Apache Beam:下一代的数据处理标准
本文主要介绍Apache Beam的编程范式——Beam Model,以及通过Beam SDK如何方便灵活地编写分布式数据处理业务逻辑,希望读者能够通过本文对Apache Beam有初步了解,同时对于分布式数据处理系统如何处理乱序无限数据流的能力有初步认识。
Apache Beam相关文章:
Apache Beam成功孵化为Apache顶级项目:将统一大数据平台的开发
谷歌布局大数据:开源平台 Apache Beam 正式发布
大数据统一的批处理和流处理标准 Apache Beam
Apache Beam基本架构
随着分布式数据处理不断发展,业界涌现出越来越多的分布式数据处理框架,从最早的Hadoop MapReduce,到Apache Spark、Apache Storm、以及更近的Apache Flink、Apache Apex等。新的分布式处理框架可能带来更高性能,更强大功能,更低延迟等,但用户切换到新分布式处理框架的代价也非常大:需要学习一个新的数据处理框架,并重写所有业务逻辑。
解决这个问题的思路包括两部分:
首先,需要一个编程范式,能够统一规范分布式数据处理的需求,例如统一批处理和流处理的需求。
其次,生成的分布式数据处理任务应该能够在各个分布式引擎上执行,用户可以自由切换执行引擎与执行环境。
Apache Beam正是为了解决以上问题而提出的。它主要由Beam SDK和Beam Runner组成,Beam SDK定义了开发分布式数据处理任务业务逻辑的API接口,生成的的分布式数据处理任务Pipeline交给具体的Beam Runner执行引擎。Apache Beam目前支持的API接口由Java语言实现,Python版本的API正在开发之中。它支持的底层执行引擎包括Apache Flink、Apache Spark以及Google Cloud Platform,此外Apache Storm、Apache Hadoop、Apache Gearpump等执行引擎的支持也在讨论或开发中。其基本架构如图1。
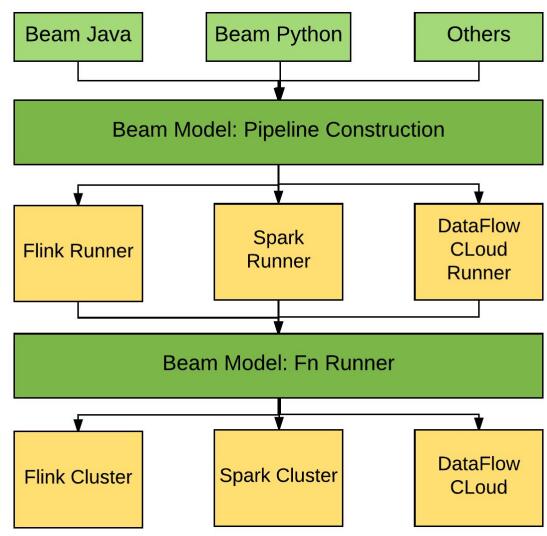
图1 Apache Beam架构图
需要注意的是,虽然Apache Beam社区非常希望所有的Beam执行引擎都能够支持Beam SDK定义的功能全集,但在实际实现中可能并不一定。例如,基于MapReduce的Runner显然很难实现和流处理相关的功能特性。目前Google DataFlow Cloud是对Beam SDK功能集支持最全面的执行引擎,在开源执行引擎中,支持最全面的则是Apache Flink。
Beam Model
Beam Model指Beam的编程范式,即Beam SDK背后的设计思想。在介绍Beam Model前,先介绍下Beam Model要处理的问题域与基本概念。
数据。要处理的数据一般可以分为两类,有限的数据集和无限的数据流。对于前者,比如一个HDFS中的文件,一个HBase表等,特点是数据提前已经存在,一般也已经持久化,不会突然消失。而无限的数据流,比如Kafka中流过来的系统日志流,或是从Twitter API拿到的Twitter流等,这类数据的特点是动态流入,无穷无尽,无法全部持久化。一般来说,批处理框架的设计目标是用来处理有限的数据集,流处理框架的设计目标是用来处理无限的数据流。有限的数据集可以看做无限数据流的一种特例,但是从数据处理逻辑角度,这两者并无不同之处。例如,假设微博数据包含时间戳和转发量,用户希望按照每小时的转发量统计总和,此业务逻辑应该可以同时在有限数据集和无限数据流上执行,并不应该因为数据源的不同而对业务逻辑的实现产生任何影响。
时间。Process Time是指数据进入分布式处理框架的时间,而Event-Time则是指数据产生的时间。这两个时间通常是不同的,例如,对于一个处理微博数据的流计算任务,一条2016-06-01-12:00:00发表的微博经过网络传输等延迟可能在2016-06-01-12:01:30才进入到流处理系统中。批处理任务通常进行全量的数据计算,较少关注数据的时间属性,但是对于流处理任务来说,由于数据流是无穷无尽的,无法进行全量计算,通常是对某个窗口中的数据进行计算。对于大部分的流处理任务来说,按照时间进行窗口划分,可能是最常见的需求。
乱序。对于流处理框架的数据流来说,其数据的到达顺序可能并不严格按照Event-Time的时间顺序。如果基于Process Time定义时间窗口,数据到达的顺序就是数据的顺序,因此不存在乱序问题。但对于基于Event Time定义的时间窗口来说,可能存在时间靠前的消息在时间靠后的消息后到达的情况,这在分布式的数据源中可能非常常见。对于这种情况,如何确定迟到数据,以及对于迟到数据如何处理通常是很棘手的问题。
Beam Model处理的目标数据是无限的时间乱序数据流,不考虑时间顺序或是有限的数据集可看做是无限乱序数据流的一个特例。Beam Model从下面四个维度归纳了用户在进行数据处理的时候需要考虑的问题:
What。如何对数据进行计算?例如,Sum、Join或是机器学习中训练学习模型等。在Beam SDK中由Pipeline中的操作符指定。
Where。数据在什么范围中计算?例如,基于Process-Time的时间窗口,基于Event-Time的时间窗口、滑动窗口等。在BeamSDK中由Pipeline中的窗口指定。
When。何时将计算结果输出?例如,在1小时的Event-Time时间窗口中,每隔1分钟,将当前窗口计算结果输出。在Beam SDK中由Pipeline中的Watermark和触发器指定。
How。迟到数据如何处理?例如,将迟到数据计算增量结果输出,或是将迟到数据计算结果和窗口内数据计算结果合并成全量结果输出。在Beam SDK中由Accumulation指定。
Beam Model将“WWWH”四个维度抽象出来组成了Beam SDK,用户在基于它构建数据处理业务逻辑时,在每一步只需要根据业务需求按照这四个维度调用具体的API即可生成分布式数据处理Pipeline,并提交到具体执行引擎上。“WWWH”四个维度的抽象仅关注业务逻辑本身,和分布式任务如何执行没有任何关系。
Beam SDK
不同于Apache Flink或是Apache Spark,Beam SDK使用同一套API表示数据源、输出目标以及操作符等。下面介绍4个基于Beam SDK的数据处理任务,通过它们,读者可以了解Beam Model是如何统一灵活地描述批处理和流处理任务的,这3个任务用来处理手机游戏领域的统计需求,包括:
用户分数:批处理任务,基于有限数据集统计用户分数。
每小时团队分数:批处理任务,基于有限数据集统计每小时,每个团队的分数。
排行榜:流处理任务,2个统计项,每小时每个团队的分数以及用户实时的历史总得分数。
下面基于Beam Model的“WWWH”四个维度,分析业务逻辑,并通过代码展示如何通过BeamSDK实现“WWWH”四个维度的业务逻辑。
用户分数
统计每个用户的历史总得分数是一个非常简单的任务,在这里我们简单地通过一个批处理任务实现,每次需要新的用户分数数据,重新执行一次这个批处理任务即可。对于用户分数任务,“WWWH”四维度分析结果如下:
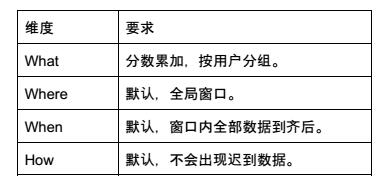
通过“WWWH”的分析,对于用户分数这个批处理任务,通过Beam Java SDK实现的代码如下所示:
gameEvents
[... input ...]
[... parse ...]
.apply("ExtractUserScore", new ExtractAndSumScore("user"))
[... output ...];\
ExtractAndSumScore实现了“What”中描述的逻辑,即按用户分组然后累加分数,其代码如下:
gameInfo
.apply(MapElements
. via((GameActionInfo gInfo) -> KV. of(gInfo.getKey( field ), gInfo.getScore()))
.withOutputType(
TypeDescriptors. kvs(TypeDescriptors. strings(), TypeDescriptors. integers())))
.apply(Sum.
通过MapElements确定Key与Value分别是用户与分数,然后Sum定义按key分组,并累加分数。Beam支持将多个对数据的操作合并成一个操作,这样不仅可以支持更清晰的业务逻辑实现,同时也可以在多处重用合并后的操作逻辑。
每小时团队分数
按照小时统计每个团队的分数,获得最高分数的团队可能获得奖励,这个分析任务增加了对窗口的要求,不过我们依然可以通过一个批处理任务实现,该任务的“WWWH”四维度分析如下:
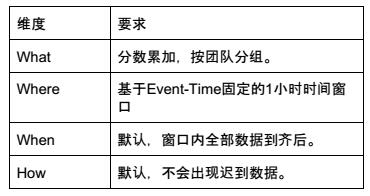
相对于第一个用户分数任务,只是在Where部分回答了“数据在什么范围中计算?”的问题,同时在What部分“如何计算数据?”中,分组的条件由用户改为了团队,这在代码中也会相应体现:
gameEvents
[... input ...]
[... parse ...]
.apply("AddEventTimestamps", WithTimestamps.of((GameActionInfo i)
-> new Instant(i.getTimestamp())))
.apply("FixedWindowsTeam", Window.
FixedWindows.of(Duration.standardMinutes(windowDuration))))
.apply("ExtractTeamScore", new ExtractAndSumScore("team"))
[... output ...];
“AddEventTimestamps”定义了如何从原始数据中抽取EventTime数据,“FixedWindowsTeam”则定义了1小时固定窗口,然后重用了ExtractAndSumScore类,只是将分组的列从用户改成了团队。对于每小时团队分数任务,引入了关于“Where”部分窗口定义的新业务逻辑,但是从代码中可以看到,关于“Where”部分的实现和关于“What”部分的实现是完全独立的,用户只需要新加两行关于“Where”的代码,非常简单和清晰。
排行榜
前面两个任务均是基于有限数据集的批处理任务,对于排行榜来说,我们同样需要统计用户分数以及每小时团队分数,但是从业务角度希望得到的是实时数据。对于Apache Beam来说,一个相同处理逻辑的批处理任务和流处理任务的唯一不同就是任务的输入和输出,中间的业务逻辑Pipeline无需任何改变。对于当前示例的排行榜数据分析任务,我们不仅希望他们满足和前两个示例相同的业务逻辑,同时也可以满足更定制化的业务需求,例如:
流处理任务相对于批处理任务,一个非常重要的特性是,流处理任务可以更加实时地返回计算结果,例如计算每小时团队分数时,对于一小时的时间窗口,默认是在一小时的数据全部到达后,把最终的计算结果输出,但是流处理系统应该同时支持在一小时窗口只有部分数据到达时,就将部分计算结果输出,从而使得用户可以得到实时的分析结果。
保证和批处理任务一致的计算结果正确性。由于乱序数据的存在,对于某一个计算窗口,如何确定所有数据是否到达(Watermark)?迟到数据如何处理?处理结果如何输出、总量、增量、并列?流处理系统应该提供机制保证用户可以在满足低延迟性能的同时达到最终的计算结果正确性。
上述两个问题正是通过回答“When”和“How”两个问题来定义用户的数据分析需求。“When”取决于用户希望多久得到计算结果,在回答“When”的时候,基本上可以分为四个阶段:
Early。在窗口结束前,确定何时输出中间状态数据。
On-Time。在窗口结束时,输出窗口数据计算结果。由于乱序数据的存在,如何判断窗口结束可能是用户根据额外的知识预估的,且允许在用户设定的窗口结束后出现迟到的属于该窗口的数据。
Late。在窗口结束后,有迟到的数据到达,在这个阶段,何时输出计算结果。
Final。能够容忍迟到的最大限度,例如1小时。到达最后的等待时间后,输出最终的计算结果,同时不再接受之后的迟到数据,清理该窗口的状态数据。
对于每小时团队得分的流处理任务,本示例希望的业务逻辑为,基于Event Time的1小时时间窗口,按团队计算分数,在一小时窗口内,每5分钟输出一次当前的团队分数,对于迟到的数据,每10分钟输出一次当前的团队分数,在窗口结束2小时后迟到的数据一般不可能会出现,假如出现的话,直接抛弃。“WWWH”表达如下:

在基于Beam SDK的实现中,用户基于“WWWH” Beam Model表示的业务逻辑可以独立直接地实现:
gameEvents
[... input ...]
.apply("LeaderboardTeamFixedWindows", Window
.
Duration.standardMinutes(Durations.minutes(60))))
.triggering(AfterWatermark.pastEndOfWindow()
.withEarlyFirings(AfterProcessingTime.pastFirstElementInPane()
.plusDelayOf(Durations.minutes(5)))
.withLateFirings(AfterProcessingTime.pastFirstElementInPane()
.plusDelayOf(Durations.minutes(10))))
.withAllowedLateness(Duration.standardMinutes(120)
.accumulatingFiredPanes())
.apply("ExtractTeamScore", new ExtractAndSumScore("team"))
[... output ...]
LeaderboardTeamFixedWindows对应“Where”定义窗口,Trigger对应“Where”定义结果输出条件,Accumulation对应“How”定义输出结果内容,ExtractTeamScore对应“What”定义计算逻辑。
总结
Apache Beam的Beam Model对无限乱序数据流的数据处理进行了非常优雅的抽象,“WWWH”四个维度对数据处理的描述,十分清晰与合理,Beam Model在统一了对无限数据流和有限数据集的处理模式的同时,也明确了对无限数据流的数据处理方式的编程范式,扩大了流处理系统可应用的业务范围。Apache Flink、Apache Spark Streaming等项目的API设计均越来越多地借鉴或参考了Apache Beam Model,且作为Beam Runner的实现,与Beam SDK的兼容度也越来越高。此外,由于Apache Beam已经进入Apache Incubator孵化,读者也可以通过官网或是邮件组了解更多Apache Beam的进展和状态。
美国时间1月10日,Apache软件基金会对外宣布,万众期待的 Apache Beam 在经历了近一年的孵化之后终于毕业。这一顶级 Apache开源项目终于成熟。

时间:2018-10-09 22:55 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















