全栈必备 面向数据的架构
数据是系统的核心,在面向服务的架构之外,可以考虑面向数据的架构方式。面向数据的服务架构需要支持多数据源异构,支持动态数据和静态数据,既支持公有云部署又支持私有云部署,提供多种数据应用和数据产品,如下图所示:
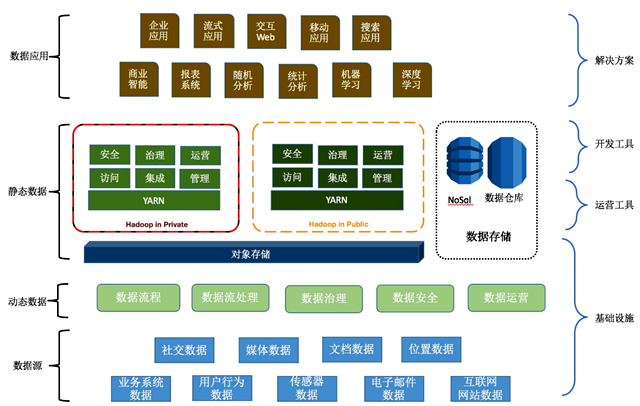
一般地,为了不影响业务系统的正常运行,会将不同数据源汇集起来,技术的采集与摄取,然后进行数据的存储及一系列的操作处理, 最终通过各种的解决方案形成数据应用衍生的数据产品。
从开发的角度看,可以分成基础设施,运营工具,开发工具和解决方案四层,从数据自身来看,也可以分为数据源,动态数据,静态数据和数据应用4个层次,相互是有交叠的。
数据源
数据源决定了数据的宽度, 数量量决定了数据的厚度。即使是做数据应用,也是和具体的业务领域相关的,数据的价值不是凭空出现的。所以, 业务系统的数据是第一位的,也是最容易获得,直接的价值也较高。
其次是用户的行为数据,经管用户经受了产品本身的诱导和局限,但用户的行为数据还是在一定程度上体现的用户便好。 过去的可用性测试甚至形成了可用性工程,而今,一般都会通过用户的行为数据来检验用户体验。
物联网(IOT)的到来,凸显了传感器数据的重要性。传感器数据是相对高频的数据,与时间序列相关,可以考虑与时间相关的数据存储,以及数据的迁移。位置数据可以看作是一种特殊的传感器数据,通过位置数据可以得到物理上空间位置的描述,是一种非常有用的数据,尤其对移动互联网应用而言。
社交几乎也是无处不在的(anything can be social),通过社交属性的功能,可以使应用拥有一定的社会属性,从而具备更多的价值。电子邮件可能是比较古老的互联网应用了,可以看作是一种特殊的社交数据,数据采集可以通过标准的POP3/IMAP4协议实现,应用内的社交数据需要自己整理,对于第三方的社交平台,一般都是提供API 接口服务的,只要注意以来访问控制即可。
媒体的范围较大,针对性的获取数据需要爬虫的相关技术,数字化媒体的各种限制对爬虫而言是一个挑战。相对而言,社交媒体和自媒体通用访问接口的获取想对容易一些。
不论是客户的网站还是竞品的网站,同样需要爬虫技术的帮助,这些数据将对业务系统的数据形成有益的补充。
文档数据大多是非结构化数据,一般是文件系统和NoSQL 的胜场。对于很多企业而言,往往纸质文档数据化的过程,随着AI技术的发展,尤其是OCR 相关技术的逐渐成熟,所有文档都是数据资源。
动态数据
动态数据的采集过程与静态数据是类似的,关键在于分析流程,对于动态数据而言,分析是实事发生的。例如游乐园采用手环来采集用户的信息,这些手环中记录了用户的相关行为,游乐园可以使用这些数据为用户个性化推荐一些服务,这使得在用户游览期间的定制化服务成为可能。基于动态数据,在这些场景中使企业和用户之间产生更多的商机成为可能。
对于动态数据,需要采用实时处理方法。时延是需要考量的一个关键因素,时间就是金钱在这里体现的淋漓尽致。 通过减少多租户的资源约束和云服务的使用可以降低时延,提高性能水平,能够实时处理大流量数据.
数据流程相似于传统的ETL流程,在数据提取时同时完成数据的初步转换和清洗,具体流程还是与目标息息相关的。数据流处理是动态数据处理的核心部分,既可以对动态数据进行进一步的清洗然后存储,又可以直接引入分析方法,与后面的流式应用连接起来。
数据治理是指从使用零散数据变为使用统一主数据、从具有很少或没有组织和流程治理到业务范围内的综合数据治理、从尝试处理主数据混乱状况到主数据井井有条的一个过程。数据治理对于确保数据的准确、分享和保护是至关重要的。有效的数据治理通过改进分析算法、缩减存储和计算成本、降低灾备风险和提高安全合规等方式,最终体现数据的价值。
数据安全一是数据本身的安全,主要是指采用加密方法对数据进行主动保护,如数据保密、数据完整性、双向身份认证等,同时也是数据防护的安全,主要是对数据存储进行主动防护,如通过磁盘阵列、数据备份、异地容灾等手段保证数据的安全。数据处理的安全是指如何有效的防止数据在录入、处理、统计中由于硬件故障、人为误操作、程序缺陷、病毒或黑客等造成的数据库损坏或数据丢失现象,某些敏感或保密的数据可能不具备资格的人员阅读,而造成数据泄密等后果。而数据存储的安全是指数据在系统运行之外的可读性。
数据运营是指通过对动态数据的分析挖掘,把隐藏在海量数据中的信息以合规化的形式发布出去,供数据的消费者使用。动态数据的数据运营是一个非常具有挑战性的课题。
静态数据
对于静态数据的操作,更像是一种批处理形式,是一种离线分析,更像是传统的OLAP,这样可以拥有较高性能的处理能力。这意味着先从各种数据源获取数据,然后再进行分析处理。静态数据处理分为了两个阶段,例如一个零售终端分析上个月的数据来决定本月的商业活动, 是否能够根据用户的购买行为来发放定制化的优惠卷等等。
具体的分析计算既可以再私有云上执行,也可以在公有云上执行。对于一定规模数据,尤其是探索性数据分析,一般都可以在私有云进行计算,甚至直接在私有云上提供数据应用和数据产品。当数据规模和计算资源的需求达到一定程度的时候,可以考虑迁移的公有云。这是面向数据的一种混合云结构,为了使迁移简单方便,需要保障环境的一致性,YARN 是资源调度的最佳选择。当然,mesos 同样值得关注。
静态数据的存储一般是海量存储,基于面向读性能提供的迫切需要,NoSQL是必然的选择。当然,面向大量的结构化数据,数据仓库仍然是不错的选择。
数据应用
数据应用包含了计算框架,算法,数据的可视化以及具体的应用呈现。不论是企业应用还是移动应用以及交互式Web应用,都可以使用数据计算得到的结果。流式应用和搜索应用都是与计算框架紧密相关的,可以通过Storm 和ElasticSearch 实现,也可以通过Spark 框架实现。
商业智能(BI),传统上是基于数据仓库的数据挖掘,发现数据中潜在的价值。而在面向数据的架构中,BI的分析方法可以不变,只改变计算的方式,也可以对分析方法进行演讲。
报表系统可以认为是可视化的核心之一。面向静态数据形成传统的报表,动态数据与静态数据相结合形成实时报表。
随机分析是一种探索性数据分析,是一种对数据摸索和尝试,可以使用Hive,pig,sparkSQL等工具执行,明确进一步探索的方向。统计分析是更加具体的一种离线分析,基于统计模型的数据分析处理。
机器学习(Machine Learning, ML)是一门多领域交叉学科,模拟或实现人类的学习行为,以获取新的知识或技能,是人工智能的核心,框架有很多,例如Mahout以及SparkML等。
深度学习是机器学习研究中的一个新领域,源于人工神经网络,含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征。同机器学习方法一样,深度机器学习方法也有监督学习与无监督学习之分.不同的学习框架下建立的学习模型很是不同。
文章来源:36大数据

时间:2018-10-09 22:52 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]每个大数据架构师都需要的6个基本技能
- [数据挖掘]Uber开源Manifold:机器学习可视化调试工具
- [数据挖掘]2020 年数据科学就业市场必备的五项技能
- [数据挖掘]吴恩达deeplearning.ai新课上线:TensorFlow移动和web端
- [数据挖掘]TensorFlow 2.0中文开源书项目:日赞700,登上GitHu
- [数据挖掘]30段极简Python代码:这些小技巧你都Get了么
- [数据挖掘]加快数据科学项目的五个自动化工具
- [数据挖掘]BERT, RoBERTa, DistilBERT, XLNet的用法对比
- [数据挖掘]一个案例告诉你如何使用Kyligence + Spark 进行大数
- [数据挖掘]想留住人才?先要管理好数据科学团队
相关推荐:
网友评论:















