Spark的调度策略详解
Spark的调度策略
Spark目前有两种调度策略,一种是FIFO即先来先得,另一种是FAIR即公平策略。所谓的调度策略就是对待调度的对象进行排序,按照优先级来进行调度。调度的排序接口如下所示,就是对两个可调度的对象进行比较。

其实现类为FIFOSchedulingAlgorithm、FairSchedulingAlgorithm
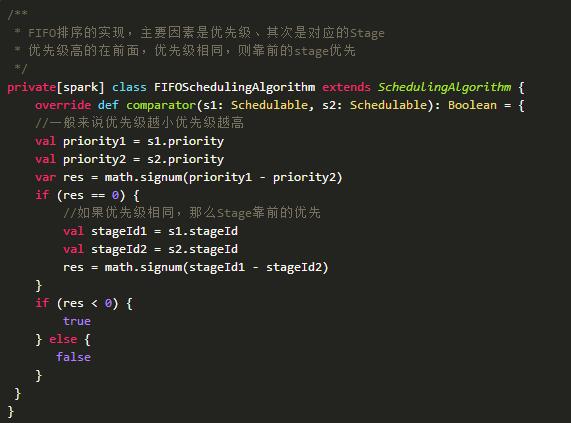
注:可以根据自己对优先级的定义重写这个比较方法,但有一点注意,就是如果优先级和Stage都相同,那么默认后来居上

注:
公平原则本着的原则就是谁最需要就给谁,所以挨饿者优先;
资源占用比这块有点费解,如果把他理解成一个贪心问题就容易理解了。对于都是出于挨饿状态的任务可以这样理解,负载大的即时给你资源你也不一定能有效缓解,莫不如给负载小的,让其快速使用,完成后可以释放更多的资源,这是一种贪心策略。如JobA和JobB的Task数量相同都是10,A的minShare是2,B的是5,那占用比为5和2,显然B的占用比更小,贪心的策略应该给B先调度处理;
对于都处于满足状态的,当然谁的权重有着更好的决定性,权重比低得优先(偏向权利大的);
如果所有上述的比较都相同,那么名字字典排序靠前的优先(哈哈,名字很重要哦);名字aaa要比abc优先,所以这里在给Pool或者TaskSetManager起名字的时候要考虑这一点。
这两种调度的排序算法针对的可比较对象都是Schedule的具体对象,其(trait可理解成java中接口)定义如下:
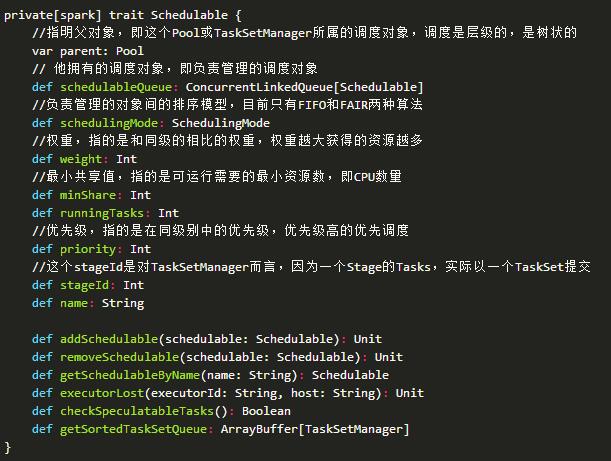
目前Spark中有两种可调度的实体,Pool和TaskSetManager。Pool是一个调度池,Pool里面还可以有子Pool,Spark中的rootPool即根节点默认是一个无名的Pool。
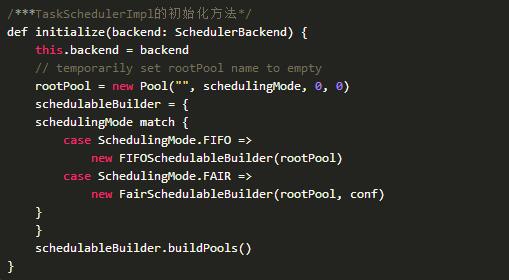
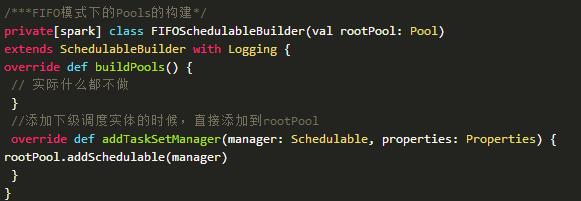
其实对于FIFO模式的调度,rootPool管理的直接就是TaskSetManager,没有子Pool这个概念,就只有两层,rootPool和叶子节点TaskSetManager,实现如下所示。
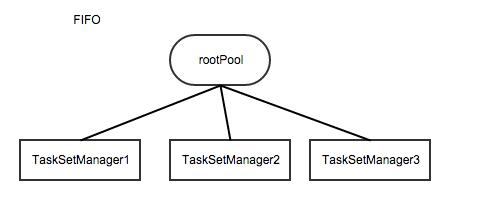
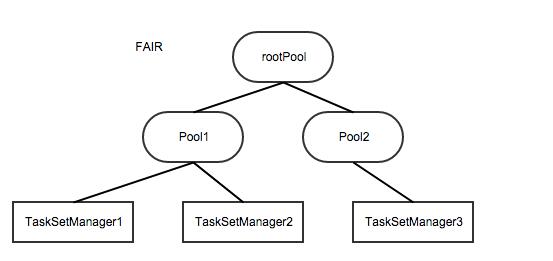
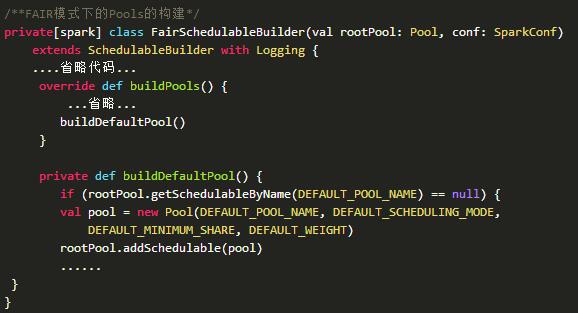
但对于FAIR这种模式来说,是三层的,根节点是rootPool,为无名Pool,下一层为用户定义的Pool(不指定名称默认名称为default),再下一层才是TaskSetManager,即根调度池管理一组调度池,每个调度池管理自己的TaskSetManager,其实现如下所示。
这里的调度顺序是指在一个SparkContext之内的调度,一般情况下我们自行使用是不太会需要Pool这个概念的,因为不存在Pool之间的竞争,但如果我们提供一个Spark应用,大家都可以提交任务,服务端有一个常驻的任务,对应一个SparkContext,每个用户提交的任务都由其代理执行,那么针对每个用户提交的任务可以按照用户等级和任务优先级设置一个Pool,这样不同的用户的Pool之间就存在竞争关系了,可以用Pool的优先级来区分任务和用户的优先级了,**但要再强调一点名字很重要,因为FAIR机制中,如果其他比较无法判断,那么会按照名字来进行字典排序的**。

时间:2018-10-10 22:33 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















