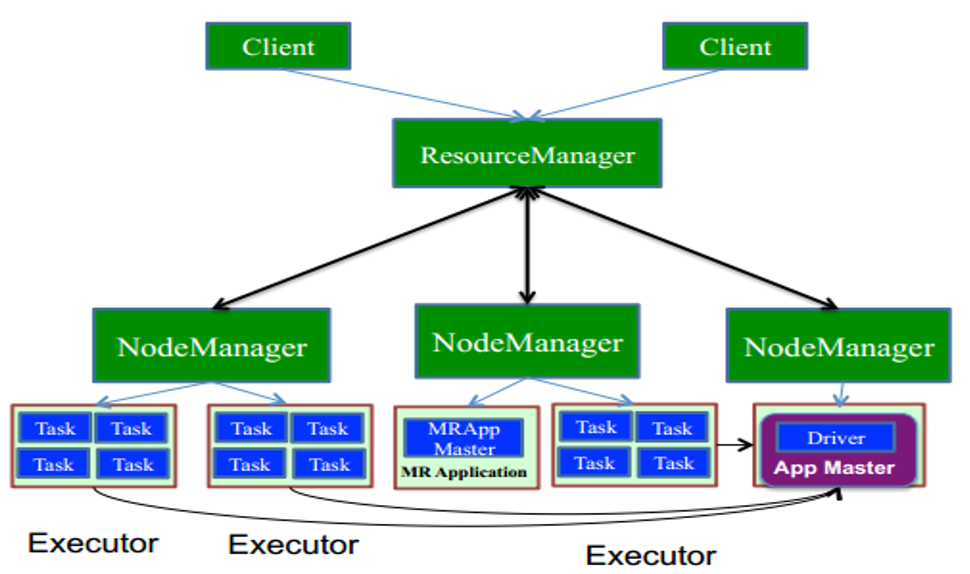
一张图知晓yarn-cluster模式
为了安全起见,如果模型结果文件最终都是存于HDFS上的话,都支持使用yarn-cluster模式,即使某一个节点出问题,不影响整个任务的提交和执行。
总结:很多做大数据挖掘的朋友,代码能力和大数据生态圈的技术会是一个软弱,其实这点是很不好的,关键时候容易吃大亏。而我上面所提的,都是围绕着写好一个场景模型,从code实现到上线发布都需要留心的知识点。多一份了解,少一分无知。况且一天谈什么算法模型,落地都成困难,更别提上线以后对模型的参数修改和特征筛选。
第三部分:创作第一个数据挖掘算法(朴素贝叶斯)
看过以前文章的小伙伴都应该知道,在业务层面上,使用场景最多的模型大体归纳为以下四类:
- 分类模型,去解决有监督性样本学习的分类场景。
- 聚类模型,去自主判别用户群体之间的相似度。
- 综合得分模型,去结合特征向量和权重大小计算出评估值。
- 预测响应模型,去以历为鉴,预测未来。
所以我这里首先以一个简单的分类算法来引导大家去code出算法背后的计算逻辑,让大家知晓这样一个流程。
朴素贝叶斯的实现流程
-
理解先验概率和后验概率的区别?
a.先验概率:是指根据以往经验和分析得到的概率。简单来说,就是经验之谈,打趣来说——不听老人言,吃亏在眼前。
b.后验概率:是指通过调查或其它方式获取新的附加信息,去修正发生的概率。也就是参考的信息量更多、更全。
- 它们之间的转换,推导出贝叶斯公式
条件概率:
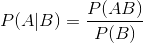
注:公式中P(AB)为事件AB的联合概率,P(A|B)为条件概率,表示在B条件下A的概率,P(B)为事件B的概率。
推导过程:
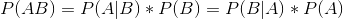
将P(AB)带入表达式
贝叶斯公式:

简单来说,后验概率 = ( 先验概率 * 似然度)/标准化常量。
扩展:
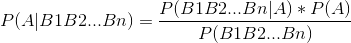

时间:2018-10-09 23:11 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]Spark 迁移到 K8S 在有赞的实践与经验
- [数据挖掘]Spark Operator 初体验
- [数据挖掘]如何实现Spark on Kubernetes?
- [数据挖掘]Spark SQL 物化视图技术原理与实践
- [数据挖掘]Spark on K8S 的最佳实践和需要注意的坑
- [数据挖掘]Spark 3.0重磅发布!开发近两年,流、Python、SQL重
- [数据挖掘]Spark 3.0开发近两年终于发布,流、Python、SQL重大
- [数据挖掘]Apache Spark 3.0.0 正式版终于发布了,重要特性全面
- [数据挖掘]Spark 3.0 自适应查询优化介绍,在运行时加速 Sp
- [数据挖掘]Flink SQL vs Spark SQL
相关推荐:
网友评论:















