阿里云、Amazon、Google 云数据库方案架构与技术分

“「一切都会运行在云端」。云时代早已来临,本文着眼于顶级云服务商云服务商的云数据库方案背后的架构,以及笔者最近观察到的一些对于云数据库有意义的工业界的相关技术的进展,希望读者能有所收获。
现在越来越多的业务从自己维护基础设施转移到公有(或者私有)云上, 带来的好处也是无需赘述的,极大降低了 IaaS 层的运维成本,对于数据库层面来说的,以往需要很强的 DBA 背景才能搞定弹性扩容高可用什么的高级动作,现在大多数云服务基本都或多或少提供了类似的服务。
Amazon RDS
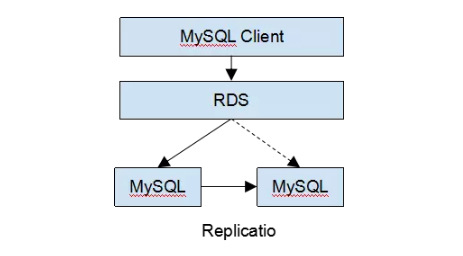
其实说到公有云上的云数据库,应该最早 Amazon 的 RDS,最早应该是在 2009 年发布的,Amazon RDS 的架构类似在底层的数据库上构建了一个中间层(从架构上来看,阿里云 RDS,UCloud RDS 等其他云的 RDS 服务基本是大同小异,比拼的是功能多样性和实现的细节)。
这个中间层负责路由客户端的 SQL 请求发往实际的数据库存储节点,因为将业务端的请求通过中间层代理,所以可以对底层的数据库实例进行很多运维工作,比如备份,迁移到磁盘更大或者 IO 更空闲的物理机等。这些工作因为隐藏在中间层后边,业务层可以做到基本没有感知,另外这个中间路由层基本只是简单的转发请求,所以底层可以连接各种类型的数据库。
所以一般来说,RDS 基本都会支持 MySQL / SQLServer / MariaDB / PostgreSQL 等流行的数据库,对兼容性基本没有损失,而且在这个 Proxy 层设计良好的情况下,对性能的损失是比较小的。另外有一层中间层隔离底层的资源池,对于资源的利用和调度上可以做不少事情。
简单举个例子,比如有一些不那么活跃的 RDS 实例可以调度在一起共用物理机,比如需要在线扩容只需要将副本建立在更大磁盘的机器上,在 Proxy 层将请求重新定向即可,比如定期的数据备份可以放到 S3 上,这些一切都对用户可以做到透明。
但是这样的架构缺点也同样明显:本质上还是一个单机主从的架构,对于超过最大配置物理机的容量,CPU 负载,IO 的场景就束手无策了。随着很多业务的数据量并发量的增长,尤其是移动互联网的发展,无限的可扩展性成为了一个很重要需求。当然对于绝大多数数据量要求没那么大,单实例没有高并发访问的库来说,RDS 仍然是很适合的。
Amazon DynamoDB
对于刚才提到的水平扩展问题,一些用户实在痛的不行,甚至能接受放弃掉关系模型和 SQL。比如一些互联网应用业务模型比较简单,但是并发量和数据量巨大,应对这种情况,Amazon 开发了 DynamoDB,并于 2012 年初发布 DynamoDB 的云服务。其实 Dynamo 的论文早在 2007 年就在 SOSP 发表,这篇有历史意义的论文直接引爆了 NoSQL 运动,让大家觉得原来数据库还能这么搞。
Dynamo 对外主打的特点是水平扩展能力和通过多副本实现(3副本)的高可用,另外在 API 的设计上可以支持最终一致性读取和强一致性读取,最终一致性读取能提升读的吞吐量。
但是请注意,DynamoDB 虽然有强一致读,但是这里的强一致性并不是传统我们在数据库里说的 ACID 的 C,而且由于没有时序的概念(只有 vector clock),对于冲突的处理只能交给客户端,Dynamo 并不支持事务。不过对于一些特定的业务场景来说,扩展能力和可用性是最重要的,不仅仅是容量,还有集群的吞吐。
阿里云 DRDS
但是那些 RDS 用户的数据量也是在持续增长的,对于云服务提供商来说不能眼睁睁的看着这些 RDS 用户数据量一大就走掉或者自己维护数据库集群。因为也不是谁都能彻底重构代码到 NoSQL 之上,并且分库分表其实对于业务开发者来说是一个很痛苦的事情,在痛苦中往往是蕴含着商业机会的。
比如对于 RDS 的扩展方案,我介绍两个比较典型的:第一个是阿里云的 DRDS (不过现在好像从阿里云的产品列表里拿掉了?),DRDS 其实思路很简单,就是比 RDS 多一小步,在刚才提到的 RDS 的中间层中加入用户配置的路由策略,比如用户可以指定某个表的某些列作为 sharding key 根据一定规则路由到特定的实例,也可以垂直的配置分库的策略。
其实 DRDS 的前身就是淘宝的 TDDL,只不过原来 TDDL 是做在 JDBC 层,现在将 TDDL 做进了 Proxy 层(有点像把 TDDL 塞到 Cobar 的感觉)。这样的好处是,将应用层分库分表的工作封装起来了,但是本质上仍然是一个中间件的方案,尽管能对简单的业务做到一定程度的 SQL 兼容。
对于一些复杂查询,多维度查询,跨 Shard 事务支持都是有限了。毕竟中间路由层对 SQL 的理解有限,至于更换 Sharding key 、DDL、备份也是很麻烦的事情。从 Youtube 开源的中间件 Vitess 的实现和复杂程度来看甚至并不比实现一个数据库简单,但是兼容性却并没有重新写一个数据库来得好。
Amazon Aurora
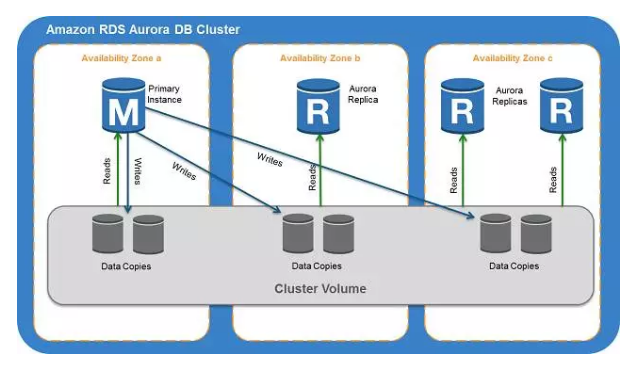
后来时间来到了 2015 年,Amazon 走了另外一条路。在 2015 年,Amazon Aurora 发布。Aurora 的资料在公网上并不多,Aurora 提供了 5x 于单机 MySQL 5.6 的读吞吐能力,不过最大也就扩展到 15 个副本,副本越多对写吞吐影响越大,因为只有一个 Primary Instance 能提供写入服务,单个副本最大支持容量 64T,而且支持高可用以及弹性的扩展。
值得一提的是 Aurora 的兼容性。其实做数据库的都知道,兼容性是一个很难解决的问题,可能实现上很小的差异就会让用户的迁移成本变得很大,这也是为什么中间件和分库分表的方案如此反人类的原因,我们大多都在追求用户平滑的迁移体验。
Aurora 另辟蹊径,由于公开的资料不多,我猜想 Aurora 在 MySQL 前端之下实现了一个基于 InnoDB 的分布式共享存储层(https://www.percona.com/blog/2015/11/16/amazon-aurora-looking-deeper/)。对于读实例来说是很好水平扩展的,这样就将 workload 均摊在前端的各个 MySQL 实例上,有点类似 Oracle RAC 那样的 Share everything 的架构。
这个架构的好处相对中间件的方案很明显,兼容性更强,因为还是复用了 MySQL 的 SQL 解析器。优化器,业务层即使有复杂查询也没关系,因为连接的就是 MySQL。
但是也正是由于这个原因,在节点更多,数据量更大的情况下,查询并不能利用集群的计算能力(对于很多复杂查询来说,瓶颈出现在 CPU 上),而且 MySQL 的 SQL 优化器能力一直是 MySQL 的弱项,而且对于大数据量的查询的 SQL 引擎的设计是和单机有天壤之别的。一个简单的例子,分布式 Query Engine 比如 SparkSQL / Presto / Impala 的设计肯定和单机的 SQL 优化器完全不同,更像是一个分布式计算框架。
所以我认为 Aurora 是一个在数据量不太大的情况下(有容量上限),对简单查询的读性能优化的方案,另外兼容性比中间件的方案好得多。但是缺点是对于大数据量,复杂查询的支持还是比较弱,另外对于写入性能 Aurora 其实没有做太多优化(单点写入),如果写入上出现瓶颈,仍然需要在业务层做水平或者竖直拆分。

时间:2018-10-09 22:57 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















