干货|Kafka在大数据环境中的应用
场景一:我们开发过一个设备信息挖掘平台。这个平台需要实时将采集互联网关采集到的路由节点的状态信息存入数据中心。通常一个网关一次需要上报几十甚至几百个变化的路由信息。全区有几万个这种互联网关。当信息采集平台将这些变化的数据信息写入或更新到数据库时候,会给数据库代理非常大的压力,甚至可以直接将数据库搞挂掉。这就对我们的数据采集系统提出了很高的要求。如何稳定高效地把消息更新到数据库这一要求摆了出来。
场景二:数据中心处理过的数据需要实时共享给几个不同的机构。我们常采用的方法是将数据批量存放在数据采集机,分支机构定时来采集;或是分支机构通过JDBC、RPC、http或其他机制实时从数据中心获取数据。这两种方式都存在一定的问题,前者在于实时性不足,还牵涉到数据完整性问题;后者在于,当数据量很大的时候,多个分支机构同时读取数据,会对数据中心的造成很大的压力,也造成很大的资源浪费。
为了解决以上场景提出的问题,我们需要这样一个消息系统:
缓冲能力,系统可以提供一个缓冲区,当有大量数据来临时,系统可以将数据可靠的缓冲起来,供后续模块处理;
订阅、分发能力,系统可以接收消息可靠的缓存下来,也可以将可靠缓存的数据发布给使用者。
这就要我们找一个高吞吐的、能满足订阅发布需求的系统。
Kafka是一个分布式的、高吞吐的、基于发布/订阅的消息系统。利用kafka技术可以在廉价PC Server上搭建起大规模的消息系统。Kafka具有消息持久化、高吞吐、分布式、实时、低耦合、多客户端支持、数据可靠等诸多特点,适合在线和离线的消息处理。
使用kafka解决我们上述提到的问题。
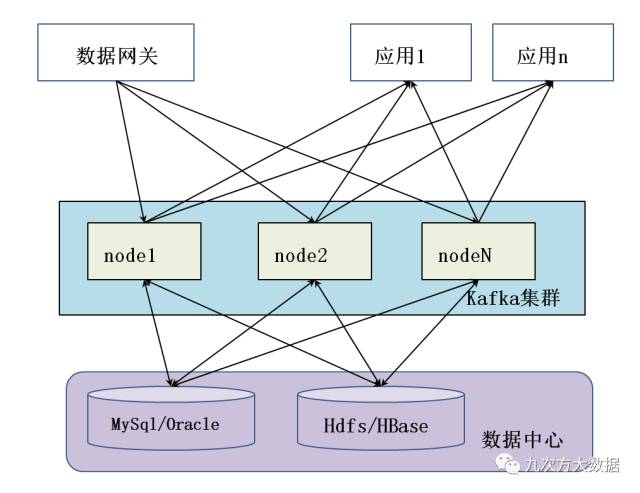
互联网关采集到变化的路由信息,通过kafka的producer将归集后的信息批量传入kafka。Kafka按照接收顺序对归集的信息进行缓存,并加入待消费队列。Kafka的consumer读取队列信息,并一定的处理策略,将获取的信息更新到数据库。完成数据到数据中心的存储。
数据中心的数据需要共享时,kafka的producer先从数据中心读取数据,然后传入kafka缓存并加入待消费队列。各分支结构作为数据消费者,启动消费动作,从kafka队列读取数据,并对获取的数据进行处理。
Kafka生产的代码如下:
public void produce(){
//生产消息预处理
produceInfoProcess();
pro.send(ProducerRecord,new Callback(){
@Override
onCompletion() {
if (metadata == null) {
// 发送失败
failedSend();
} else {
//发送成功!"
successedSend();
}
}
});
}
消息生产者根据需求,灵活定义produceInfoProcess()方法,对相关数据进行处理。并依据数据发布到kafka的情况,处理回调机制。在数据发送失败时,定义failedSend()方法;当数据发送成功时,定义successedSend()方法。
Kafka消费的代码如下:
public void consumer() {
//配置文件
properties();
//获取当前数据的迭代器
iterator = stream.iterator();
while (iterator.hasNext()) {
//取出消息
MessageAndMetadata<byte[], byte[]> next = iterator.next();
messageProcess();
}
}
Kafka消费者会和kafka集群建立一个连接。从kafka读取数据,调用messageProcess()方法,对获取的数据灵活处理。
结论
Kafka的高吞吐能力、缓存机制能有效的解决高峰流量冲击问题。实践表明,在未将kafka引入系统前,当互联网关发送的数据量较大时,往往会挂起关系数据库,数据常常丢失。在引入kafka后,更新程序能够结合能力自主处理消息,不会引起数据丢失,关系型数据库的压力波动不会发生过于显著的变化,不会出现数据库挂起锁死现象。
依靠kafka的订阅分发机制,实现了一次发布,各分支依据需求自主订阅的功能。避免了各分支机构直接向数据中心请求数据,或者数据中心依次批量向分支机构传输数据以致实时性不足的情况。kafka提高了实时性,减轻了数据中心的压力,提高了效率。

时间:2018-10-09 22:52 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















