一篇文章掌握Sql-On-Hadoop核心技术
1. SQL On Hadoop 分类
1.1 查询延时分类
AtScale 在 2016 年的一篇名为 [15]The Business Intelligence for Hadoop Benchmark 的 SQL On Hadoop 性能测评报告中指出:受查询数据量大小,查询类型 (join 表个数,表大小,是否聚合),并发用户量等因素影响,没有一个 SQL On Hadoop 系统能够在所有场景下胜出。 比如 Impala 和 Presto 在并发场景下性能比较优越,Spark SQL 大表 Join 性能比较好。然而对于所有 SQL On Hadoop 而言,大表 Join 都比较慢。
在众多的 SQL On Hadoop 系统中,有必要对其进行一个分类。一般而言,用户更关心的是查询时延,根据用户提交查询到结果返回的时间长短,将 SQL 查询分为如下三类:batch SQL,interactive SQL,operation SQL, 如图 1。
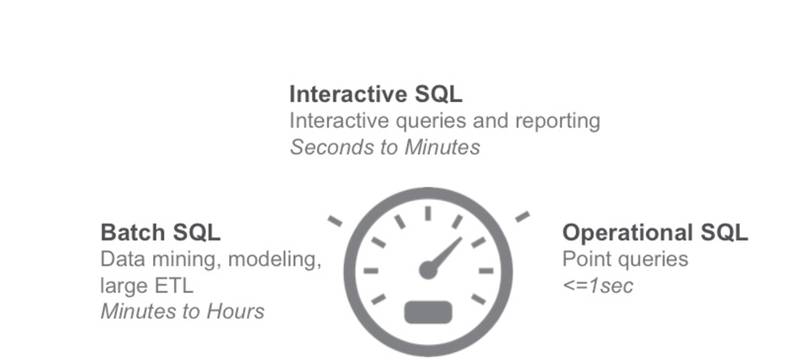
图 1 SQL On Hadoop 分类, 摘自文献 [14]
Batch SQL,Batch SQL 的查询时间通常在分钟,小时级别,一般用于复杂的 ETL 处理,数据挖掘,高级分析。由于 Batch SQL 的查询延时比较高,因此支持查询内 (Intra-query) 容错是该类系统必须具备的属性,查询内容错是指,当节点宕机或者查询内部某个 Task 失败时,系统必须能够重新提交该 task 而不是重新提交整个查询来进行容错。Batch SQL 中最典型的系统是 Hive。Spark SQL 也可以归类到该系统。
Interactive SQL,Interactive SQL 也叫做交互式 SQL 查询,用户通常在同一个表上反复的执行不同的查询,Interactive SQL 的查询时间通常在毫秒级或者秒级以内,一般不超过分钟级别。由于该类系统主要追求低延迟,而不过分强调查询内部容错,所以当某个 task 失败时,可以重新提交该查询以便进行容错,因为重新提交一个 SQL 查询的执行时间通常很短。Interactive SQL 在实现上通常采用 MPP 架构,并且将热点数据缓存到内存中,比如 Presto,Impala,Drill,HAWQ。鉴于 Spark SQL 也具有非常高效的查询速度,Spark SQL 也可以归类到 Interactive SQL 中。
Operation SQL, 通常是单点查询,延时要求小于 1 秒,该类系统主要是 HBase。
1.2 架构分类
1.2.1 MPP 架构
MPP 架构的优点是查询速度快,通常在秒计甚至毫秒级以内就可以返回查询结果,这也是为何很多强调低延迟的系统采用 MPP 架构的原因。
下面重点看下 MPP 架构的缺点,MPP 架构最主要的缺点是不支持细粒度的容错,集群节点数量很难扩展到 100 个以上,如果集群出现落后节点,那么将影响整个系统的查询性能,此外不管 MPP 节点数量的多少,并发查询的数量通常只能达到 20 个左右。
容错,MPP 架构的容错特点是粗粒度容错,不能处理落后节点 (Straggler node)。粗粒度容错是指,某个 task 执行失败将导致整个查询失败,然后系统重新提交整个查询来获取结果。这种容错方式只适用于 Iterative SQL 这种低延迟的工作负载,而不适合 Batch SQL 场景,因为 Batch SQL 查询时间通常在分钟小时级别,重新提价一个查询代价太高。
落后节点,当一个节点执行速度慢于其他节点时,将导致整个系统的查询性能下降。
扩展性:受落后节点的影响,MPP 架构很难扩展到 100 个节点以上。如果某个节点慢于其他节点,那么整个系统的查询性能将受限于这个最慢的节点,而与集群节点数量无关。需要注意的是,在大型集群中落后节点是普遍存在的,随着集群节点数量的增加,落后节点出现的概率也增加,[13] 针对磁盘故障概率的统计如下:
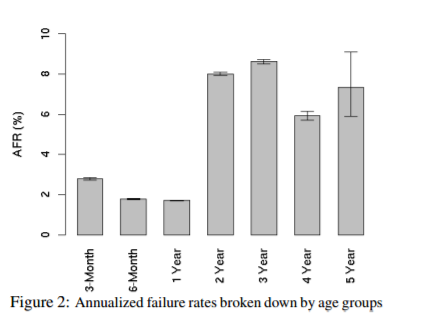
如果集群包含 1000 个未使用一年的磁盘,那么每年将有大约 20 磁盘出现故障,平均每两周就会出现一个故障。当磁盘使用超过一年后,每年磁盘故障出现的概率将达到 8% 左右,平均每周将出现大约两次故障。由于这个原因,MPP 架构很难扩展到 100 个节点以上,一般在 50 个节点左右。
并发,MPP 架构的并发查询数量和集群节点数量无关。MPP 是对称结构,当执行一个查询时,该查询将被调度到集群中的每一个节点执行,这意味着一个包含 4 个节点的 MPP 集群和一个包含 400 个节点的 MPP 集群所支持的并发查询数量是相同的,也就是说,并发查询数量和集群节点数量无关,一般而言,当并发查询个数达到 20 左右时,整个系统的吞吐已经达到满负荷状态。
综上所述,MPP 架构不适合大规模部署,如果需要大规模部署,可以考虑 Spark Sql 这样的系统。
1.2.2 非 MPP 架构
典型的非 MPP 架构有 Hive,Spark Sql。他们分别构建在 MR 和 Spark 之上,优点是集群节点数量可以扩展到几百甚至上千个,支持细粒度容错。缺点是查询速度可能不如 MPP 架构。
2. 运行引擎的设计
2.1. 优化器
目前 SQL On Hadoop 的查询优化器主要有两种:基于规则的 (Rule-Based Optimizer) 和基于代价的 (Cost-Based Optimizer CBO)。基于规则的优化器简单,易于实现,通过内置的一组规则来决定如何执行查询计划,这里不做介绍。
设计一个好的 CBO 优化器非常具有挑战性,一个好的 CBO 依赖于详细可靠的统计信息,比如每个列的最大值,最小值,表大小,表分区信息,桶信息,然而在 SQL On Hadoop 中,通常缺乏可靠的统计结果,代价估计代数,这使得在 SQL On Hadoop 中引入 CBO 很困难。尽管如此,鉴于 CBO 在运行可以更加智能的进行查询优化,仍然有越来越多的 SQL On Hadoop 开始支持 CBO,比如 Hive,Spark SQL(计划中)。
CBO 主要用来优化 shuffle,join,如何尽可能的避免 shuffle,提高 join 执行速度是 CBO 主要关注的问题,其中 Join 的实现方式和 Join 顺序是重点考虑的。在 SQL On Hadoop 主要有四种 join 实现方式:shuffle hash join,broadcast join,Bucket join,cartesian join:
shuffle hash join,在 map 阶段按照 join key 对两个表执行 hash shuffle,这样拥有相同 join key 的元组将 shuffle 到同一个节点,在 reduce 阶段对表进行 join。
broadcast join,当一个大表 join 一个小表时,并且小表可以完全放到内存中,此时可以将小表广播到大表所在的每一个计算节点,然后执行 join。这种 join 方式叫做 broadcast join 或者 map join。Broadcast join 优点是避免了 shuffle,提高 join 性能。
Bucket join, 假设表 A 和表 B 使用 bucket 分区策略存储,并且表 A 和表 B 的 bucket 个数为 n,此时可以按照如下方式 join:bucket 1 of A join bucet 1 of B,......,bucket n of A join bucket n of B。
Bucket join 优点是可以对两个大表执行 join,并且不需要将数据放到内存中,在 Hive 和 Spark2.0 中都支持 Bucket join。
cartesian join,也叫做笛卡儿积 join,对两个表执行笛卡儿积 join,结果集中元素的数量是两个表大小的乘积。比如表 A 有 10 万行,表 B 有 10 万行,那么笛卡儿积 join 之后的表大小将达到 100 万条数据。因此除非到万不得已,否则不会使用笛卡儿积 join。
表的 join 顺序 (Join order) 主要有两种:left-deep tree(下图左),bushy tree(下图右)。一个好的 CBO 应该能够根据 SQL 语句的特点,来自动选择使用 Left-deep tree 还是 bushy tree 执行 join。
Left-deep tree, 如果对 A,B,C,D 执行 join,那么首先 A join B 得到一个临时表 AB 并 AB 物化到磁盘,然后 AB join C 得到中间临时表 ABC 并物化到磁盘,最后 ABC joinD 得到最终结果。可以发现,这种 join 顺序非常简单,缺点是只能串行 join,并且由于产生了大量的中间临时表,因此不太适合 OLAP 中的星型和雪花模型。
bushy tree, 采用 bushy tree 方式,可以并行执行 A join B 和 C joinD。然后将二者的结果 AB 和 CD 进行 join 得到最终结果。Bushy tree 优点是可以并行 join,并且能够很好的处理星型模型和雪花模型。
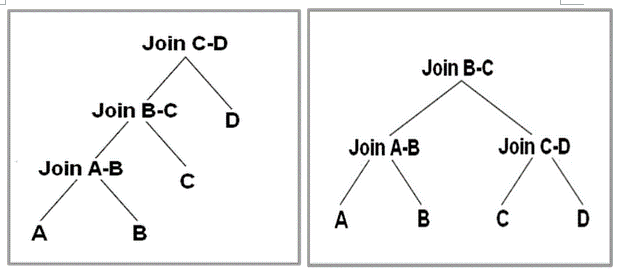
图 2left-deep tree 和 bushy tree, 摘自文献 [16]
2.2. 查询执行引擎
查询执行引擎 (query execution engine) 是 SQL On Hadoop 的核心组件。查询执行引擎的好坏对查询性能的影响非常大。目前主要有两种查询执行:火山执行模型和向量化执行引擎。在后面的向量化执行引擎章节中有详细的介绍。
3. 性能优化
从硬件资源角度将性能优化分为 3 个部分:
磁盘优化:数据本地化,减少中间结果的物化,数据压缩,列存储文件,分区,块级索引
CPU 优化:向量化执行引擎,动态代码生成,轻量级压缩算法,任务启动优化
内存和 CPU 缓存:内存压缩列存储,堆外存储,缓存敏感数据结构和算法
3.1 数据本地化
SQL On Hadoop 设计的一个基本原则是:将计算任务移动到数据所在的节点而不是反过来。这主要出于网络优化的目的,因为数据分布在不同的节点,如果移动数据那么将会产生大量的低效的网络数据传输。数据本地化一般分为三种:节点局部性 (Node Locality), 机架局部性 (Rack Locality) 和全局局部性 (Global Locality)。节点局部性是指将计算任务分配到数据所在的节点上,此时无需任何数据传输,效率最佳。机架局部性是指将计算任务移动到数据所在的机架,虽然计算任务和数据分属不同的计算节点,但是因为机架内部网络传输速度明显高于机架间网络传输,所以机架局部性也是一种不错的方式。其他的情况属于全局局部性,此时需要跨机架进行网络传输,会产生非常大的网络传输开销。
调度系统在进行任务调度时,应该尽可能的保证节点局部性,然后是机架局部性,如果以上两者都不能满足,调度系统也会通过网络传输将数据移动到计算任务所在的节点,虽然性能相对低效,但也比资源空置比较好。
为了实现数据本地化调度,调度系统会结合延迟调度算法来进行任务调度。核心思想是优先将计算任务调度到数据所在的节点 i,如果节点 i 没有足够的计算资源,那么等待几秒钟后如果节点 i 依然没有计算资源可用,那么就放弃数据本地化将该计算任务调度到其他计算节点。
3.2 减少中间结果的物化
在一个追求低延迟的 SQL On Hadoop 系统中,尽可能的减少中间结果的磁盘物化可以极大的提高查询性能。 如下图,Hive 执行引擎采用 pull 获取数据,其优点是可以进行细粒度的容错,缺点是下游的 MapReduce 必须等待上游 MapReduce 完全将数据写入到磁盘后才能开始 pull 数据。Presto 采用 push 方式获取数据,数据完全以流的方式在不同 stage 之间进行传输,中间结果不需要物化到磁盘,从而使得 presto 具有非常高效的执行速度,缺点是不能支持细粒度的容错。
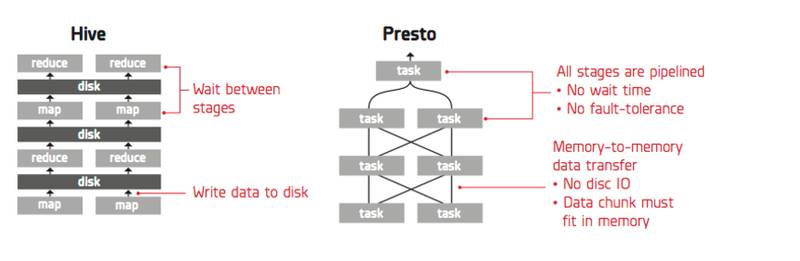
图 3push 和 pull
3.3 列存储
传统的关系存储模型将一个元组的列连续存储,即使只查询一个列,也需要将整个元组读取出来,可以发现,当查询只有少量列时,性能非常低。
列存储的思想是将元组垂直划分为列族集合,每一个列族独立存储,列族可以退化为只仅包含一个列的平凡列族。当查询少量列时,列存储模型可以极大的减少磁盘 IO 操作,提高查询性能。当查询的列跨越多个列族时,需要将存储在不同列族中列数据拼接成原始数据,由于不同列族存储在不同的 HDFS 节点上,导致大量的数据跨越网络传输,从而降低查询性能。因此在实际使用列族时,通常根据业务查询特点,将频繁访问的列放在一个列族中。
在传统的数据库领域中,人们已经对列存储进行了非常深刻的研究,并且很多研究成果已经被应用到工业领域,其中包括轻量级压缩算法,直接操作压缩数据,延迟物化,向量化执行引擎。可是纵观目前 SQL On Hadoop 系统,这些技术的应用仍然远远的落后于传统数据库,在最近的一些 SQL On Hadoop 中已经添加了向量化执行引擎,轻量级压缩算法,但是诸如直接操作压缩数据,延迟解压等技术还没有被应用到 SQL on Hadop 系统。关于列存储的更多内容可以参见 [20]。
列存储压缩
列存储压缩算法具有如下特点:
压缩比 列存储模型具有非常高的压缩比,通常可以达到 10:1,而行存储压缩比通常只有 4:1。如图 4:
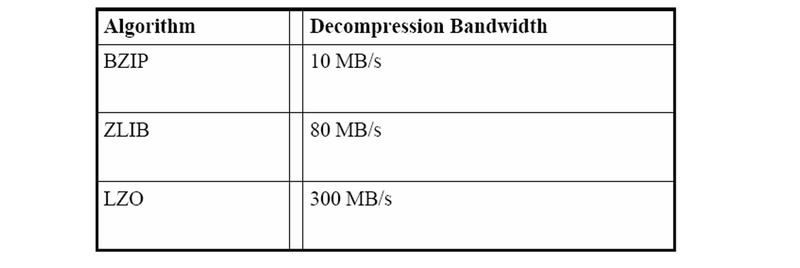
图 4 重量级压缩算法
轻量级压缩算法 (Leight-Weight Compression) 轻量级压缩算法是 CPU 友好的。行存储模型只能使用 zip,lzo,snappy 等重量级压缩算法,这些算法最大的缺点是压缩和解压缩速度比较慢,通常每秒只能解压至多几百兆数据。相反,列存储模型不仅可以使用重量级压缩算法,还可以使用一些非常轻量级的压缩算法,比如 Run-length encode,Bit Vector。轻量级压缩算法不仅具有较好的压缩比,而且还具有非常高的压缩和解压速度。目前在 ORC File 和 Parquet 存储中,已经支持 Bit packing,Run-length enode,Dictionary encode 等轻量级压缩算法。
直接操作压缩数据 (Operating Directly on Compressed Data) 当使用轻量级压缩算法时,可能无需解压即可直接获取计算结果。例如:Run Length Encode 算法将连续重复的字符压缩为字符个数和字符,比如 aaaaaabbccccaaaa 将被压缩为 6a2b4c4a,其中 6a 表示有连续 6 个字符 a。现在假设一个某列包含上述压缩的字符串,当执行 select count(*) from table where columnA=’a’时,不需要解压 6a2b4c4a,就能够知道 a 的个数是 10。
需要注意的是,由于行存储只能使用重量级压缩算法,所以直接操作压缩数据不能被应用到行存储。
延迟解压 parquet 中的数据按块存储,每个块存储了最小值,最大值等轻量级索引,比如某个块的最小值最大值分别是 100 和 120,这表明该块中的任意一条数据都介于 100 到 120 之间,因此当我们执行 select column a from table where v>120 时,执行引擎可以跳过这个数据块,而不必将其解压再进行数据过滤。相反,在行存储中,必须将数据块完整的读取到内存中,解压,然后再进行数据过滤,导致不必要的磁盘读取操作。
3.4 块级索引
传统数据库使用索引来优化查询性能,然而受限于 HDFS block 的放置策略,使用索引来优化 SQL On Hadoop 不是一件容易的事情。目前大部分 SQL On Hadoop 系统都不支持全局索引,取而代之使用的是块级索引,比如 Hive Index,ORC File,Parquet。块级索引的思想是在每一个数据块中添加一些诸如最大值,最小值的轻量级索引,当 SQL 引擎扫描 HDFS 文件时,可以跳过不符合条件的 Block,从而减少磁盘 IO 提高查询性能。如下图,在 ORC File 中,每一个 Stripe 都包含一个 Index Data,Index Data 中存储了列的最大值,最小值。当执行引擎执行 filter 这种查询时,只需要读取 Index Data 就行,如果符合条件就读取 Row Data,否则可以直接跳过 Row Data 的读取,从而减少磁盘 IO,提高查询性能。
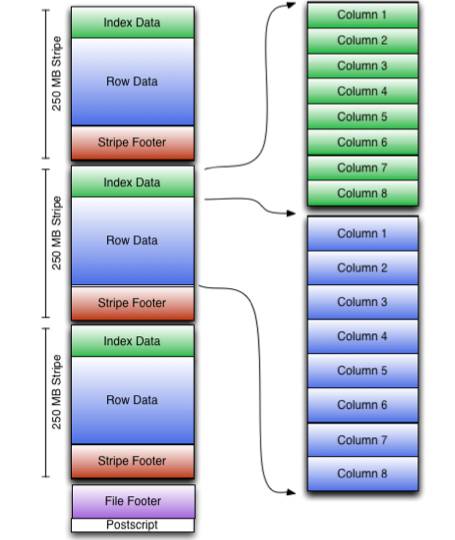
图 3-3 ORC Storage
最大值,最小值这样的统计索引主要用于优化范围查询性能,对于单点查询通常可以使用布隆过滤器作为索引,布隆过滤器可以在数据量非常大的情况下快速的查询数据。

时间:2018-10-09 22:47 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















