GNMT-谷歌的神经网络翻译系统
一、前言
2016年9月份,谷歌发布了基于神经网络的翻译系统(GNMT),并宣称GNMT在多个主要语言对的翻译中将翻译误差降低了55%-85%以上,并将此翻译系统的技术细节在论文(
Google’s Neural Machine Translation System: Bridging the Gap
between Human and Machine Translation
)在展示,在阅读之后收益匪浅。
二、概要
一般来说,NMT【神经网络翻译系统】通常会含用两个RNN【递归神经网络】,一个用来接受输入文本,另一个用来产生目标语句,与此同时,还会引入当下流行的注意力机制【attention mechanism】使得系统处理长句子时更准确高效。但谷歌认为,通常这样的神经网络系统有三个弱点:
训练速度很慢并且需要巨大的计算资源,由于数量众多的参数,其翻译速度也远低于传统的基于短语的翻译系统【PBMT】。
对罕见词的处理很无力,而直接复制原词在很多情况下肯定不是一个好的解决方法。
在处理长句子的时候会有漏翻的现象。
而且GNMT致力于解决以上的三个问题,在GNMT中,RNN使用的是8层(实际上Encoder是9层,输入层是双向LSTM。)含有残差连接的神经网络,残差连接可以帮助某些信息,比如梯度、位置信息等的传递。同时,attention层与decoder的底层以及encoder的顶层相连接,如图:
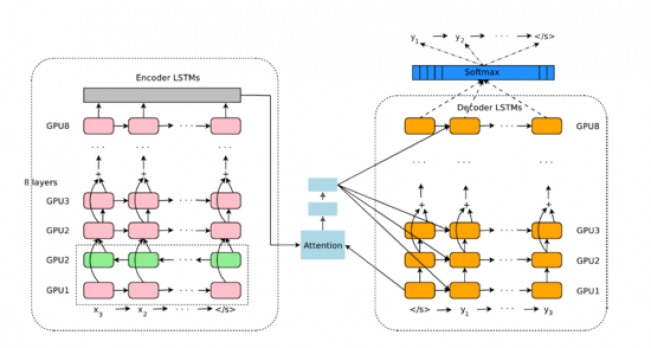
GNMT结构图
为了解决翻译速度问题,谷歌在翻译过程中使用了低精度的算法(将模型中的部分参数限制为8bit)以及使用了TPU。
为了更好的处理低词频的词,谷歌在输入和输出中使用了sub-word units也叫wordpieces,(比如把’higher‘拆分成‘high’和‘er’,分别进行处理)
*在beamsearch中,谷歌加入了长度规范化和奖励惩罚(coverage penalty)使对翻译过程中产生的长度不同的句子处理更高效并且减少模型的漏翻。
在进行了这么多改进之后,谷歌宣称,在英-法,英-中,英-西等多个语对中,错误率跟之前的PBMT系统相比降低了60%,并且接近人类的平均翻译水平。
接下来就详细的看一下神奇的GNMT模型的细节。
三、模型结构
如上图所示,GNMT和通常的模型一样,拥有3个组成部分 -- 一个encoder,一个decoder,和一个attention network 。encoder将输入语句变成一系列的向量,每个向量代表原语句的一个词,decoder会使用这些向量以及其自身已经生成的词,生成下一个词。encoder和decoder通过attention network连接,这使得decoder可以在产生目标词时关注原语句的不同部分。
此外,如我们所想,要使翻译系统有一个好的准确率,encoder和decoder的RNN网络都要足够深,以获取原句子和目标语句中不容易被注意的细节,在谷歌的实验中,没增加一层,会使PPL降低约10%。
关于模型中的attention机制,采用了如下的公式来计算:
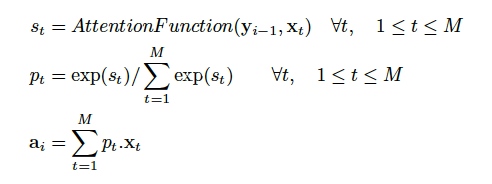
attention的公式
其实在此我有一个疑问,这里最后的a i 是一个向量呢?还是一个标量(一个数值)。从式中看似乎是一个标量,但我在之前理解的是attention是一个跟输入语句单词数量等长的向量。
3.1残差连接
如上面提到的,多层堆叠的LSTM网络通常会比层数少的网络有更好的性能,然而,简单的错层堆叠会造成训练的缓慢以及容易受到剃度爆炸或梯度消失的影响,在实验中,简单堆叠在4层工作良好,6层简单堆叠性能还好的网络很少见,8层的就更罕见了,为了解决这个问题,在模型中引入了残差连接,如图,
残差连接示意图
将第i层的输入与第i层LSTM的隐状态一起,作为第i+1层LSTM的输入,
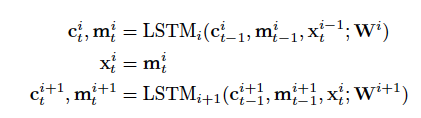
没有引入残差连接的LSTM示意图
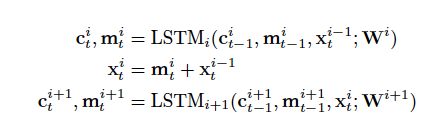
引入残差连接的LSTM示意图
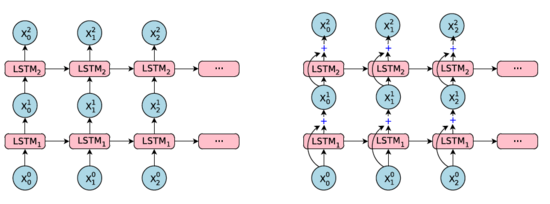
3.2Encoder的第一层双向LSTM
一句话的译文所需要的关键词可能在出现在原文的任何位置,而且原文中的信息可能是从右往左的,也可能分散并且分离在原文的不同位置,因为为了获得原文更多更全面的信息,双向RNN可能是个很好的选择,在本文的模型结构中,只在Encoder的第一层使用了双向RNN,其余的层仍然是单向RNN。
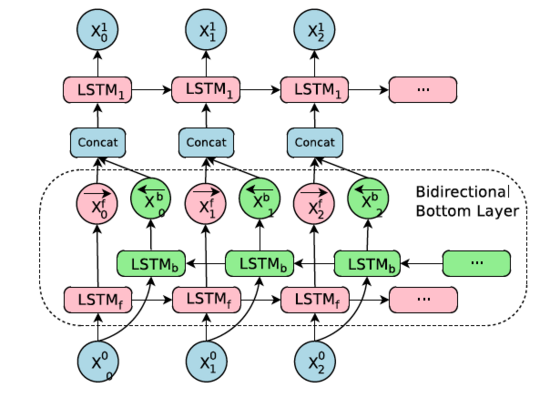
Bi-directions RNN示意图
可以看到,粉色的LSTM从左往右的处理句子,绿色的LSTM从右往左,二者的输出先是连接,然后再传给下一层的LSTM。
3.3模型的平行训练
这一部分主要是介绍模型在训练过程中一些加速的方法。
谷歌同时采用了数据平行和模型平行两种方式以加速训练,数据平行很直接,就是把模型复制并部署n份,每份的参数是共享的,每份训练时都以Batch的形式训练,即同时训练batch-size句话。在谷歌实验中,n通常是10,而batch-size通常是128,然后用Adam和SGD的方法来更新参数。
除了数据平行,实验中还采用了模型平行,即,将每一层网络部署在一个GPU上,如最上方的图所示,这样在Encoder的第一层双向RNN计算完之后,下一时间步不需要等本时间步完全运行完就可以开始,并行计算加速了训练速度。
而之所以不在每一层都是用双向RNN是因为,如果这样会大幅度降低训练速度,因为其只能使用两个GPU,一个作前向信息处理,一个作后向的信息处理,降低平行计算的效率。
在attention的部分,将encoder的输出层与decoder的底层对齐(我的理解应该是输出的tensor纬度一致)来最大化平行计算的效率。(具体是什么原理我还没理解太明白)。
四、数据预处理
神经网络翻译系统在运行过程中通常有一个字数有限的字典,而可能遇到的词是无数的,这就可能造成OOV(out-of-vocabulary)问题,由于这些未知词通常是日期,人名,地名等,所以一个简单的方法就是直接复制这些词,显然在处理非人名等词时着不是最好的解决方案,在谷歌的模型中,采用更好的wordpiece model,也叫sub-word units,比如在“Turing’s major is NLP .”一句经过WPM模型处理之后应该是"Turing ‘s major is NLP ." 另外为了直接复制人名等词,使source language和target language共享wordpiece model,WPM在单词的灵活性和准确性上取得了一个很好的均衡,也在翻译有更好的准确率(BLEU)和更快的翻译速度。
五、训练标准
通常来说,在N对语句对中,训练的目标是使下式最大化:
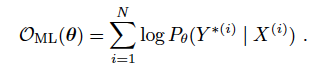
log probabilities of the groud-truth outputs given the corresponding inputs
但这里面有一个问题,翻译中的BLEU值中不能反映对单句翻译质量好坏的奖惩,进一步,因为模型在训练过程中从来没有见过错误的译句,当模型有一个较高的BLEU值时,那些错误的句子仍然会获得较高的概率,所以上式不能明确的对翻译中的错误句子进行惩罚。(对原论文中此处不是完全理解,存疑。)
因此需要对模型有进一步的refinement,但BLEU值是针对两个语料库进行的评测标准,在对单句的评测上效果并不理想,所以谷歌提出了GLEU值,GLEU值的大体意思就是分别计算目标语句和译句的n-grams,(n = 1,2,3,4)数量,然后计算两个集合的交集的大小与原集大小的比值,取较小值。
我用python实现了一下GLEU值的计算,代码如下:

所以,refinement之后模型的评测标准变成了下式:
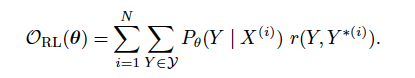
refinement maximum-likelihood
r(Y, Y (i))就是GLEU值的计算部分。GLEU克服了BLEU在单句评测上的缺点,在本实验中,可以和BLEU值可以很好的共同工作。
为了进一步使训练稳定,谷歌对训练标准作了一个线性的结合,也就是下式:

Mixed maximum-likelihood
α在训练中去0.017.
在实际的训练过程中,先使用O ml 的标准训练使模型收敛,然后使用O mixd 的标准进一步提升模型的表现。
六、可量化的模型和翻译过程中的量化
(坦白的说,我并不知道原文中 Quantizable Model and Quantized Inference 应该怎么翻译更好。)
这一部分主要讲的是,由于模型较深且计算量较大,在翻译过程会产生一些问题,所以谷歌在不影响模型收敛和翻译效果的前提下,采取了一系列的优化措施。
带有残差连接的LSTM网络,有两个值是会不断传递计算的,在时间方向上传递的c i t 和在深度方向上传递的x i t ,在实验中过程我们发现这些值都是非常小的,为了减少错误的累积,所以在翻译的过程中,明确的这些值限制在[-δ,δ]之间,因此原LSTM的公式调整如下:
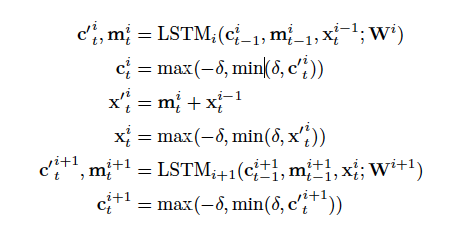
6.1 modified equation
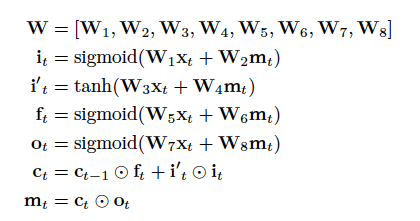
6.2 完整的LSTM计算逻辑
在翻译的过程中,谷歌将6.1和6.2式中所有浮点数运算替代为8位或16位定点整数运算,其中的权重W像下式一样改用8位整数表示:
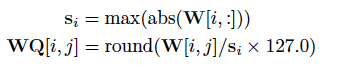
权重W的调整
所有的c i t 和x i t 限制在[-δ,δ]之间且改用16位整数表示。
在6.2中的矩阵乘法(比如W 1 x t )改用8位定点整数乘法,而其他的所有运算,比如sigmoid,tanh,点乘,加法等,改用16位整数运算。
假设decoder RNN的输出是y t ,那在softmax层,概率向量p t 改为这样计算:
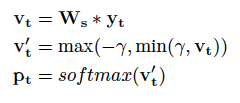
修改后的概率向量计算公式
将 logit v t ' 限制在[-γ,γ]之间且权重W s 和6.2式中的权重W同样使用8位整数表示并在运算过程中使用8位矩阵乘法。
但在softmax层和attention层不采取量化措施。
值得一提的是,除了将c i t 和x i t 限制在[-δ,δ]和将logit v t ' 限制在[-γ,γ],在 训练过程 中一直使用的是全精度的浮点数。其中γ取25.0,δ在训练刚开始取8.0然后逐渐变为1.0 。( 在翻译时,δ取1.0 。 )
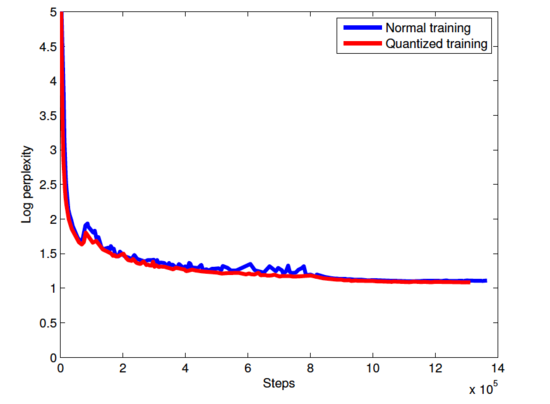
Log perplexity vs. steps
红线代表采用了量化措施的训练过程,蓝线代表普通的训练,可以看到将一些值限制在一定范围内作为额外的规划化措施可以改善模型的质量。
七、Decoder
在翻译的过程中,使用了常规的beam search算法,但引入了两个重要的优化方案,即GNMT中的α和β值。
α值的作用是对译句进行长度规范化,因为选取一个句子的可能性是由剧中每个词的概率取log后相加得到的,这些个对数概率都是负值,因此某种程度上,长句会取得更小的对数概率,这显然是不合理的,因此需要对译句进行长度规划化。
β值的作用是促使模型更好的翻译全句,不漏翻。
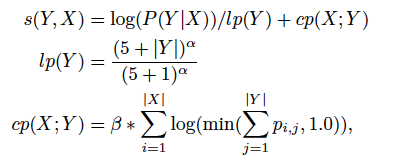
关于α和β值适用的公式
其中s(Y,X)代表译文最终获得的分数,p i j 表示在翻译第j个词时其对应第i个词的attention值。
谷歌在文中还提到两种优化方法:
Firstly, at each step, we only consider tokens that have local scores that are
not more than beamsize below the best token for this step. Secondly, after a normalized best score has
been found according to equation 14, we prune all hypotheses that are more than beamsize below the best
额,其实我没看懂这跟常规的beam search算法有什么不同,望大神指点。。。
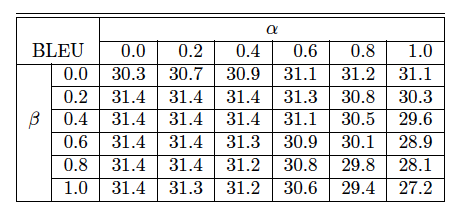
在En-Fr语料库上,不同α和β值对BLEU值的影响
当α和β值取0时相当于不做长度规划化和覆盖范围惩罚,算法退回到最原始的beam search算法,值得一提的是,得到上述BLEU的模型并没有进行只使用了ML进行训练,没有使用RL优化。因为RL refinement已经促使模型不漏翻,不过翻。
在En-Fr语料库上先用ML优化在用RL优化的到的BLEU值与上图的比较
在谷歌实验中,α=0.2和β=0.2,但在我们的实验中,在中英翻译中,还是α=0.6~1和β=0.2~0.4会取得更好的效果
实验过程以及实验结果
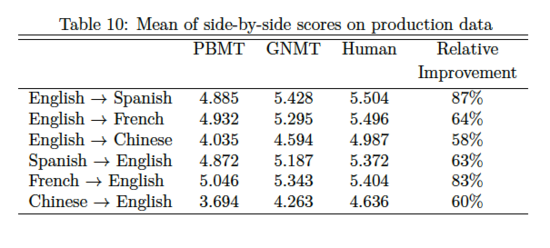
实验结果对比
模型部分基本介绍完了,剩下的第八部分关于实验以及实验结果先贴张图,会继续不定时补充,下一篇文章应该会介绍一下Facebook发布并开源的宣称比GNMT更好更快的FairSeq模型...
论文中提到但未使用的方法
另有一种方法处理OOV问题是将罕见词标记出来,比如,假设 Miki 这个词没有出现在词典中,经过标记后,变成 M

时间:2018-10-09 22:49 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















