深度学习利器:TensorFlow实战
深度学习及TensorFlow简介
深度学习目前已经被应用到图像识别,语音识别,自然语言处理,机器翻译等场景并取得了很好的行业应用效果。至今已有数种深度学习框架,如TensorFlow、Caffe、Theano、Torch、MXNet,这些框架都能够支持深度神经网络、卷积神经网络、深度信念网络和递归神经网络等模型。TensorFlow最初由Google Brain团队的研究员和工程师研发,目前已成为GitHub上最受欢迎的机器学习项目。
TensorFlow开源一周年以来,已有500+contributors,以及11000+个commits。目前采用TensorFlow平台,在生产环境下进行深度学习的公司有ARM、Google、UBER、DeepMind、京东等公司。目前谷歌已把TensorFlow应用到很多内部项目,如谷歌语音识别,GMail,谷歌图片搜索等。TensorFlow主要特性有:
使用灵活:TensorFlow是一个灵活的神经网络学习平台,采用图计算模型,支持High-Level的API,支持Python、C++、Go、Java接口。
跨平台:TensorFlow支持CPU和GPU的运算,支持台式机、服务器、移动平台的计算。并从r0.12版本支持Windows平台。
产品化:TensorFlow支持从研究团队快速迁移学习模型到生产团队。实现了研究团队发布模型,生产团队验证模型,构建起了模型研究到生产实践的桥梁。
高性能:TensorFlow中采用了多线程,队列技术以及分布式训练模型,实现了在多CPU、多GPU的环境下分布式训练模型。
本文主要介绍TensorFlow一些关键技术的使用实践,包括TensorFlow变量、TensorFlow应用架构、TensorFlow可视化技术、GPU使用,以及HDFS集成使用。
TensorFlow变量
TensorFlow中的变量在使用前需要被初始化,在模型训练中或训练完成后可以保存或恢复这些变量值。下面介绍如何创建变量,初始化变量,保存变量,恢复变量以及共享变量。
#创建模型的权重及偏置
weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35), name="weights")
biases = tf.Variable(tf.zeros([200]), name="biases")
#指定变量所在设备为CPU:0
with tf.device("/cpu:0"):
v = tf.Variable(...)
#初始化模型变量
init_op = tf.global_variables_initializer()
sess=tf.Session()
sess.run(init_op)
#保存模型变量,由三个文件组成model.data,model.index,model.meta
saver = tf.train.Saver()
saver.restore(sess, "/tmp/model")
#恢复模型变量
saver.restore(sess, "/tmp/model")
在复杂的深度学习模型中,存在大量的模型变量,并且期望能够一次性地初始化这些变量。TensorFlow提供了tf.variable_scope和tf.get_variable两个API,实现了共享模型变量。tf.get_variable(
#定义卷积神经网络运算规则,其中weights和biases为共享变量
def conv_relu(input, kernel_shape, bias_shape):
# 创建变量"weights".
weights = tf.get_variable("weights", kernel_shape, initializer=tf.random_normal_initializer())
# 创建变量 "biases".
biases = tf.get_variable("biases", bias_shape, initializer=tf.constant_initializer(0.0))
conv = tf.nn.conv2d(input, weights, strides=[1, 1, 1, 1], padding='SAME')
return tf.nn.relu(conv + biases)
#定义卷积层,conv1和conv2为变量命名空间
with tf.variable_scope("conv1"):
# 创建变量 "conv1/weights", "conv1/biases".
relu1 = conv_relu(input_images, [5, 5, 32, 32], [32])
with tf.variable_scope("conv2"):
# 创建变量 "conv2/weights", "conv2/biases".
relu1 = conv_relu(relu1, [5, 5, 32, 32], [32])
TensorFlow应用架构
TensorFlow的应用架构主要包括模型构建,模型训练,及模型评估三个方面。模型构建主要指构建深度学习神经网络,模型训练主要指在TensorFlow会话中对训练数据执行神经网络运算,模型评估主要指根据测试数据评估模型精确度。如下图所示:
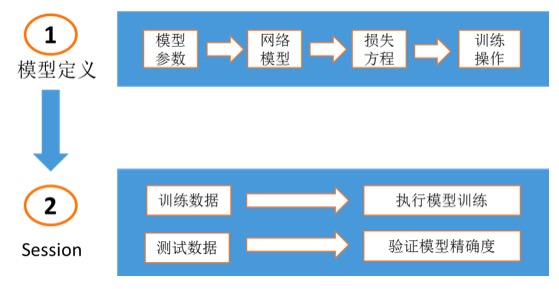
网络模型,损失方程,模型训练操作定义示例如下:
#两个隐藏层,一个logits输出层
hidden1 = tf.nn.relu(tf.matmul(images, weights) + biases)
hidden2 = tf.nn.relu(tf.matmul(hidden1, weights) + biases)
logits = tf.matmul(hidden2, weights) + biases
#损失方程,采用softmax交叉熵算法
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits( logits, labels, name='xentropy')
loss = tf.reduce_mean(cross_entropy, name='xentropy_mean')
#选定优化算法及定义训练操作
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
global_step = tf.Variable(0, name='global_step', trainable=False)
train_op = optimizer.minimize(loss, global_step=global_step)
模型训练及模型验证示例如下:
#加载训练数据,并执行网络训练
for step in xrange(FLAGS.max_steps):
feed_dict = fill_feed_dict(data_sets.train, images_placeholder, labels_placeholder)
_, loss_value = sess.run([train_op, loss], feed_dict=feed_dict)
#加载测试数据,计算模型精确度
for step in xrange(steps_per_epoch):
feed_dict = fill_feed_dict(data_set, images_placeholder, labels_placeholder)
true_count += sess.run(eval_correct, feed_dict=feed_dict)

时间:2018-10-10 22:32 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]吴恩达deeplearning.ai新课上线:TensorFlow移动和web端
- [数据挖掘]2020职场AI技能排行榜:TensorFlow热度飙升,Python最
- [数据挖掘]TensorFlow 2.0中文开源书项目:日赞700,登上GitHu
- [数据挖掘]18个月自学AI,2年写就三万字长文,过来人教你如
- [数据挖掘]Tensorflow 2.0 到底好在哪里?
- [数据挖掘]编程进阶之路:用简单的面向对象编程提升深度
- [数据挖掘]TensorFlow 等“开源陷阱",会掐住中国 AI 企业
- [数据挖掘]终版API已定型,TensorFlow 2.0 Beta蜕变归来
- [数据挖掘]TensorFlow什么的都弱爆了,强者只用Numpy搭建神经
- [数据挖掘]2019年最好的5个数据科学GitHub项目和Reddit讨论
相关推荐:
网友评论:















