历时半年,腾讯Angel为了开源都经历了些什么?
Github 上,其他团队的研发人员与 Angel 开发团队就问题进行探讨
这并不是 Angel 的首次亮相,去年 5 月,面向高维度机器学习的分布式计算框架 Angel 进入大众视野;12 月 18 日,在深圳举办的腾讯大数据技术峰会暨 KDD China 技术峰会上,腾讯大数据宣布推出了面向机器学习的第三代高性能计算平台 Angel,主打易用性,不仅提供机器学习算法库以及友好的编程接口,还内置数据自动切分、数据计算和模型划分的自动方案及异步控制等功能并支持多种高维度机器学习场景。(详见《腾讯大数据将开源高性能计算平台 Angel,机器之心专访开发团队》)
当时,腾讯曾表示将于 2017 年一季度开放其源代码,为什么超出预期一个季度才开源 Angel 平台?历时半年,Angel 平台在技术方面有哪些更新与优化?是否有重大升级?为此,机器之心专访腾讯数据平台部智能学习平台技术负责人黄明,深入了解新一代 Angel 平台的背后的故事以及技术方面的亮点。
新一代 Angel 平台由腾讯和北京大学联合开发,黄明介绍,这半年来,团队做了大量的重构工作,包括相关自动化单元测试以及中文详细文档准备。在重构过程中,团队还做了两个大动作:一是引入 Spark on Angel,二是把性能优化到比 XGBoost 还快。「这其中的工作量是非常大的,超出了最初的预期,很多事情就这样连带着做了,还好老大们没给太大的压力。一直到 6 月中旬我们觉得项目挺完善了,各个性能比对都充分了,才正式开源了这个平台。一开始,我们并没有想宣传这件事,只在腾讯内部发表了相关文章,没想到机器之心很快就发现了我们的动作,帮助我们把 Github 上的相关信息分享给大家了。」黄明笑着解释道。(详见《腾讯 Angel 1.0 正式版发布:基于 Java 与 Scala 的机器学习高性能计算平台》)
在谈及新一代 Angel 平台时,黄明表示,Spark on Angel 是此次平台升级的一大亮点,而 Spark 只是 Angel 生态圈的第一个成员。「之前业界有过不少关于 Spark on PS 的讨论,Yahoo 也有相关的研究,但是并没开源。有一个小的开源项目 Glint,也是做 Spark on PS 的,但是在性能和功能上都有所欠缺,比如不支持 psFunc,而且也没有人维护。这次腾讯开源 Angel 的时候,直接将 Spark on Angel 也开源了,希望能够带动更多的 Spark 工程师投入到机器学习的领域中,利用 Spark 和 Angel 配合来做机器学习。另外,透露一下,在下一个小版本中,会推出 Spark Streaming on Angel,Angel 也将可以支持在线学习。」
经过反复的改进与迭代,Angel 在性能、功能以及开发者易用性都有了显著的提升,开源前夕,Angel 就已经具备超越 XGBoost 和 Spark 的性能表现。此次升级主要表现在三个方面:
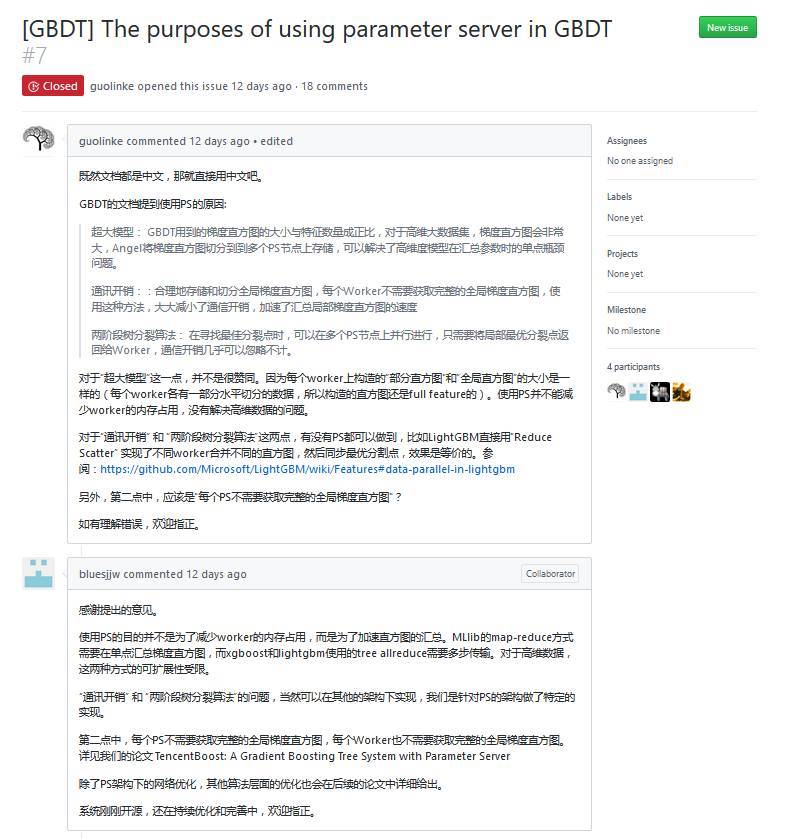
生态性: 引入 PSAgent,支持 PS-Service,便于接入其它机器学习框架
函数性: 融合函数式编程特性,自定义 psFunc,利于开发复杂算法
灵活性: 支持 Spark-on-Angel,Spark 无需修改内核,运行于 PS 模式之上
以下为新一代 Angel 开源平台架构升级以及性能优势方面的具体介绍。
三大架构升级
1.PSService
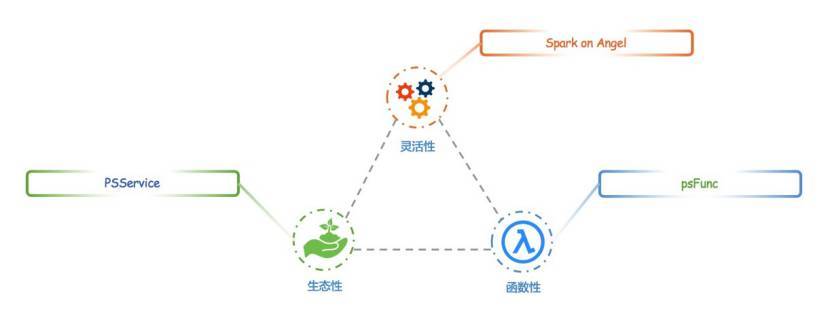
据 Andy 介绍,在新一代的 Angel 开发中,研发团队对系统进行了一次重要升级,引入了 PSAgent,对 PSServer 的服务端进行隔离,从而提供了 PSService 的功能。升级后,系统的架构设计如下:
新加入的中间层 PSAnget 有以下特性:
对外屏蔽 PSServer 中的模型分片,路由以及模型重组等复杂细节,提供封装好的模型操作接口
内置 Hogwild! 机制,包含模型缓存和模型预取等性能优化
提供模型缓存(Cache)的更新和合并的功能,大大降低网络通信开销
PSAgent 的引入使 PSClient 不再直接和 PSServer 打交道,而是通过 PSAgent 进行沟通。这样的调整解耦了 PSServer 和 Worker,使 Angel 具备了 PSService 的能力。同时,Angel 的 PSServer 也不再只服务于 Angel 的 Client,只要能够实现 AngelPSClient 接口,其它机器学习框架也能可以接入 Angel。
PSService 不仅为新一代 Angel 打下了坚实的基础,也从架构的层面上,为接入 Spark 和深度学习计算框架提供了可能。
2.psFunc
提供 Model 的拉取(pull/get)和推送(push/update)是标准 Parameter Server 的一个功能。很多早期的 PS 是在 HBase,Redis 等分布式存储系统的基础上,进行简单的模型更新和获取而搭建的。
但在实际应用中,算法对 PSServer 上参数的获取和更新,却并非这样简单。尤其是在复杂的算法需要实施一些特定的优化时,简单的 PS 系统就无法应对这些需求了。以求取矩阵模型中某一行的最大值为例,如果 PS 系统只有基本的 Pull 接口,那么 PSClient 只能先将该行的所有列都从参数服务器上拉取回来,然后再在 Worker 上计算得到最大值。这个过程会产生许多网络通信开销,对性能造成影响。同样的情况下,如果可以设置一个自定义函数,那么每个 PSServer 就可以先远程计算出 n 个局部最大值,再交换确认全局最大值,只需返回 1 个数值就可以完成任务。这样的方式算产生的计算开销接近,但通信开销却将大大降低。
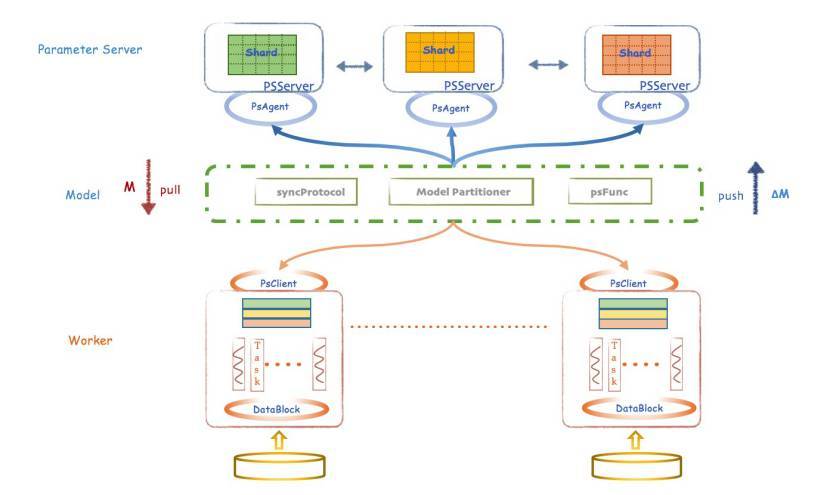
为了解决类似的问题,Angel 引入并实现 psFunc 的概念,对远程模型的获取和更新的流程进行了封装和抽象。这也是一种用户自定义函数(UDF),因与 PS 操作密切相关,也被成为 psFunc,简称 psf,其整体架构如下:
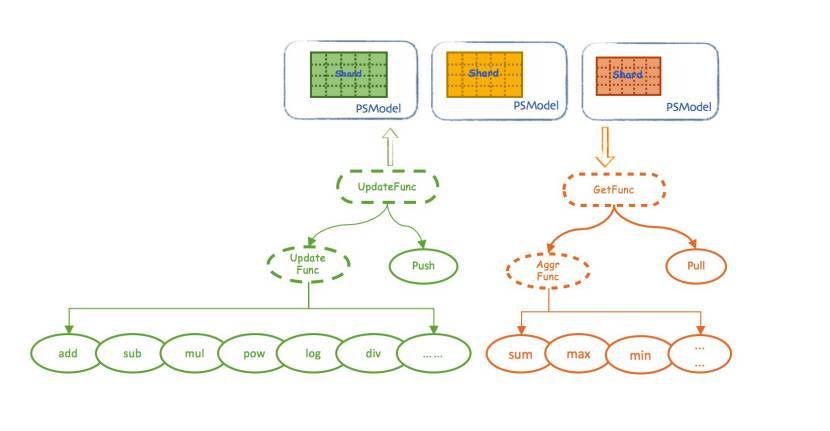
psFunc 的引入促使 PSServer 端也会发生模型计算,相应地,PSServer 也会承担一定的模型计算职责,而不是单纯的实现模型存储功能。「用户可以灵活地自定义自己的算子,合理设计 psFunc 能够大幅度加速算法运行。」黄明解释道。
3.Spark on Angel
Spark 是目前非常流行的分布式内存计算框架,其核心概念是 RDD。不可变性是 RDD 的关键特性之一,它可以规避分布式环境下各种奇怪的复杂并行问题,进而快速开发各种分布式数据处理算法。然而在机器学习的时代,这个设计反而制约了 Spark 的发展。这源于机器学习核心——迭代和参数更新,RDD 的不可变性并不适合参数反复多次更新的需求,因此许多 Spark 机器学习算法的实现都非常的曲折而且不直观。
在 Angel 提供的 PSService 和 psFunc 基础上,Spark 可以充分利用 Angel 的 PS,可以以最小的修改代价,实现高速训练大模型的能力。
Spark on Angel 实现的基本架构设计如下:
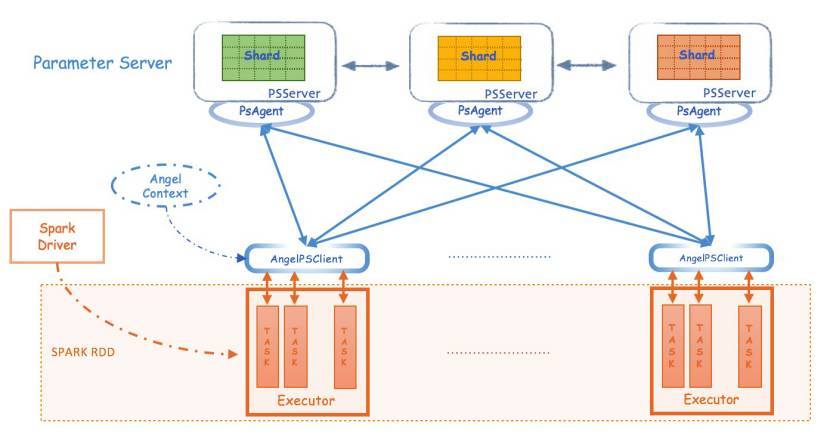
这个实现过程较为灵活,利用插件式设计,对 Spark 没有任何侵入式修改,完全兼容社区 Spark,对原生 Spark 程序不会产生任何影响。它的基本执行流程如下:
启动 SparkSession
初始化 PSContext,启动 Angel 的 PSServer
创建 PSModelPool, 申请到 PSVector
核心实现
在 RDD 运算中,直接调用 PSVector 进行模型更新,让真正运行的 Task 调用 AngelPSClient 对远程 PSServer 进行操作。
终止 PSContext
停止 SparkSession
在线上,基于真实的数据,研发团队对 Spark on Angel 和 Spark 的做了性能对比测试,结果如下:
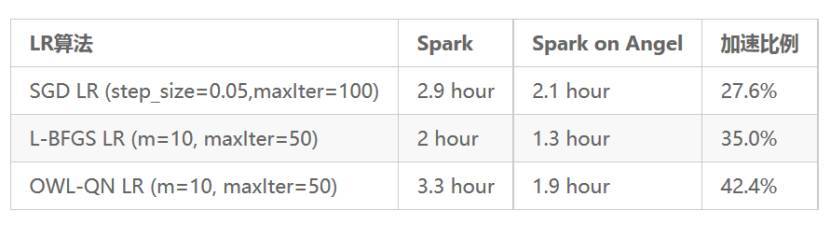
显而易见,Spark on Angel 能轻松获得 30% 甚至更多的加速比,而且越复杂的算法和模型,性能提高的比例越大。虽然 PSServer 会耗费了额外的资源,但是考虑算法编写的便捷以及性能的提升方面,这仍是一个划算、合适的选择。对于 Spark 的老用户,这是低成本切入 Angel 的一个途径,也是算法工程师基于 Spark 实现高难度算法的有效方式。

时间:2018-10-09 22:49 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]Uber开源Manifold:机器学习可视化调试工具
- [数据挖掘]2020 年数据科学就业市场必备的五项技能
- [数据挖掘]吴恩达deeplearning.ai新课上线:TensorFlow移动和web端
- [数据挖掘]30段极简Python代码:这些小技巧你都Get了么
- [数据挖掘]加快数据科学项目的五个自动化工具
- [数据挖掘]BERT, RoBERTa, DistilBERT, XLNet的用法对比
- [数据挖掘]一个案例告诉你如何使用Kyligence + Spark 进行大数
- [数据挖掘]想留住人才?先要管理好数据科学团队
- [数据挖掘]数据处理必看:如何让你的 pandas 循环加快 7180
- [数据挖掘]数据科学中的强大思维
相关推荐:
网友评论:















