利用 Scikit Learn的Python数据预处理实战指南

简介
本文主要关注在Python中进行数据预处理的技术。学习算法的出众表现与特定的数据类型有密切关系。而对于没有经过缩放或非标准化的特征,学习算法则会给出鲁莽的预测。像XGBoost这样的算法明确要求虚拟编码数据,而决策树算法在有些情况下好像完全不关心这些!
简而言之,预处理是指在你将数据“喂给”算法之前进行的一系列转换操作。在Python中,scikit-learn库在sklearn.preprocessing下有预装的功能。有更多的选择来进行预处理,这将是我们要探索的。
读完本文,你将具备数据预处理的基本技能并对其有更深入的理解。为了方便起见,我附上了进一步学习机器学习算法的一些资源,并且为更好地掌握这些概念,设计了几个小练习。
可用数据集
本文中,我使用了部分的贷款预测数据,缺失观测值的数据已被移除(需要数据的读者朋友,请在评论区留下电邮地址,我们会把数据发给你——译者注)。
备注:贷款预测问题中,测试集数据是训练集的子集。
现在,让我们从导入重要的包和数据集开始。

对我们的数据集进行仔细观察。

特征缩放
特征缩放是用来限制变量范围的方法,以让它们能在相同的尺度上进行比较。这是在连续变量上操作的。让我们输出数据集中所有连续变量的分布。
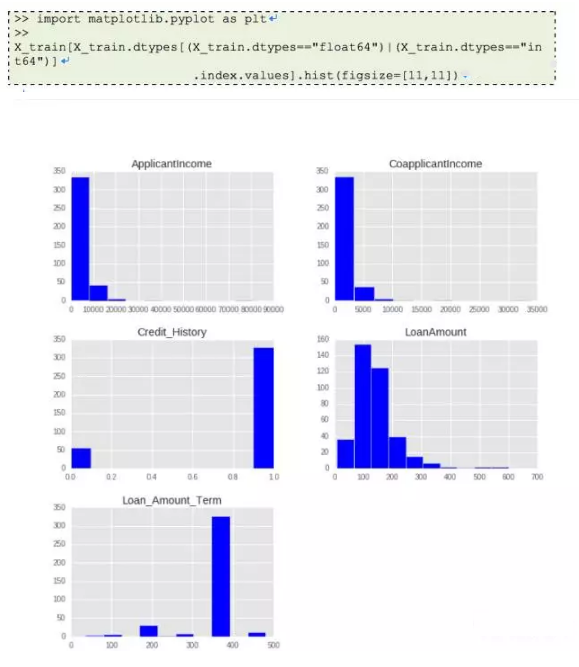
理解以上图示后,我们推断ApplicantIncome(申请人收入) 和CoapplicantIncome(共同申请人收入) 有相似的尺度范围(0-50000$),LoanAmount(贷款额度) 以千为单位,范围在0 到 600$之间,而Loan_Amount_Term(贷款周期)与其它变量完全不同,因为它的单位是月份,而其它变量单位是美元。
如果我们尝试应用基于距离的算法,如KNN,在这些特征上,范围最大的特征会决定最终的输出结果,那么我们将得到较低的预测精度。我们可通过特征缩放解决这个问题。让我们实践一下。
资料:阅读这篇关于KNN的文章获得更好的理解。(https://www.analyticsvidhya.com/blog/2014/10/introduction-k-neighbours-algorithm-clustering/)
让我们在我们的数据集中试试KNN,看看它表现如何。

我们得到了大约61%的正确预测,这不算糟糕,但在真正实践中,这是否足够?我们能否将该模型部署于实际问题中?为回答该问题,让我们看看在训练集中关于Loan_Status(贷款状态) 的分布。
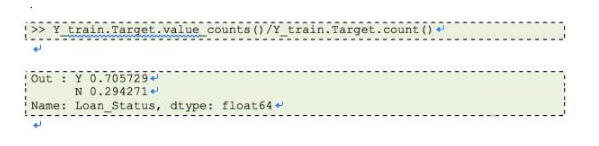
大约有70%贷款会被批准,因为有较高的贷款批准率,我们就建立一个所有贷款都通过的预测模型,继续操作并检测我们的预测精度。
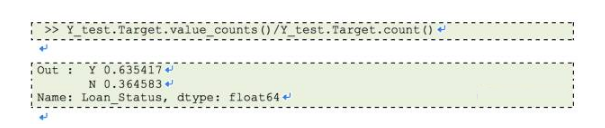
哇!通过猜测,我们获得63%的精度。这意味着,该模型比我们的预测模型得到更高的精度?
这可能是因为某些具有较大范围的无关紧要的变量主导了目标函数。我们可以通过缩小所有特征到同样的范围来消除该问题。Sklearn提供了MinMaxScaler 工具将所有特征的范围缩小到0-1之间,MinMaxScaler 的数学表达式如下所示:
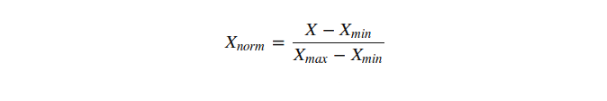
让我们在我们的问题中试试该工具。

现在,我们已经完成缩放操作,让我们在缩放后的数据上应用KNN并检测其精度。

太好了!我们的精度从61%提升到了75%。这意味在基于距离的方法中(如:KNN),一些大范围的特征对预测结果有决定性作用。
应当牢记,当使用基于距离的算法时,我们必须尝试将数据缩放,这样较不重要的特征不会因为自身较大的范围而主导目标函数。此外,具有不同度量单位的特征也应该进行缩放,这样给每个特征具有相同的初始权重,最终我们会得到更好的预测模型。
练习1
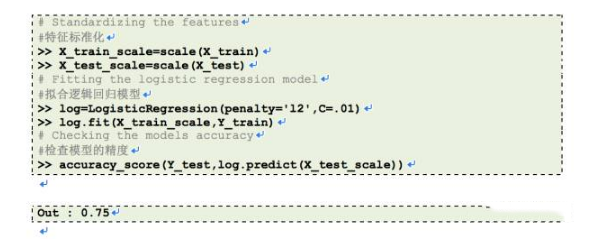
尝试利用逻辑回归模型做相同的练习(参数: penalty=’l2′,C=0.01), 并请在评论区留下缩放前后的精度。
特征标准化
在进入这部分内容前,我建议你先完成练习1。
在之前的章节,我们在贷款预测数据集之上操作,并在其上拟合出一个KNN学习模型。通过缩小数据,我们得到了75%的精度,这看起来十分不错。我在逻辑回归模型上尝试了同样的练习, 并得到如下结果:
缩放前:61%
缩放后:63%
缩放后的精度与我们凭猜测得到的预测精度相近,这并不是很了不起的成就。那么,这是怎么回事呢?在精度上,为什么不像用KNN一样有令人满意的提升?
资料:https://www.analyticsvidhya.com/blog/2015/08/comprehensive-guide-regression/获得对逻辑回归更好的理解。
答案在此:
在逻辑回归中,每个特征都被分配了权重或系数(Wi)。如果某个特征有相对来说比较大的范围,而且其在目标函数中无关紧要,那么逻辑回归模型自己就会分配一个非常小的值给它的系数,从而中和该特定特征的影响优势,而基于距离的方法,如KNN,没有这样的内置策略,因此需要缩放。
我们是否忘了什么?我们的逻辑模型的预测精度和猜测的几乎接近。
现在,我将在此介绍一个新概念,叫作标准化。很多Sklearn中的机器学习算法都需要标准化后的数据,这意味数据应具有零均值和单位方差。
标准化(或Z-score正则化)是对特征进行重新调整,让数据服从基于 μ=0 和 σ=1的标准正态分布,其中μ是均值(平均值)而σ是关于均值的标准偏差。样本的标准分数(也称为z-scores)按如下所示的方法计算:
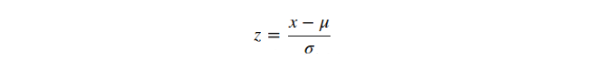
线性模型中因子如l1,l2正则化和学习器的目标函数中的SVM中的RBF核心假设所有的特征都集中在0周围并且有着相同顺序的偏差。
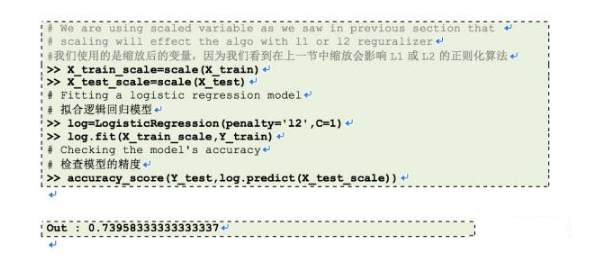
有更大顺序的方差的特征将在目标函数上起决定作用,因为前面的章节中,有着更大范围的特征产生过此情形。 正如我们在练习1中看到的,没进行任何预处理的数据之上的精度是61%,让我们标准化我们的数据,在其上应用逻辑回归。Sklearn提供了尺度范围用于标准化数据。
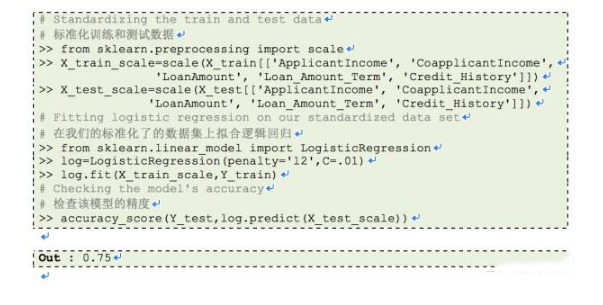
我们再次达到缩放后利用KNN所能达到的我们最大的精度。这意味着,当使用l1或l2正则化估计时,标准化数据帮助我们提高预测模型的精度。其它学习模型,如有欧几里得距离测量的KNN、k-均值、SVM、感知器、神经网络、线性判别分析、主成分分析对于标准化数据可能会表现更好。
尽管如此,我还是建议你要理解你的数据和对其将要使用的算法类型。过一段时间后,你会有能力判断出是否要对数据进行标准化操作。
备注:在缩放和标准化中二选一是个令人困惑的选择,你必须对数据和要使用的学习模型有更深入的理解,才能做出决定。对于初学者,你可以两种方法都尝试下并通过交叉验证精度来做出选择。
资料: https://www.analyticsvidhya.com/blog/2015/11/improve-model-performance-cross-validation-in-python-r/ 会对交叉验证有更好的理解。
练习2
尝试利用SVM模型做相同的练习,并请在评论区留下标准化前后的精度。
资料: https://www.analyticsvidhya.com/blog/2015/10/understaing-support-vector-machine-example-code/ 会对SVM有更好的理解。
标签编码
在前面的章节里,我们对连续数字特征做了预处理。但是,我们的数据集还有其它特征,如性别(Gender)、婚否(Married)、供养人(Dependents)、自雇与否(Self-Employed)和教育程度(Education)。所有这些类别特征的值是字符型的。例如,性别(Gender)有两个层次,或者是男性(Male),或者是女性(Female)。让我们把这些特征放进我们的逻辑回归模型中。
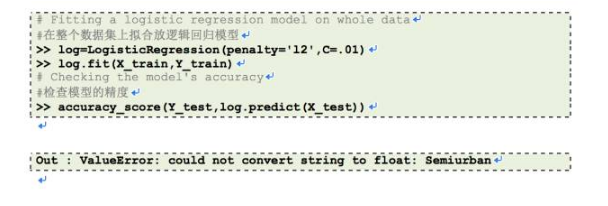
我们得到一个错误信息:不能把字符型转换成浮点型。因此,这里真正在发生的事是像逻辑回归和基于距离的学习模式,如KNN、SVM、基于树的方法等等,在Sklearn中需要数字型数组。拥有字符型值的特征不能由这些学习模式来处理。
Sklearn提供了一个非常有效的工具把类别特征层级编码成数值。LabelEncoder用0到n_classes-1之间的值对标签进行编码。
让我们对所有的类别特征进行编码。

我们所有的类别特征都已编码。用X_train.head()可以查看更新了的数据集。我们将看下性别(Gender)在编码前后的频率分布。
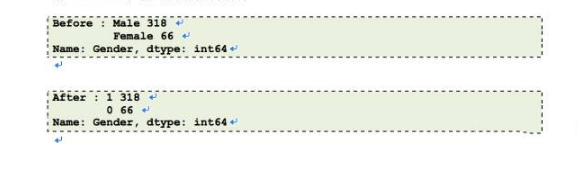
现在我们已经完成了标签编码,让我们在同时有着类别和连续特征的数据集上运行逻辑回归模型。
现在可以用了。但是,精度仍然和我们从数字特征标准化之后用逻辑回归得到的一样。这意味着我们加入的类别特征在我们的目标函数中不是非常显著。
练习3
试试用所有的特征作为非独立变量进行决策树分类,并评论一下你得到的精度。
资料:浏https://www.analyticsvidhya.com/blog/2016/04/complete-tutorial-tree-based-modeling-scratch-in-python/ 中关于决策树的内容以更好地理解。
一位有效编码(One-Hot-Encoding,主要是采用位状态寄存器来对某个状态进行编码,每个状态都有自己独立的寄存器位,并且在任意时候只有一位有效——译者注)。
一位有效编码把每个带有n个可能值的类别特征转换成n个二进制特征,只有一个是有效的。
大多数机器学习算法不是为每个特征设置单个权重就是计算样本之间的距离。如线性模型算法(例如:逻辑回归)属于第一类。
让我们看一看一个来自loan_prediction数据集的例子。特征从属(Feature Dependents)有4个可能的值:0、1、2和3+,这些是编过码的,没有丢掉0、1、2和3的一般性。
在线性分类器中,我们就分配一个权重“W”给这个特征,这将在W*Dependents+K>0或相当于W*Dependents
Let f(w)= W*Dependents
让f(w)=W*Dependents
由方程获得的可能值是0、W、2W和3W。这个方程的一个问题是权重W不能在4个选择的基础上得到。它可以用下面的方法来决定:
• 所有导致同样的决定(所有的值
• 3:2的层级分配(当f(w)>2W时的决策区间)
• 2:2的层级分配(当f(w)>W时的决策区间)
这里我们可以看到丢失了许多不同的可能决策,比如:“0”和“2W”应该给予相同的标签,“3W”和“W”是额外的。
这个问题可以通过一位有效编码来解决,因为它有效地把特征“从属”的维度从1变成4,这样特征“从属”的每个值将有自己的权重。更新了的决策方程将是f'(w) < K。
这里,f'(w) = W1*D_0 + W2*D_1 + W3*D_2 + W4*D_3
所有4个新变量有布尔型值(0或1)。
同样的事发生在基于距离的方法中,如KNN。没有编码,“0”和“1”从属值之间的距离是1,在“0”和“3+”之间的距离是3,这不是所期望的,因为这两个距离应该类似。在编码后,值将有新特征(列序列是0,1,2,3+):[1,0,0,0]和[0,0,0,1](最初我们找到的在“0”和“3+”之间的距离),现在这个距离将会是√2。
对于基于树的方法,同样的情况(在一个特征中有2个以上的值)可能在一定程度上影响输出,但是如果像随机森林的方法,若有足够深的深度,无需一位有效编码就能够处理类别变量。
现在,让我们看下不同算法中的一位有效编码的实现。
让我们创建一个逻辑回归模型用于分类,而不使用一位有效编码。
现在,我们对数据进行编码。

现在,让我们在一位有效编码了的数据上应用逻辑回归模型
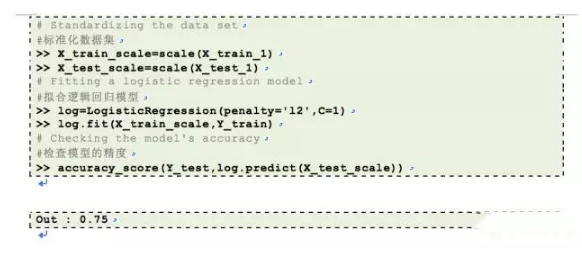
到此,我们再次得到最大的精度是0.75,这是我们迄今所能得到的。在这个例子中,逻辑回归正则(C)参数是1,早前我们用的是C=0.01。
结语
本文的目的是让你熟悉基本的数据预处理技术并对其适用性有更深入的理解。
这些方法有用是因为算法的基本假设。这绝不是一些方法的详尽列表的堆砌。我鼓励你用这些方法尝试一下,因为它们能根据手头的问题进行大量的修改。
在我的下一篇博文中,我计划提供更好的数据预处理技术,像管道和减噪,敬请关注关于数据预处理更深入的探讨。
你喜欢本文吗?你是否采用其它不同的方式、包或库来执行这些任务?
文 | Syed Danish

时间:2018-10-10 22:27 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]底层I/O性能大PK:Python/Java被碾压,Rust有望取代
- [数据挖掘]RedMonk语言排行:Python力压Java,Ruby持续下滑
- [数据挖掘]不得了!Python 又爆出重大 Bug~
- [数据挖掘]TIOBE 1 月榜单:Python年度语言四连冠,C 语言再次
- [数据挖掘]TIOBE12月榜单:Java重回第二,Python有望四连冠年度
- [数据挖掘]这个可能打败Python的编程语言,正在征服科学界
- [数据挖掘]2021年编程语言趋势预测:Python和JavaScript仍火热,
- [数据挖掘]Spark 3.0重磅发布!开发近两年,流、Python、SQL重
- [数据挖掘]Python 为什么推荐蛇形命名法?
- [数据挖掘]Python才是世界上最好的语言
相关推荐:
网友评论:















