大规模机器学习的编程技术、计算模型以及Xgbo
大规模机器学习的编程技术、计算模型以及Xgboost和MXNet案例
现在,机器学习的趋势从传统方法中的简单模型 + 少量数据(人工标注样本),到简单模型 + 海量数据(比如基于逻辑回归的广告点击率预测),再发展到现在复杂模型 + 海量数据(比如深度学习 ImageNet 图像识别,基于 DNN 的广告点击率预测)。
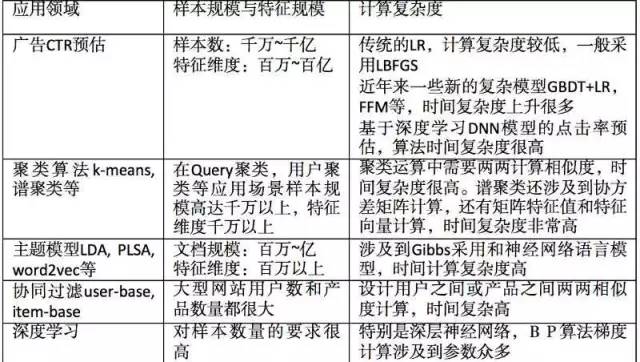
总结下在工业届常会用到的大规模机器学习的场景:
这次分享从这 3 部分展开:
1.并行计算编程技术
向量化
Openmp
GPU
mpi
2.并行计算模型
BSP
SSP
ASP
Parameter Server
3.并行计算案例
Xgboost 的分布式库 Rabit
Mxnet 的分布式库 ps-lite
并行计算编程技术
首选提到并行编程技术,这是大规模机器学习的工程基础。
向量化
向量化计算是一种特殊的并行计算的方式,相比于一般程序在同一时间只执行一个操作的方式,它可以在同一时间执行多次操作,通常是对不同的数据执行同样的一个或一批指令,或者说把指令应用于一个数组 / 向量。
在 X86 体系架构的 CPU 上,主要的向量化编程技术是 SSE 和 AVX。Intel 公司的单指令多数据流式扩展(SSE,Streaming SIMD Extensions)技术能够有效增强 CPU 浮点运算的能力。现住主流的编译器 GCC 和 Visual Studio 提供了对 SSE 指令集的编程支持,从而允许用户在 C++ 代码中不用编写汇编代码就可直接使用 SSE 指令的功能。Intel SSE 指令集支持的处理器有 16 个 128 位的寄存器,每一个寄存器可以存放 4 个(32 位)单精度的浮点数。SSE 同时提供了一个指令集,其中的指令可以允许把浮点数加载到这些 128 位的寄存器之中,这些数就可以在这些寄存器中进行算术逻辑运算,然后把结果放回内存。AVX 与 SSE 类似,AVX 将所有 16 个 128 寄存器扩充为 256 位寄存器,从而支持 256 位的矢量计算,理想状态下,浮点性能 AVX 最高能达到 SSE 的 2 倍水平。移动设备上广泛采用的 ARM 架构,ARM 向量指令 Neon 提供 16 个长度位 128 位的向量寄存器。
简单点说:SSE 指令集的加速比为 4 倍,AVX 可以获取 8 倍加速比。
使用也很简单。
AVX 指令集编程示例:
for(i=0; i
这是一个数组求和的加速例子。
现在主流编译器 GCC 等都支持。
其次是大家最熟悉的多线程编程技术。
UNIX/Linux 中的 pthread, Windows 环境下的 WinThread。但是相对于机器学习并行来说,一方面采用多线程编程技术,开发成本较高,而且需要妥善处理同步互斥等问题;另一方面,不同平台中使用多线程编程库是不一样的,这样也会造成移植性问题。
Openmp
OpenMP 是一个支持共享存储并行设计的库,特别适宜多核 CPU 上的并行程序设计,它使得多线程编程的难度大大降低,是目前机器学习上多线程主流解决方案。

大家可以看看这个例子。我们很容易把传统的 for 循环语句进行加速。OpenMP 也可以实现类似于 MapReduce 的计算范式。更详细的大家可以参考 openmp 的官方文档。
GPU
GPU 编程是目前很热的并行计算方案。
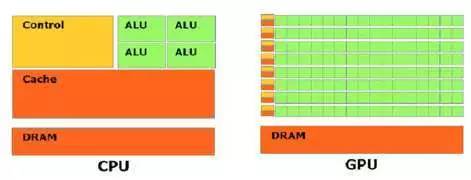
这是 GPU 和 CPU 区别。
为什么 GPU 更快呢?
CPU 主要是为串行指令而优化,而 GPU 是为大规模并行运算而优化。
GPU 相对 CPU 来说,在同样的芯片面积上,拥有更多的计算单元,这也使得 GPU 计算性能更加强大,而 CPU 则拥有更多的缓存和相关的控制部件。
GPU 相对 CPU 来说拥有更高的带宽。
CUDA 是目前主流的 GPU 编程。

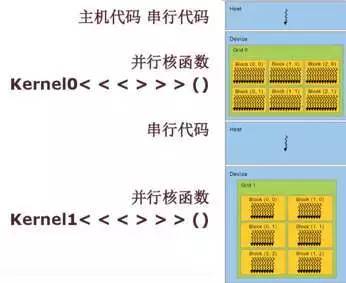
这也是一个数组求和例子。大家可以看看 GPU 编程并不是很难,它和传统程序编程区别是:
MPI
MPI 是一种多机并行解决方案,它的核心是消息的传递和接收,解决多级并行中的通信问题。
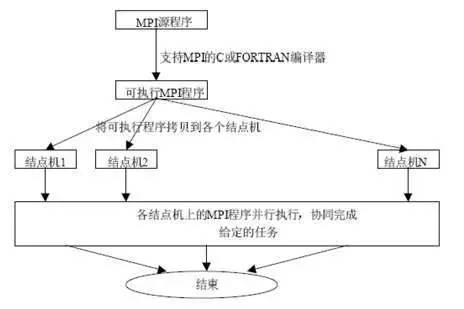
这是 MPI 程序执行流程。MPI 的学习难度也是比较低的。
MPI_Init(…); 初始化环境
MPI_Comm_size(…) 获取进程数
MPI_Comm_rank(…) 获取进程序号
MPI_Send(…) 发送消息
MPI_Recv(…) 接收消息
MPI_Finalize() 并行结束函数
主要是这 6 个函数。
MPI 函数虽然很多,但是功能主要有两大类:
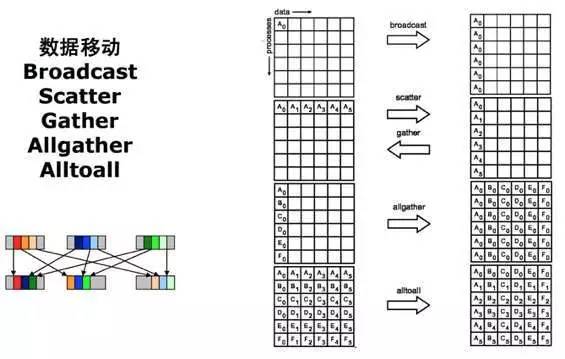
一种是发送数据。
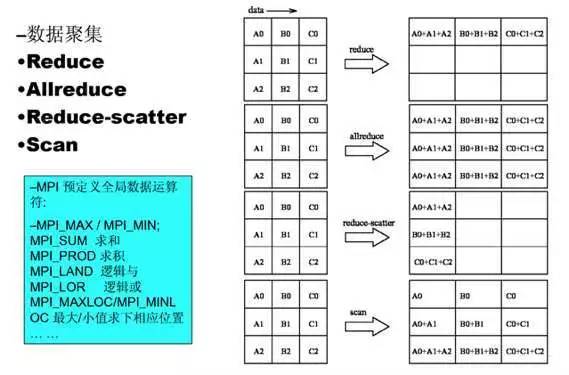
这种是接收数据做规约。很类似于大家常见的 MapReduce 吧。
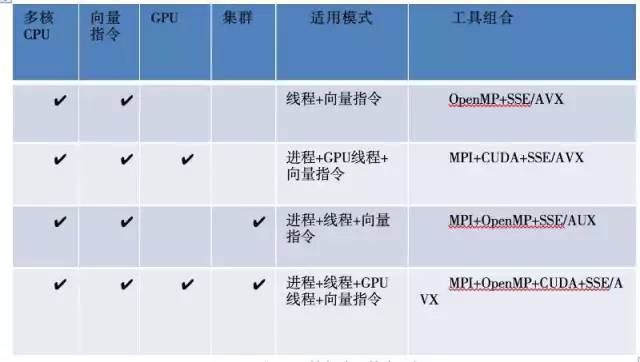
总结一点,大家可以根据自己的硬件条件来选择合适的并行计算解决方案。
这里要提醒一点,大家如果想 GPU 编程的话,使用 CUDA 技术化,一定要买 nvidia 的显卡,因为其他的装不上。
分布式机器学习系统需要解决的三个问题:
如何更好的切分成多个任务
如何调度子任务
均衡各节点的负载
并行计算模型
BSP

这是一个通用的机器学习问题建模和优化。大规模机器学习的核心就是梯度计算的并行化。BSP 是较早的一个并行计算模型,也是当前主流的并行计算模型之一。
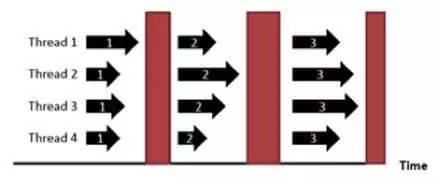
每一步详细分解下。
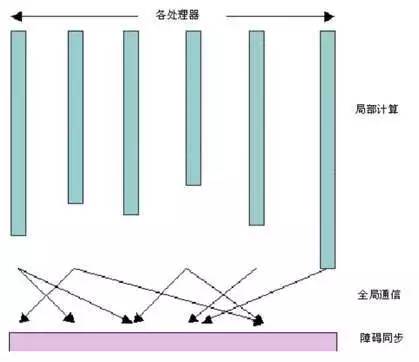
其计算过程也比较好理解,就是计算 ->同步 ->计算 ->同步......
BSP 具有如下优点:
它将处理器和路由器分开,强调了计算任务和通信任务的分开,而路由器仅仅完成点到点的消息传递,不提供组合、复制和广播等功能,这样做既掩盖具体的互连网络拓扑,又简化了通信协议;
采用障碍同步的方式以硬件实现的全局同步是在可控的粗粒度级,从而提供了执行紧耦合同步式并行算法的有效方式,而程序员并无过分的负担;
BSP 模型的这些特点使它成为并行计算的主流模型之一,开源 的 Mahout, Apache Huma, Spark mllib, Google Pregel, Graphlab, xgboost 等的并行实现都是基于 BSP 模型的。
BSP 模型在每一轮结论之后都需要进行一次同步,这很容易造成木桶效应,由于任务的切分中每个任务计算量并不是完全均匀的,而且在复杂的分布式计算环境下,每台机器的硬件条件也是存在差异的,这就造成了 BSP 模型每一轮迭代的效率由最慢的计算任务来决定,为了缓解这个现象,SSP 模型被提出来了。
SSP
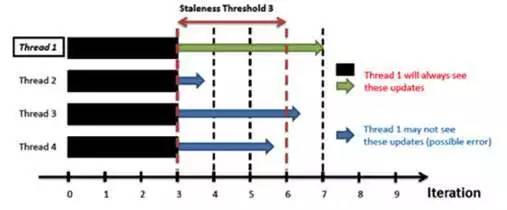
SSP 模型
我们把 SSP 中每个任务过程称为 worker,SSP 模型通过设置一个 bound 来确定同步的时机。当最快的 worker 比最慢的 worker 超过这个 bound 时所有的 work 来就行一次参数的同步。这个 bound 可以根据迭代的次数,也可以根据参数更新的差值来确定。SSP 协议的好处在于,faster worker 会遇到参数版本过于 stale 的问题,导致每一步迭代都需要网络通信,从而达到了平衡计算和网络通信时间开销的效果。
SSP 模型数学上证明是可以收敛的。
原因可以这么来解释吧,就是条条大道通罗马。
对于机器学习程序来说,中间结果的错误是可以容忍的,有多条路径都可以收敛到最优,因此少量的错误可类似于随机噪声,但不影响最终的收敛结果。尽快每一次迭代可能存在误差,但是经过多轮迭代后,平均误差趋近于零。尽管每次可能不是最优的求解路径,但是最终还是找到一条通往最优解的整体路径。尽管这条路径不是最快的路径,但是由于在通讯方面的优势,整体的求解速度相对于 BSP 来说还是更快一些,特别是在数据规模和参数规模非常大的情况下,在多机并行的环境下。
ASP
ASP 是一种完全异步的方式,相当于取消了 BSP 中的同步环节。
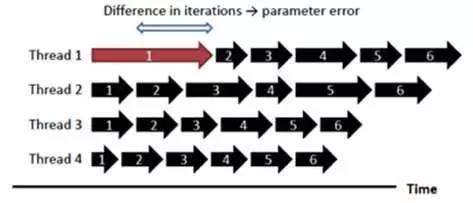
ASP 的运行速度更快,当然它是没有收敛性保证的。
SSP 协议可以有效平衡计算和网络通信的开销。
对于非凸问题,BSP 和 SSP 收敛的最优解可能不一样。对于非凸优化问题(比如说神经网络),有大量局部最优解,随机梯度下降(可以跳出局部最优解)比批量梯度下降效果要更好。
Parameter Server
参数服务器是近来来在分布式机器学习领域非常火的一种技术。
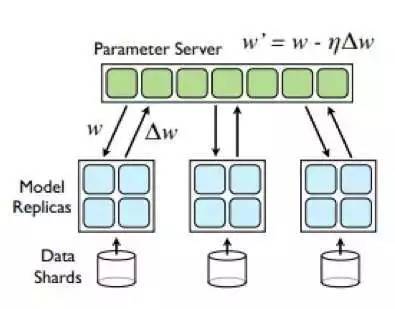
Parameter Server 参数服务器中比较重要的是各个计算节点的参数同步问题。
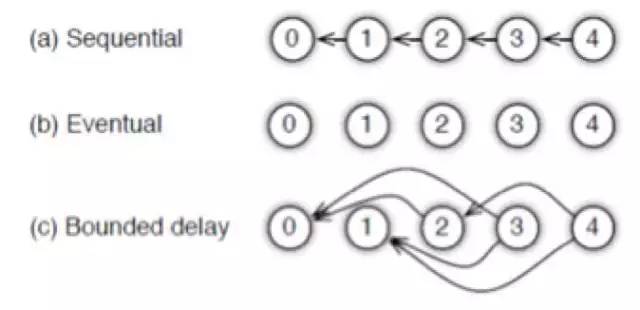
Sequential: 这里其实是 synchronous task,任务之间是有顺序的,只有上一个任务完成,才能开始下一个任务,也就是同步方式;Eventual: 跟 sequential 相反,所有任务之间没有顺序,各自独立完成自己的任务,也就是异步的形式;Bounded Delay: 这是 sequential 跟 eventual 之间的折中,当最快计算任务比最慢计算任务快于一定阈值时进行等待,也可以当计算任务对梯度的累计更新值大于一定阈值时进行等待。
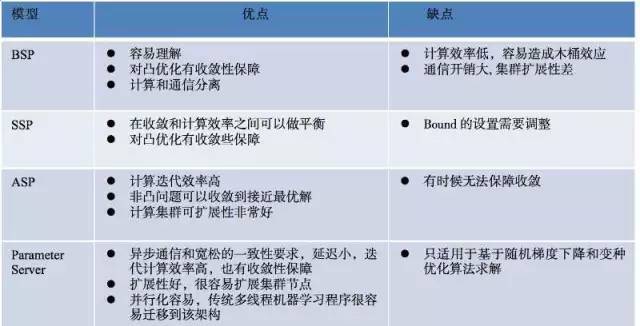
总结这 4 种模式的优缺点:
并行计算案例
Xgboost 的分布式库 Rabit
Xgboost 是目前非常牛的一个机器学习包,其分布式做得非常好,我们现在来看一下。
Xgboost 的分布式实现由如下几个特点:
OpenMp 支持多核并行
CUDA 支持 GPU 加速
Rabit 支持分布式
其核心就是 Rabit,Xgboost 将其分布式核心功能抽象出来,Rabit 是基于 BSP 模型的,通过两个基本原语 Broadcast 和 AllReduce 来实现其分布式功能。Broadcase 和 AllReduce 与 MPI 中的功能基本上一致,设计思想类似,为什么不直接使用 MPI 呢。原因就是 Rabit 在这个基础上提供了更好的容错处理功能,弥补了 MPI 的不足。
为什么传统的 MapReduce 模型在机器学习并行化中的作用有限呢?
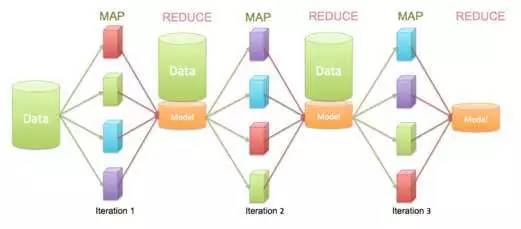
上图示传统 MR,下图是 XGBOOST 的并行计算过程。
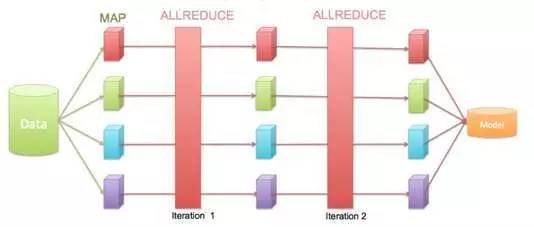
Rabit 在两个地方都做了优化,其一每一轮迭代结束后计算结果不需要放入到存储系统,而是直接保留在内存;其二,每一轮迭代后没有数据重新分发的过程,直接进行下一轮迭代,这使得计算效率大大提升。
Xgboost 的 Rabit 对分布式操作的封装非常的好,可以很方便移植到其他系统中去。我们可以基于 Rabit 来开发我们的分布式机器学习程序。

Rabit 提供了两个最基本的操作 Allreduce, Broadcast 可以很方便进行程序开发。
MXNet 的分布式库 ps-lite
最后我们来提提 mxnet。
ps-lite 是 mxnet 分布式现实的核心,它是基于 parameter server 模型的。
Ps-lite 的使用很简单,可以很方便对现有的机器学习程序进行分布式改造,Ps-lite 的核心是 KVStore,它提供一个分布式的 key-value 存储来进行数据交换。它主要有两个函数:
push: 将 key-value 对从一个设备 push 进存储, 用于计算节点将更新后的参数值推送到参数服务器上。
pull:将某个 key 上的值从存储中 pull 出来,用于计算节点从参数服务器上获取相关的参数值。
在下面例子中,我们将 单机梯度下降算法改成分布式梯度下降。单机梯度下降算法:

基于 ps-lite 的成分布式梯度下降:

加入图片
这是 ps-lite 分布式改造最常见的一个例子。
我们可以很方便利用开源这些分布式框架来构建我们的分布式应用,比如在工作中,我就基于 ps-lite 对 word2vec, libffm 很快实现了分布式,特别是对 word2vec, libffm 的官方版本是多线程的,改造更简单。

时间:2018-10-09 22:51 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















