Java线程池的理论与实践
Java中的Thread与操作系统中的线程的关系
线程切换的各种开销
ThreadGroup存在的意义
使用线程池减少线程开销
Executor的概念
ThreadPoolExecutor中的一些具体实现
如何监控线程的健康
参考ThreadPoolExecutor来设计适合自己的线程模型
一、问题描述
这个项目所在系统的软件架构(从开发到运维)基本上采用的是微服务架构,微服务很好地解决了我们系统的复杂性问题,但是随之也带来了一些问题,比如在此架构中大部分的服务都拥有自己单独的数据库,而有些(很重要的)业务需要做跨库查询。相信这种「跨库查询」的问题很多实践微服务的公司都碰到过,通常这类问题有以下几种解决方案(当然,还有更多其他的方案,这里就不一一叙述了):
严格通过服务提供的API查询。这样做的好处是将服务完全当做黑盒,可以最大限度得减少服务间的依赖与耦合关系,其次还能根据实际需求服务之间使用不同的数据库类型;缺点是则代价太大。
将关心的信息冗余到自己的库中,并提供API让其他服务来主动修改。优点是信息更新十分实时,缺点是增加了服务间的依赖。
指令与查询分离(CQRS)。将可能被其他服务关心的数据放入数据仓库(或者做成类似于物化视图、搜索引擎等),数据仓库只提供读的功能。优点是对主库不会有压力,服务只要关心实现自己的业务就好,缺点是数据的实时性会受到了挑战。
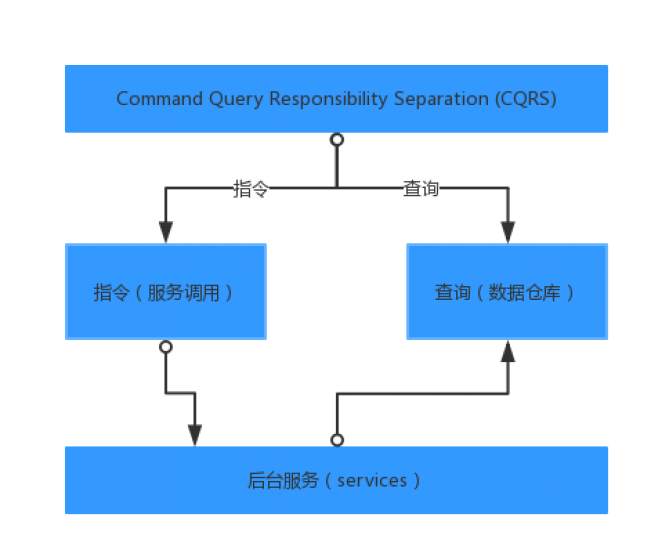
指令与查询分离
结合实际情况,我们使用的是第3种方案。然而随着越来越多的业务依赖读库,甚至依赖其中一些状态的变化,所以读库的数据同步如果出现高延时,则会直接影响业务的进行。出了几次这种事情后,于是下决心要改善这种情况。首先想到的就是使用线程池来进行消息的消费(写入读库),JDK自从1.5开始提供了实用而强大的线程池工具——Executor框架。
二、Executor框架
Executor框架在Java1.5中引入,大部分的类都在包java.util.concurrent中,由大神Doug Lea写成,其中常用到的有以下几个类和接口:
java.util.concurrent.Executor一个只包含一个方法的接口,它的抽象含义是:用来执行一个Runnable任务的执行器。
java.util.concurrent.ExecutorService对Executor的一个扩展,增加了很多对于任务和执行器的生命周期进行管理的接口,也是通常进行多线程开发最常使用的接口。
java.util.concurrent.ThreadFactory一个生成新线程的接口。用户可以通过实现这个接口管理对线程池中生成线程的逻辑
java.util.concurrent.Executors提供了很多不同的生成执行器的实用方法,比如基于线程池的执行器的实现。
三、为什么要用线程池
Java从最开始就是基于线程的,线程在Java里被封装成一个类java.lang.Thread。在面试中很多面试官都会问一个很基础的关于线程问题:
Java中有几种方法新建一个线程?
所有人都知道,标准答案是两种:继承Thread或者实现Runnable,在JDK源代码中Thread类的注释中也是这么写的。
然而在我看来这两种方法根本就是一种,所有想要开启线程的操作,都必须生成了一个Thread类(或其子类)的实例,执行其中的native方法start0()。
Java中的线程
Java中将线程抽象为一个普通的类,这样带来了很多好处,譬如可以很简单的使用面向对象的方法实现多线程的编程,然而这种程序写多了容易会忘记,这个对象在底层是实实在在地对应了一个OS中的线程。

操作系统中的线程和进程
上图中的进程(Process)可以看做一个JVM,可以看出,所有的进程有自己的私有内存,这块内存会在主存中有一段映射,而所有的线程共享JVM中的内存。在现代的操作系统中,线程的调度通常都是集成在操作系统中的,操作系统能通过分析更多的信息来决定如何更高效地进行线程的调度,这也是为什么Java中会一直强调,线程的执行顺序是不会得到保证的,因为JVM自己管不了这个,所以只能认为它是完全无序的。
另外,类java.lang.Thread中的很多属性也会直接映射为操作系统中线程的一些属性。Java的Thread中提供的一些方法如sleep和yield其实依赖于操作系统中线程的调度算法。
关于线程的调度算法可以去读操作系统相关的书籍,这里就不做太多叙述了。
线程的开销
通常来说,操作系统中线程之间的上下文切换大约要消耗1到10微秒
从上图中可以看出线程中包含了一些上下文信息:
CPU栈指针(Stack)、
一组寄存器的值(Registers),
指令计数器的值(PC)等,
它们都保存在此线程所在的进程所映射的主存中,而对于Java来说,这个进程就是JVM所在的那个进程,JVM的运行时内存可以简单的分为如下几部分:
若干个栈(Stack)。每个线程有自己的栈,JVM中的栈是不能存储对象的,只能存储基础变量和对象引用。
堆(Heap)。一个JVM只有一个堆,所有的对象都在堆上分配。
方法区(Method Area)。一个JVM只有一个方法区,包含了所有载入的类的字节码和静态变量。
其中#1中的栈可以认为是这个线程的上下文,创建线程要申请相应的栈空间,而栈空间的大小是一定的,所以当栈空间不够用时,会导致线程申请不成功。在Thread的源代码中可以看到,启动线程的最后一步是执行一个本地方法private native void start0(),代码1是OpenJDK中start0最终调用的方法:
//代码1
JVM_ENTRY(void, JVM_StartThread(JNIEnv* env, jobject jthread))
JVMWrapper("JVM_StartThread");
JavaThread *native_thread = NULL;
bool throw_illegal_thread_state = false;
// We must release the Threads_lock before we can post a jvmti event
// in Thread::start.
{
MutexLocker mu(Threads_lock);
//省略一些代码
jlong size =
java_lang_Thread::stackSize(JNIHandles::resolve_non_null(jthread));
size_t sz = size > 0 ? (size_t) size : 0;
native_thread = new JavaThread(&thread_entry, sz);
}
if (native_thread->osthread() == NULL) {
THROW_MSG(vmSymbols::java_lang_OutOfMemoryError(),
"unable to create new native thread");
}
Thread::start(native_thread);
JVM_END
从代码1中可以看到,线程的创建首先需要栈空间,所以过多的线程创建可能会导致OOM。
同时,线程的切换会有以下开销:
CPU中执行上下文的切换,导致CPU中的「指令流水线(Instruction Pipeline)」的中断和CPU缓存的失效。
如果线程太多,线程切换的时间会比线程执行的时间要长,严重浪费了CPU资源。
对于共享资源的竞争(锁)会导致线程切换开销急剧增加。
根据以上的描述,所以通常建议尽可能创建较少的线程,减少锁的使用(尤其是synchronized),尽量使用JDK提供的同步工具。而为了减少线程上下文切换带来的开销,通常使用线程池是一个有效的方法。
Java中的线程池
Executor框架中最常用的大概就是java.util.concurrent.ThreadPoolExecutor了,对于它的描述,简单的说就是「它维护了一个线程池,对于提交到此Executor中的任务,它不是创建新的线程而是使用池内的线程进行执行」。对于「数量巨大但执行时间很小」的任务,可以显著地减少对于任务执行的开销。java.util.concurrent.ThreadPoolExecutor中包含了很多属性,通过这些属性开发者可以定制不同的线程池行为,大致如下:
1. 线程池的大小:corePoolSize和maximumPoolSize
ThreadPoolExecutor中线程池的大小由这两个属性决定,前者指当线程池正常运行起来后的最小(核心)线程数,当一个任务到来时,若当前池中线程数小于corePoolSize,则会生成新的线程;后者指当等待队列满了之后可生成的最大的线程数。在例1中返回的对象中这两个值相等,均等于用户传入的值。
2. 用户可以通过调用java.util.concurrent.ThreadPoolExecutor上的实例方法来启动核心线程(core pool)
3. 可定制化的线程生成方式:threadFactory
默认线程由方法Executors.defaultThreadFactory()返回的ThreadFactory进行创建,默认创建的线程都不是daemon,开发者可以传入自定义的ThreadFactory进行对线程的定制化。
4. 非核心线程的空闲等待时间:keepAliveTime
5. 任务等待队列:workQueue
这个队列是java.util.concurrent.BlockingQueue
容量为0。如:java.util.concurrent.SynchronousQueue等待队列容量为0,所有需要阻塞的任务必须等待池内的某个线程有空闲,才能继续执行,否则阻塞。调用Executors.newCachedThreadPool的两个函数生成的线程池是这个策略。
不限容量。如:不指定容量的java.util.concurrent.LinkedBlockingQueue等待队列的长度无穷大,根据上文中的叙述,在这种策略下,不会有多于corePoolSize的线程被创建,所以maximumPoolSize也就没有任何意义了。调用Executors.newFixedThreadPool生成的线程池是这个策略。
限制容量。如:指定容量的任何java.util.concurrent.BlockingQueue
6. 任务拒绝处理器:defaultHandler
如果任务被拒绝执行,则会调用这个对象上的RejectedExecutionHandler.rejectedExecution()方法,JDK定义了4种处理策略,用户可以自定义自己的任务处理策略。
7. 允许核心线程过期:allowCoreThreadTimeOut
上面说的所有情况都是基于这个变量为false(默认值)来说的,如果你的线程池已经不使用了(不被引用),但是其中还有活着的线程时,这个线程池是不会被回收的,这种情况就造成了内存泄漏——一块永远不会被访问到的内存却无法被GC回收。
用户可以通过在抛弃线程池引用的时候显式地调用shutdown()来释放它,或者将allowCoreThreadTimeOut设置为true,则在过期时间后,核心线程会被释放,则其会被GC回收。
四、如果线程死掉了怎么办
几乎所有Executors中生成线程池的方法的注释上,都有代表相同意思的一句话,表示如果线程池中的某个线程死掉了,线程池会生成一个新的线程代替它。下面是方法java.util.concurrent.Executors.newFixedThreadPool(int)上的注释。
If any thread terminates due to a failure during execution prior to shutdown, a new one will take its place if needed to execute subsequent tasks.
线程死亡的原因
我们都知道守护线程(daemon)会在所有的非守护线程都死掉之后也死掉,除此之外导致一个非守护线程死掉有以下几种可能:
自然死亡,Runnable.run()方法执行完后返回。
执行过程中有未捕获异常,被抛到了Runnable.run()之外,导致线程死亡。
其宿主死亡,进程关闭或者机器死机。在Java中通常是System.exit()方法被调用
其他硬件问题。
线程池要保证其高可用性,就必须保证线程的可用。如一个固定容量的线程池,其中一个线程死掉了,它必须要能监控到线程的死亡并生成一个新的线程来代替它。ThreadPoolExecutor中与线程相关的有这样几个概念:
java.util.concurrent.ThreadFactory,在Executors中有两种ThreadFactory,但其提供的线程池只使用了一种java.util.concurrent.Executors.DefaultThreadFactory,它是简单的使用ThreadGroup来实现。
java.lang.ThreadGroup,从Java1开始就存在的类,用来建立一个线程的树形结构,可以用它来组织线程间的关系,但其并没有对其包含的子线程的监控。
java.util.concurrent.ThreadPoolExecutor.Worker,ThreadPoolExecutor对线程的封装,其中还包含了一些统计功能。
ThreadPoolExecutor中如何保障线程的可用
在ThreadPoolExecutor中使用了一个很巧妙的方法实现了对线程池中线程健康状况的监控,代码2是从ThreadPoolExecutor类源码中截取的一段代码,它们在一起说明了其对线程的监控。
可以看到,在ThreadPoolExecutor中的线程被封装成一个对象Worker,而将其中的run()代理到ThreadPoolExecutor中的runWorker(),在runWorker()方法中是一个获取任务并执行的死循环。如果任务的运行出了什么问题(如抛出未捕获异常),processWorkerExit()方法会被执行,同时传入的completedAbruptly参数为true,会重新添加一个初始任务为null的Worker,并随之启动一个新的线程。
//代码2
//ThreadPoolExecutor的动态内部类
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
/** 对象中封装的线程 */
final Thread thread;
/** 第一个要运行的任务,可能为null. */
Runnable firstTask;
/** 任务计数器 */
volatile long completedTasks;
//省略其他代码
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
/** Delegates main run loop to outer runWorker */
public void run() {
runWorker(this);
}
}
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
try {
beforeExecute(wt, task);
try {
task.run();
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
private void processWorkerExit(Worker w, boolean completedAbruptly) {
if (runStateLessThan(c, STOP)) {
if (!completedAbruptly) {
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
if (min == 0 && ! workQueue.isEmpty())
min = 1;
if (workerCountOf(c) >= min)
return; // replacement not needed
}
addWorker(null, false);
}
}
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
五、回到我的问题
由于各种各样的原因,我们并没有使用数据库自带的主从机制来做数据的复制,而是将主库的所有DML语句作为消息发送到读库(DTS),同时自己实现了数据的重放。第一版的数据同步服务十分简单,对于主库的DML消息处理和消费(写入读库)都是在一个线程内完成的.这么实现的优点是简单,但缺点是直接导致了表与表之间的数据同步会受到影响,如果有一个表A忽然来了很多的消息(往往是批量修改数据造成的),则会占住消息处理通道,影响其他业务数据的及时同步,同时单线程写库吞吐太小。
上文说到,首先想到的是使用线程池来做消息的消费,但是不能直接套用上边说的Executor框架,由于以下几个原因:
ThreadPoolExecutor中默认所有的任务之间是不互相影响的,然而对于数据库的DML来说,消息的顺序不能被打乱,至少单表的消息顺序必须有序,不然会影响最终的数据一致。
ThreadPoolExecutor中所有的线程共享一个等待队列,然而为了防止表与表之间的影响,每个线程应该有自己的任务等待队列。
写库操作的吞吐直接受到提交事务数的影响,所以此多线程框架要可以支持任务的合并。
重复造轮子是没有意义的,但是在我们这种场景下JDK中现有的Executor框架不符合要求,只能自己造轮子。
我的实现
首先把线程抽象成「DML语句的执行器(Executor)」。其中包含了一个Thread的实例,维护了自己的等待队列(限定容量的阻塞队列),和对应的消息执行逻辑。
除此之外还包含了一些简单的统计、线程健康监控、合并事务等处理。
Executor的对象实现了Thread.UncaughtExceptionHandler接口,并绑定到其工作线程上。同时ExecutorGroup也会再生成一个守护线程专门来守护池内所有线程,作为额外的保险措施。
把线程池的概念抽象成执行器组(ExecutorGroup),其中维护了执行器的数组,并维护了目标表到特定执行器的映射关系,并对外提供执行消息的接口,其主要代码如下:
//代码3
public class ExecutorGroup {
Executor[] group = new Executor[NUM];
Thread boss = null;
Map
// AtomicInteger cursor = new AtomicInteger();
volatile int cursor = 0;
public ExecutorGroup(String name) {
//init group
for(int i = 0; i < NUM; i++) {
logger.debug("启动线程{},{}", name, i);
group[i] = new Executor(this, String.format("sync-executor-%s-%d", name, i), i / NUM_OF_FIRST_CLASS);
}
startDaemonBoss(String.format("sync-executor-%s-boss", name));
}
//额外的保险
private void startDaemonBoss(String name) {
if (boss != null) {
boss.interrupt();
}
boss = new Thread(() -> {
while(true) {
//休息一分钟。。。
if (this.group != null) {
for (int i = 0; i < group.length; i++) {
Executor executor = group[i];
if (executor != null) {
executor.checkThread();
}
}
}
}
});
boss.setName(name);
boss.setDaemon(true);
boss.start();
}
public void execute(Message message){
logger.debug("执行消息");
//省略消息合法性验证
if (!registeredTables.containsKey(taskKey)) {
//已注册
// registeredTables.put(taskKey, cursor.getAndIncrement());
registeredTables.put(taskKey, cursor++ % NUM);
}
int index = registeredTables.get(taskKey);
logger.debug("执行消息{},注册索引{}", taskKey, index);
try {
group[index].schedule(message);
} catch (InterruptedException e) {
logger.error("准备消息出错", e);
}
}
}
完成后整体的线程模型如下图所示:
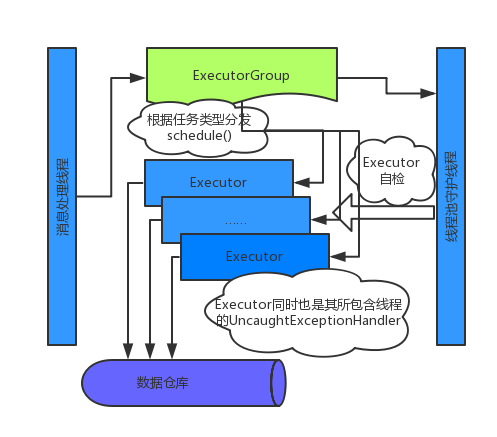
新的线程模型
Java1.7新加入的TransferQueue
Java1.7中提供了新的队列类型TransferQueue,但只提供了一个它的实现java.util.concurrent.LinkedTransferQueue

时间:2018-10-09 22:51 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]设计bug导致数据被删除,java工程师背锅被开除:
- [数据挖掘]谷歌甲骨文Java专利大战终审判决:安卓使用Java
- [数据挖掘]Java 微服务能像 Go 一样快吗?
- [数据挖掘]底层I/O性能大PK:Python/Java被碾压,Rust有望取代
- [数据挖掘]TIOBE 3 月编程语言:Swift 一路低走,Java 份额大跌
- [数据挖掘]RedMonk语言排行:Python力压Java,Ruby持续下滑
- [数据挖掘]TIOBE12月榜单:Java重回第二,Python有望四连冠年度
- [数据挖掘]最受欢迎Java数据库访问框架大比拼,你独爱哪一
- [数据挖掘]程序员技术选型:写Go还是Java?网友:Rust不香了
- [数据挖掘]Java高并发综合
相关推荐:
网友评论:















