关于Python 代码的实践小结
最近写了较多的 Python 脚本,将最近自己写的脚本进行一个总结,其中有些是 Python 独有的,有些是所有程序设计中共有的:
考虑使用 Logger(logger 怎么配置,需要输出哪些信息 — 可以反向考虑,自己看到这个 logger 的时候想了解什么信息)
传递的数据结构如何考虑(是否对调用方有先验知识的要求,比如返回一个 Tuple,则需要用户了解 tuple 中元素的顺序,这样情况是否应该进行封装;),数据结构定义清楚了,很多东西也就清楚了。
如何操作数据库(可以学习 sqlalchemy,包括 core 和 orm 两种 api)
异常如何处理(异常应该分开捕获 — 可以清楚的知道什么情况下导致的,异常之后应该打印日志说明出现什么问题,如果情况恶劣需要进行异常再次抛出或者报警)
所有获取资源的地方都应该做 check(a. 没有获取到会怎么办;b.获取到异常的怎么办)
所有操作资源的地方都应该检查是否操作成功
每个函数都应该简短,如果函数过长应该进行拆分(有个建议值,函数包含的行数应该在 20-30 行之间,具体按照这个规范做过一次之后就会发现这样真好)
使用 class 之后,考虑重构 __str__ 函数,用户打印输出(如果不实现 __str__,会调用 __repr__ ),如果对象放到 collection 中之后,需要实现 __repr__ 函数,用于打印整个 collection 的时候,直观显示
如果有些资源会发生变化,可以单独抽取出来,做成函数,这样后续调用就可以不用改变了
附上一份 Python2.7 代码(将一些私有的东西进行了修改)
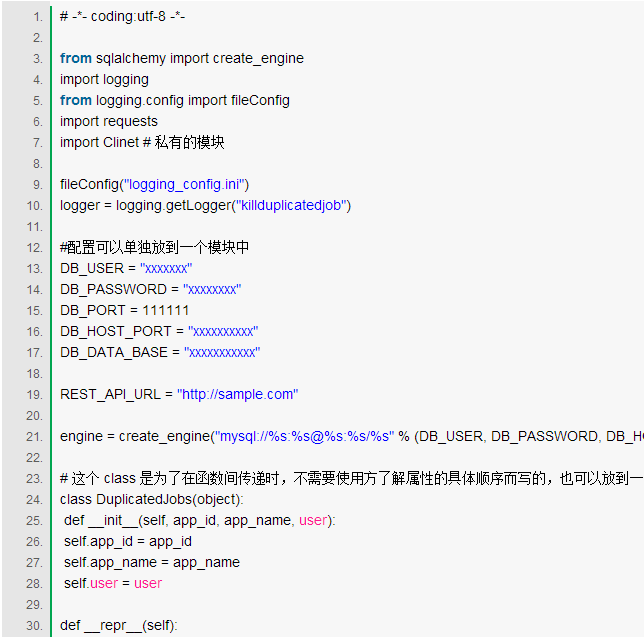



其中 logger 配置文件如下(对于 Python 的 logger,官方文档写的非常好,建议读一次,并且实践一次)


时间:2018-10-09 22:51 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]属于 Hadoop 的大数据时代已结束
- [数据挖掘]大数据凉凉了?Apache将一众大数据开源项目束之
- [数据挖掘]底层I/O性能大PK:Python/Java被碾压,Rust有望取代
- [数据挖掘]利用大数据预测,先要避免“冷启动偏差”!|
- [数据挖掘]大数据分析的技术有哪些?
- [数据挖掘]大数据分析会遇到哪些难题?
- [数据挖掘]RedMonk语言排行:Python力压Java,Ruby持续下滑
- [数据挖掘]不得了!Python 又爆出重大 Bug~
- [数据挖掘]TIOBE 1 月榜单:Python年度语言四连冠,C 语言再次
- [数据挖掘]盘点2020年晋升为Apache TLP的大数据相关项目
相关推荐:
网友评论:















