如何把时间序列问题转化为监督学习问题?通俗易
但在使用机器学习之前,时间序列问题需要被转化为监督学习问题。从仅仅是一个序列,变成成对的输入、输出序列。
这篇教程里,你将学到如何把单变量、多变量时间序列问题转为机器学习算法能解决的监督学习问题。本教程包含:
如何创建把时间序列数据集转为监督学习数据集的函数;
如何让单变量时间序列数据适配机器学习
如何让多变量时间序列数据适配机器学习
现在我们开始。
时间序列 vs. 监督学习
正式开始前,我们需要更好地理解时间序列和监督学习的数据形式。时间序列是一组按照时间指数排序的数字序列,可被看成是一列有序的值。比如:

监督学习问题由输入(X)和输出(y)速成,其算法能学习如何根据输入模式预测输出模式。
比如:

Pandas shift() 函数
对于把时间序列数据转化为监督学习问题,这是一个关键的函数。
给定一个 DataFrame, shift() 函数可被用来创建数据列的副本,然后 push forward (NaN 值组成的行添加到前面)或者 pull back(NaN 值组成的行添加到末尾)。为了给时间序列数据集创建滞后观察(lag observation)列以及预测观察(forecast observation)列,并按照监督学习的格式来,这是必须的操作。
我们来看看一些 shift 函数的实操例子。
我们可以定义一个由 10 个数字序列组成的伪时间序列数据集,该例子中,DataFrame 中的单个一列如下所示:

运行该例子,输出时间序列数据,每个观察要有对应的行指数。

我们通过在顶端插入新的一行,用一个时间步(time step)把所有的观察降档(shift down)。由于新的一行不含数据,可以用 NaN 来表示“无数据”。
Shift 函数能完成该任务。我们可以把处理过的列插入到原始序列旁边。

运行该例子,使数据集有了两列。第一列是原始观察,第二列是 shift 过新产生的列。
可看到,把序列向前 shift 一个时间步,产生了一个原始的监督学习问题,虽然 X 、y 的顺序不对。无视行标签的列。由于 NaN 值,第一行需要被抛弃。第二行第二列(输入 X)现实输入值是 0.0,第一列的值是 1 (输出 y)。

我们能看到,如果在 shift 2、3 ……重复该过程,要如何创建能用来预测输出值 y 的长输出序列(X)。
Shift 操作器可以接受一个负整数值。这起到了通过在末尾插入新的行,来拉起观察的作用。下面是例子:

运行该例子显示出,新的一列的最后一个值是一个 NaN 值。可以看到,预测列可被作为输入 X,第二行作为输出值 (y)。输入值 0 就可以用来预测输出值 1。

技术上,在时间序列预测术语里,当前时间是(t),未来是(t+1, t+n) 它们都是预测时间。过去的观察 (t-1, t-n) 被用来做预测。对于一个监督学习问题,在一个有输入、输出模式的时间序列里,我们可以看到如何用正负 shift 来生成新的 DataFrame 。
这不仅可用来解决经典的 X -> y 预测问题, 还可用到输入、输出都是序列的 X -> Y 上。
另外,shift 函数也在所谓的多元时间序列问题上有效。这种情况下,并不是时间序列不只有一组观察,而是多组(举个例子,气温和气压)。所有时间序列中的变量可被向前或向后 shift,来创建多元输入输出序列。更多详情下文会提到。
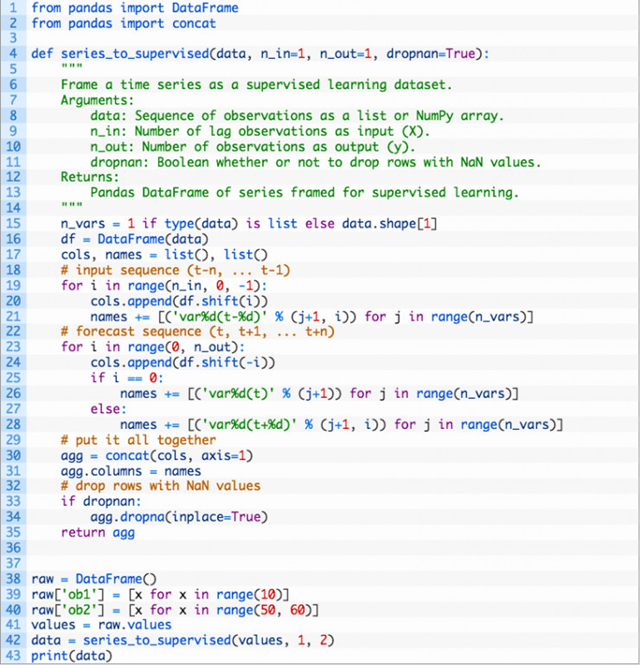
The series_to_supervised() 函数
给定理想的输入、输出序列长度,我们可以用 Pandas 里的 shift() 函数自动生成时间序列问题的框架。
这是一个很有用的工具。它帮助我们用机器学习算法探索同一个时间序列问题的不同框架,来找出哪一个将会产生具有更好效果的模型。这部分中,我们为 series_to_supervised() ,一个新的 Python 函数定义。它能把单变量、多变量时间序列转化为监督学习数据集。
该函数有四个参数:
Data:作为一个列表或 2D NumPy 阵列的观察序列。必需。
n_in: 作为输入 X 的 lag observation 的数量。值可能在 [1..len(data)] 之间。可选。默认为 1 。
n_out: 作为输出 y 的观察的数量。值可能在 [0..len(data)-1] 之间。可选。默认为 1 。
dropnan: 不管随着 NaN 值是否丢掉一些行,它都是布尔值(Boolean)。可选。默认为 True。
函数返回一个单个的值:
return: 序列的 Pandas DataFrame 转为监督学习。
新数据集创建为一个 DataFrame,每一列通过变量字数和时间步命名。这使得开发者能设计各种各样时间步序列类型的预测问题。
当 DataFrame 被返回,你可以决定怎么把它的行,分为监督学习的 X 和 y 部分。这里可完全按照你的想法。该函数用默认参数定义,因此,如果你仅仅用你的数据调用它。它会创建一个 X 为 t-1,y 是 t 的 DataFrame。
该函数兼容 Python 2 和 Python 3。完整函数在下面,包括注解。

有了整个的函数,现在可以开始探索怎么用它。
一步的单变量预测
在时间序列预测中,使用滞后观察(比如 t-1)作为输入变量来预测当前时间不,是通用做法。这被称为一步预测(one-step forecasting)。下面的例子,展示了如何一个滞后时间步( t-1)预测当前时间步(t).
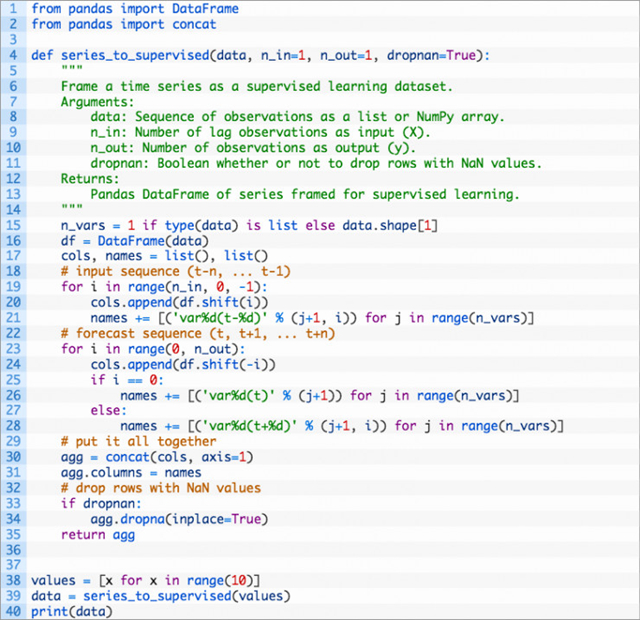
运行例子,输出改造过的时间序列的输出。

可看到,观察被命名为“var1”,输入观察被命名为 (t-1),输出时间步被命名为 (t)。还可以看到,NaN 值得行,已经自动从 DataFrame 中移除。我们可以用随机数字长度的输入序列重复该例子,比如 3。这可以通过把输入序列的长度确定为参数来实现。比如:
data = series_to_supervised(values, 3)
完整例子如下:
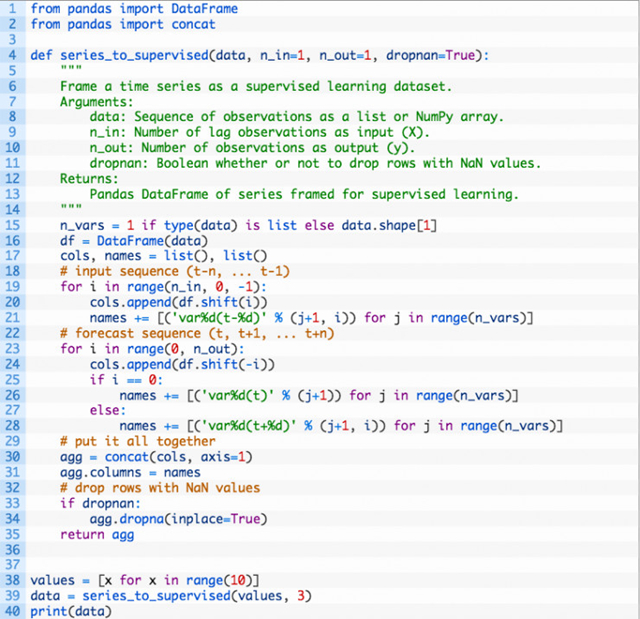
再一次,运行例子输出改造的序列。可以看到输入序列是正确的从左到右的顺序。输出变量在最右边进行预测。

多步骤预测还是序列预测
有另一类预测问题,是用过去的观察,来预测出将来贯彻的一个序列。这可以被称作序列预测或者多步骤预测。通过确定另一个参数,我们能把一个时间序列转化为序列预测。比如,我们可以把一个输入序列为两个过去观察,要预测两个未来观察的序列问题,进行如下转化:
data = series_to_supervised(values, 2, 2)
完整例子如下:
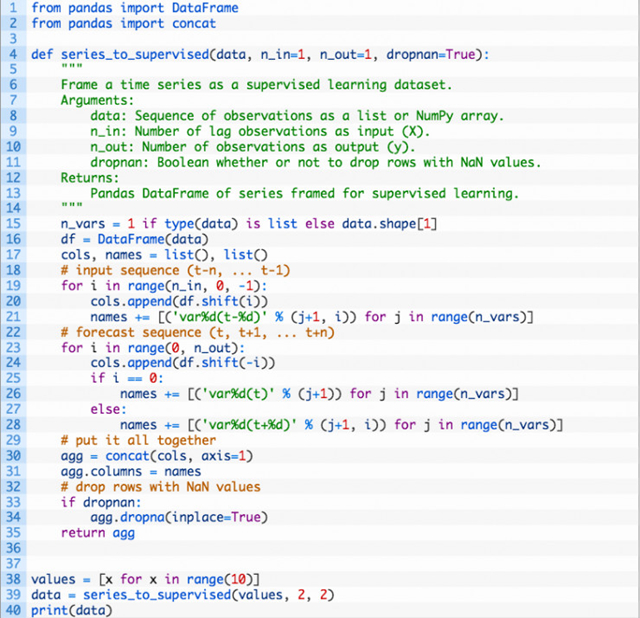
运行该例子,显示出分别把 (t-n)、(t+n) 作为输入、输出变量,以及把当前观察 (t)作为输出之间的区别。

多元预测
另一种重要的时间序列类型被称为多元时间序列。这时有对多个不同度量(measure)的观察,以及我们对预测其中的一个或更多的兴趣。比如说,也许有两组时间序列观察 obs1 和 obs2 ,我们想要预测其中之一,或者两个都预测。我们可用同样的方法调用 series_to_supervised()。举个例子:
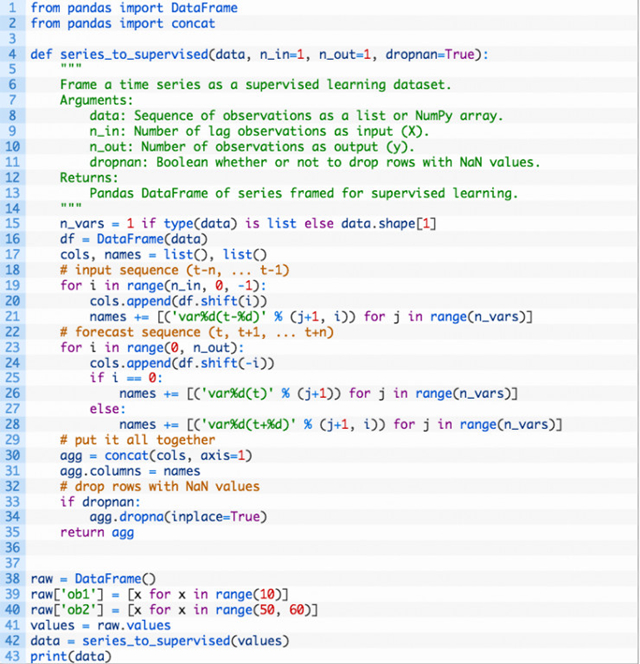
运行这个例子会输出数据的新框架,显示出两个变量在一个时间步下的输入模式,以及两个变量一个时间不的输出模式。
取决去问题的具体内容。可以随机把列分为 X 和 Y 部分,比如说,如果当前观察 var1 也被作为输入提供,那么只有 var2 会被预测。
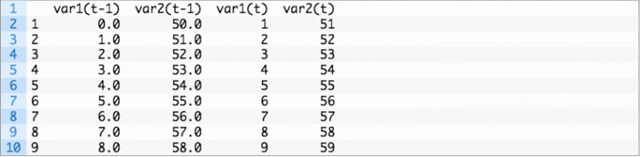
通过上面这样确定具体的输入输出序列长度,可轻松完成多元时间序列的预测。下面是一个把一个时间步作为输入,两个时间步作为预测序列的转化例子。
运行该例子会显示改造过的大 DataFrame。

建议:拿你自己的数据集做实验,试试多个不同的框架来看哪个效果更好。
文章来自36大数据。

时间:2018-10-09 22:51 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]底层I/O性能大PK:Python/Java被碾压,Rust有望取代
- [数据挖掘]RedMonk语言排行:Python力压Java,Ruby持续下滑
- [数据挖掘]不得了!Python 又爆出重大 Bug~
- [数据挖掘]TIOBE 1 月榜单:Python年度语言四连冠,C 语言再次
- [数据挖掘]TIOBE12月榜单:Java重回第二,Python有望四连冠年度
- [数据挖掘]这个可能打败Python的编程语言,正在征服科学界
- [数据挖掘]2021年编程语言趋势预测:Python和JavaScript仍火热,
- [数据挖掘]Spark 3.0重磅发布!开发近两年,流、Python、SQL重
- [数据挖掘]Python 为什么推荐蛇形命名法?
- [数据挖掘]Python才是世界上最好的语言
相关推荐:
网友评论:















