基于Spark的大规模机器学习在微博的应用
众所周知,自2015年以来微博的业务发展迅猛。如果根据内容来划分,微博的业务有主信息(Feed)流、热门微博、微博推送(Push)、反垃圾、微博分发控制等。每个业务都有自己不同的用户构成、业务关注点和数据特征。庞大的用户基数下,由用户相互关注衍生的用户间关系,以及用户千人千面的个性化需求,要求我们用更高、更大规模的维度去刻画和描绘用户。大体量的微博内容,也呈现出多样化、多媒体化的发展趋势。
一直以来,微博都尝试通过机器学习来解决业务场景中遇到的各种挑战。本文为新浪微博吴磊在CCTC 2017云计算大会Spark峰会所做分享《基于Spark的大规模机器学习在微博的应用》主题的一部分,介绍微博在面对大规模机器学习的挑战时,采取的最佳实践和解决方案。
Spark Mllib
针对微博近百亿特征维度、近万亿样本量的模型训练需求,我们首先尝试了Apache Spark原生实现的逻辑回归算法。采用该方式的优点显而易见,即开发周期短、试错成本低。我们将不同来源的特征(用户、微博内容、用户间关系、使用环境等)根据业务需要进行数据清洗、提取、离散化,生成Libsvm格式的可训练样本集,再将样本喂给LR算法进行训练。在维度升高的过程中,我们遇到了不同方面的问题,并通过实践提供了解决办法。
【Stack overflow】
栈溢出的问题在函数嵌套调用中非常普遍,但在我们的实践中发现,过多Spark RDD的union操作,同样会导致栈溢出的问题。解决办法自然是避免大量的RDD union,转而采用其他的实现方式。
【AUC=0.5】
在进行模型训练的过程中,曾出现测试集AUC一直停留在0.5的尴尬局面。通过仔细查看训练参数,发现当LR的学习率设置较大时,梯度下降会在局部最优左右摇摆,造成训练出来的模型成本偏高,拟合性差。通过适当调整学习率可以避免该问题的出现。
【整型越界】
整型越界通常是指给定的数据值过大,超出了整形(32bit Int)的上限。但在我们的场景中,导致整型越界的并不是某个具体数据值的大小,而是因为训练样本数据量过大、HDFS的分片过大,导致Spark RDD的单个分片内的数据记录条数超出了整型上限,进而导致越界。Spark RDD中的迭代器以整数(Int)来记录Iterator的位置,当记录数超过32位整型所包含的范围(2147483647),就会报出该错误。
解决办法是在Spark加载HDFS中的HadoopRDD时,设置分区数,将分区数设置足够大,从而保证每个分片的数据量足够小,以避免该问题。可以通过公式(总记录数/单个分片记录数)来计算合理的分区数。
【Shuffle fetch failed】
在分布式计算中,Shuffle阶段不可避免,在Shuffle的Map阶段,Spark会将Map输出缓存到本机的本地文件系统。当Map输出的数据较大,且本地文件系统存储空间不足时,会导致Shuffle中间文件的丢失,这是Shuffle fetch failed错误的常见原因。但在我们的场景中,我们手工设置了spark.local.dir配置项,将其指向存储空间足够、I/O效率较高的文件系统中,但还是碰到了该问题。
通过仔细查对日志和Spark UI的记录,发现有个别Executor因任务过重、GC时间过长,丢失了与Driver的心跳。Driver感知不到这些Executor的心跳,便主动要求Yarn的Application master将包含这些Executor的Container杀掉。
皮之不存、毛之焉附,Executor被杀掉了,存储在其中的Map输出信息自然也就丢了,造成在Reduce阶段,Reducer无法获得属于自己的那份Map输出。解决办法是合理地设置JVM的GC设置,或者通过将spark.network.timeout的时间(默认60s)设置为120s,该时间为Driver与Executor心跳通信的超时时间,给Executor足够的响应时间,让其不必因处理任务过重而无暇与Driver端通信。
通过各种优化,我们将模型的维度提升至千万维。当模型维度冲击到亿维时,因Spark Mllib LR的实现为非模型并行,过高的模型维度会导致海森矩阵呈指数级上涨,导致内存和网络I/O的极大开销。因此我们不得不尝试其他的解决方案。
基于Spark的参数服务器
在经过大量调研和初步的尝试,我们最终选择参数服务器方案来解决模型并行问题。参数服务器通过将参数分片以分布式形式存储和访问,将高维模型平均分配到参数服务器集群中的每一台机器,将CPU计算、内存消耗、存储、磁盘I/O、网络I/O等负载和开销均摊。典型的参数服务器采用主从架构,Master负责记录和维护每个参数服务器的心跳和状态;参数服务器则负责参数分片的存储、梯度计算、梯度更新、副本存储等具体工作。图1是我们采用的参数服务器方案。
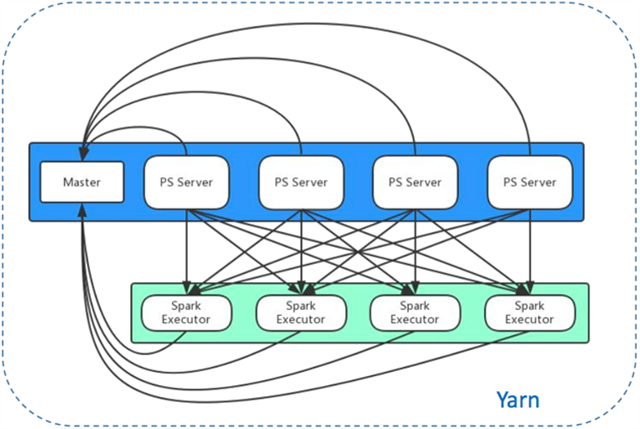
图1 微博参数服务器架构图
蓝色文本框架即是采用主从架构的参数服务器集群,以Yarn应用的方式部署在Yarn集群中,为所有应用提供服务。在参数服务器的客户端,也是通过Yarn应用的方式,启动Spark任务执行LR分布式算法。在图中绿色文本框中,Spark模型训练以独立的应用存在于Yarn集群中。在模型训练过程中,每个Spark Executor以数据分片为单位,进行参数的拉取、计算、更新和推送。
在参数服务器实现方面,业界至少有两种实现方式,即全同步与全异步。全同步的方式能够在理论层面保证模型收敛,但在分布式环境中,鉴于各计算节点的执行性能各异,加上迭代中需要彼此间相互同步,容易导致过早执行完任务的节点等待计算任务繁重的节点,引入通信边界,从而造成计算资料的浪费和开销。全异步方式能够很好地避免这些问题,因节点间无需等待和同步,可以充分利用各个节点的计算资源。虽然从理论上无法验证模型一定收敛,但是通过实践发现,模型每次的迭代速度会更快,AUC的加速度会更高,实际训练出的模型效果可以满足业务和线上的要求。
在通过参数服务器进行LR模型训练时,我们总结了影响执行性能的关键因素,罗列如下:
【Batch size】
即Spark数据分片大小。前文提到,每个Spark Executor以数据分片为单位,进行参数的拉取和推送。分片的大小直接决定本次迭代需要拉取和通信的参数数量,而参数数量直接决定了本地迭代的计算量、通信量。因此分片大小是影响模型训练执行性能的首要因素。过大的数据分片会造成单次迭代任务过重,Executor不堪重负;过小的分片虽然能够充分利用网络吞吐,但是会造成很多额外的开销。因此,选择合理的Batch size,将会令执行性能的提升事半功倍。下文将以Batch size为例,对比不同设置下模型训练执行性能的差异。
【PS server数量】
参数服务器的数量,决定了模型参数的存储容量。通过扩展参数服务器集群,理论上可以无限扩展存储容量。但是当集群大小达到瓶颈值时,过多的参数服务器带来的网络开销反而会令整体执行性能趋于平缓甚至下降。
【特征稀疏度】
根据需要可以将原始业务特征(用户、微博内容、用户间关系、使用环境等)通过映射函数映射到高维模型,以这种方式提炼出区分度更佳的特征。特征稀疏度结合每次迭代数据分片的数据分布,决定了该分片本次迭代需要拉取和推送的参数数量,进而决定了本次迭代所需的计算资源和网络开销。
【PS分区策略】
分区策略决定了模型参数在参数服务器的分布,好的分区策略能够使模型参数的分布更均匀,从而均摊每个节点的计算和通信负载。
【Spark内存规划】
在PS的客户端,Spark Executor需要保证有足够的内存容纳本次迭代分片所需的参数向量,才能完成后续的参数计算、更新任务。
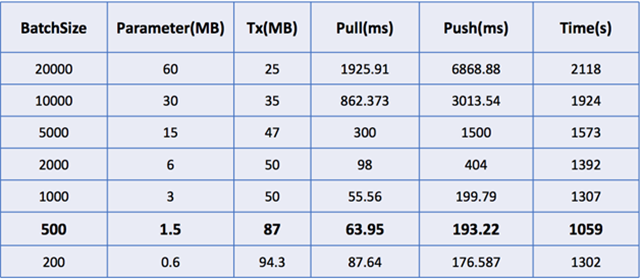
下表为不同的Batch size下,各执行性能指标对比。Parameter(MB)表示一次迭代所需参数个数;Tx(MB)表示一次迭代的网络吞吐;Pull(ms)和Push(ms)分别表示一次迭代的拉取和推送时间消耗;Time(s)为一次迭代的整体执行时间。从表1中可见,参数个数与分片大小成正比、网络吞吐与分片大小成反比。分片越小,需要通信、处理的参数越少,但PS客户端与PS服务器通信更加频繁,因而网络吞吐更高。但是当分片过小时,会产生额外的开销,造成参数拉取、推送的平均耗时和任务的整体耗时上升。
通过参数服务器的解决方案,我们解决了微博机器学习平台化进程中的大规模模型训练问题。众所周知,在机器学习流中,模型训练只是其中耗时最短的一环。如果把机器学习流比作烹饪,那么模型训练就是最后翻炒的过程,烹饪的大部分时间实际上都花在了食材、佐料的挑选,洗菜、择菜,食材再加工(切丁、切块、过油、预热)等步骤。
在微博的机器学习流中,原始样本生成、数据处理、特征工程、训练样本生成、模型后期的测试、评估等步骤所需要投入的时间和精力,占据了整个流程的80%之多。如何能够高效地端到端进行机器学习流的开发,如何能够根据线上的反馈及时地选取高区分度特征,对模型进行优化,验证模型的有效性,加速模型迭代效率,满足线上的要求,都是我们需要解决的问题。在新一期《程序员》“weiflow——微博机器学习流统一计算框架”一文中,我们将为你一一解答。
吴磊,微博算法平台高级工程师,主要负责以Spark为核心的大数据计算框架、机器学习平台的设计和实现。曾任职于IBM、联想研究院,从事数据库、数据仓库、大数据分析相关工作。
张拓宇,微博系统开发工程师,作为主要开发设计人员参与微博大规模机器学习、特征工程等项目,负责计算平台参数服务器和大规模学习算法的研究和工程实现工作。
来源:36大数据

时间:2018-10-09 22:49 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















