Apache Beam成功孵化为Apache顶级项目:将统一大数据
1 月 10 日,Apache 软件基金会宣布,Apache Beam 成功孵化,成为该基金会的一个新的顶级项目。
Apache Beam 在2016年1月发布第一个版本,由 Google 捐献给开源社区,凝聚着 Google 研发大数据基础设施的多年经验。
Beam 来源于 Batch(批处理)和 strEAM (流处理)这两个词,意在提供一个统一的编程模型,同时支持批处理和流处理。
Apache Beam 是:
统一的:使用一个编程模型支持批处理和流处理用例。
可移植的:可以在多种执行引擎上执行作业,包括 Apache Apex、Apache Flink、Apache Spark 和 Google Cloud Dataflow 等。可扩展的:支持编写和共享新的 SDK、IO connector 和 transformation 库。
大数据框架有很多:Hadoop, Spark等;对于流数据的处理存在很多技术:简单的事件处理器,流处理器和复杂的事件处理器。在开源社区中存在很多选择,包括Flume,NiFi,Apex,Kafka流,Spark流,Storm,Flink,Samza,Ignite和Beam。
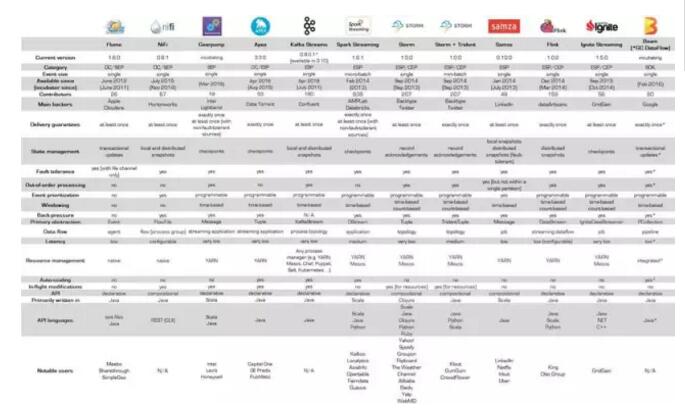
各个平台之间也是互不兼容的,一个平台上写的程序很难移植到另外一个平台,这对开发者来说开发成本比较高。这就催生了Google的新项目Apache Beam,是Google想对大数据开源生态进行的一次大一统。
Google是最早实践大数据的公司,目前大数据的生态很大一部分都要归功于Google最早的几篇论文,这几篇论文造就了目前以Hadoop为开端的大数据繁荣生态。Apache Beam被认为是继MapReduce,GFS和BigQuery等之后,Google在大数据处理领域对开源社区的又一个非常大的贡献。并且由Google开源后,得到了Spark, Flink等社区的大力支持。
Apache Beam的发展历程:
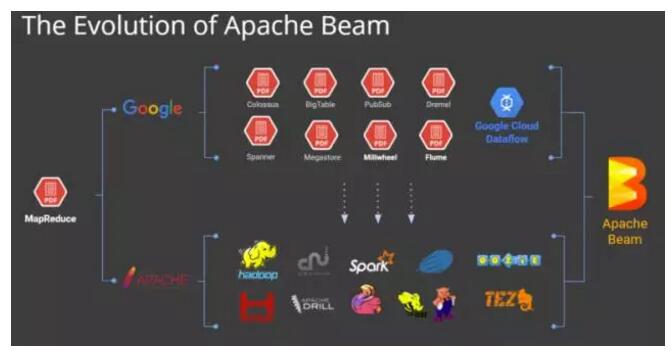
Beam本身不是一个流式处理平台,而是一个统一的编程框架。“Beam可用于各种流式或批处理上,包括ETL,流分析和聚合计算”。解决这个问题的思路包括两个部分:第一,需要一个编程范式,能够统一、规范分布式数据处理的需求。第二,生成的分布式数据处理任务应该能够在各个分布式执行引擎上执行,用户可以自由切换分布式数据处理任务的执行引擎与执行环境。
在Beam中,主要包含两个关键的部分(以下部分引用了解读2016之大数据篇):
Beam SDK
Beam SDK提供一个统一的编程接口给到上层应用的开发者,开发者不需要了解底层的具体的大数据平台的开发接口是什么,直接通过Beam SDK的接口,就可以开发数据处理的加工流程。Beam SDK会有不同的语言的实现,目前提供Java,python的SDK正在开发过程中,相信未来会有更的的不同的语言的SDK会发布出来。
Beam Pipeline Runner
Beam Pipeline Runner是将用户开发的pipeline翻译成底层的数据平台支持的运行时环境的一层。针对不同的大数据平台,会有不同的Runner。目前Flink, Spark, Apex以及google的 Cloud DataFlow都有支持Beam的Runner。
“Beam已经足够的成熟和稳定,Spotify公司就在用Beam构造自己的大数据pipeline。”
Beam的架构图:

Apache Beam的代码大部分来自于谷歌 Cloud Dataflow SDK,Google内部已经用Dataflow替换掉了MapReduce,“No one at Google uses MapReduce anymore - Cloud Dataflow explained for dummies ”:
另外我们可以看下Google内部怎么使用Apache Beam的:

参考资料:https://www.datanami.com/2016/04/22/apache-beam-emerges-ambitious-goal-unify-big-data-development/

时间:2018-10-09 22:55 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















