浅谈:Hadoop基础之MapReduce
1. Hadoop集群的配置安装(非安全模式)
1.重要的配置文件:
(1)Read-only default configuration:
core-default.xml
hdfs-default.xml
yarn-default.xml
mapred-default.xml
(2)Site-specific configuration:
etc/hadoop/core-site.xml
etc/hadoop/hdfs-site.xml
etc/hadoop/yarn-site.xml
etc/hadoop/mapred-site.xml
(3)Hadoop Daemon Configuration:
HDFS daemons:
NameNode
SecondaryNameNode
DataNode
YARN damones:
ResourceManager
NodeManager
WebAppProxy
2. 配置Hadoop Daemons的环境变量
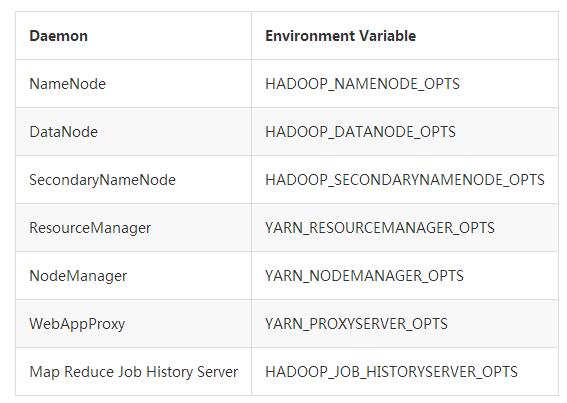
3.Hadoop Daemon配置

4.HDFS相关操作
hadoop fs
- appendToFile
- cat
- chgrp chmod chown
- copyFromLocal copyToLocal
- count
- cp
- df du dus
- find
- get
- help
- ls lsr
- mkdir
- moveFromLocal
- moveToLocal
- mv
- put
- rm rmdir rmr
- touchz
- usage
2.MapReduce理论和实践
MapReduce的输入输出类型
(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)
1.Mapper:
1.多少个Map合适?
Map的数量是根据输入的总大小确定的,也就是输入文件的总块数
最佳实践:
每个节点10~100个map
2.Reducer:
实现将Map的输出结果按照相同key进行归约为更小的值的集合
1. 三个阶段:
1)Shuffle
通过HTTP协议取得所以Mapper输出结果的相关分区
2)Sort
通过key对Reducer的输入进行分组
3)reduce
Reducer的输出结果通过write写入到文件系统中
Reducer的输出没有被排序
2. Reduce的数量
0.95/1.75*(节点数 * 每个节点最大的容器数量)
如果设置为0,Mapper的输出结果直接写入文件系统
3. Partitioner
控制map输出结果中key的分区
HashPartitioner是默认的Partitioner
4. Counter
Mapper和Reducer中实现计数的工具
3. Job的配置
1. Job中可以实现的配置
执行Mapper、Combiner、Partitioner、Reducer、InputFormat、OutputFormat的实现类
2. FileInputFormat显示输入文件的集合
FileInputFormat.setInputPaths(Job, Path…)
FileInputFormat.addInputPath(Job, Path)
FileInputFormat.setInputPaths(Job, String…)
FileInputFormat.addInputPaths(Job, String)
3. FileOutputFormat显示输入文件的集合
FileOutputFormat.setOutputPaths(Job, Path…)
FileOutputFormat.addOutputPath(Job, Path)
FileOutputFormat.setOutputPaths(Job, String…)
FileOutputFormat.addOutputPaths(Job, String)
4. 其他配置
comparator、DistributedCache、Compress、Execute Manner、MaxMapAttempts
可以使用Configuration.set(String,String)实现配置
4.任务的执行和环境
1. 内存管理
用户/管理员可以指定加载子任务时的最大虚拟内存
2. Map的参数
Map输出的结果将会被序列化到缓冲区中,元数据将被存储在缓冲区中
当Map持续有输出结果时,序列化的缓冲区或者元数据超出了临界值,此时缓冲区中的数据将被排序并写入到磁盘中
3. Shuffle/Reduce参数
每一个Reduce通过Partitioner使用HTTP分区到内存中,再定期地合并这些数据到磁盘中
如果Map的输出结果被压缩了,那么么一个输出都将被压缩到内存中
5.Job的提交和监控
1. 检查Job规格的输入输出
2. 为Job计算InputSplit的值
3. 为Job的分布式缓存设置必要的叙述信息(可选)
4. 复制Job的Jar和配置文件到文件系统的MapReduce的系统目录
5. 提交Job到ResourceManager以及监控Job的状态(可选)
用户和查看执行的历史记录:
$ mapred job -history output.jhist
$ mapred job -history all output.jhist
总而言之,用户使用Job创建应用、描述Job的详细信息、提交Job、监控Job的运行状态
6. JobControl
1. Job.submmit():提交任务到集群并立即返回
2. Job.waitForCompletion(boolean):提交任务到集群,并等待执行完成
7. Job的输入
1. InputFormat描述了MapReduce的Job的指定输入
1. 验证Job指定的输入
2. 将输入文件切分成逻辑上的InputSplit的实例,每一个实例再分配给独立的Mapper
3. 提供RecodeReader的实现类来收集被Mapper处理的逻辑InputSplit输入记录
4. InputFormat的默认实现类是:TextInputFormat
2. InputSplit
1. 代表的是被每一个独立的Mapper处理后的数据
2. 代表的是面向类型的输入视图
3. FileSplit是默认的IputSplit
3. RecodeReader
1. 从InputSplit中读取<key,value>对
2. 将由InputSplit提供的面向类型的输入视图转换成Mapper的实现类进行处理
8. Job的输出
1. OutputFormat描述了MapReduce的Job的指定输出
1. 验证Job指定的输出,如:检查Job的输出目录是否存在
2. 提供RecodeWriter实现类用来写Job的输出文件,存储在文件系统中
3. OutputFormat的默认实现类是:TextOutputFormat
2. OutputCommitter
1. 描述的是MapReduce的Job的指定的输出
2.处理过程
1. 在初始化期间设置Job,如:在Job的初始化期间创建临时的输出目录
2. 在Job执行完成后清理Job,如:在Job执行完成之后,移除临时目录
3. 设置任务的临时输出目录,在任务的初始话阶段完成
4. 测是否有任务需要提交
5. 任务输出的提交
6. 丢弃任务的提交.如果任务已经失败或者进程被杀掉,则输出将会被清理,如果这个任务没有被清理,则另外一个带有相同attempt-id的任务将会被加载执行清理
3. OutputCommitter默认的实现类是FileOutputCommitter,Job初始化/清理任务在Map和Reduce容器中
3. RecodeWriter
1. 将output<key,value>对写到输出文件中
2. RecodeWriter的实现类将Job的输出写入到文件系统中
9. 其他有用的特性
1. 提交Job到队列中
1.队列作为Job的集合,允许系统提供指定的功能,例如:队列使用ACLs控制哪个用户可以提交Job
2. Hadoop有一个强制的队列,称为default.队列的名称在Hadoop的配置文件中进行定义
mapreduce.job.queuename
3. 定义队列的方式
1. 设置mapreduce.job.queuename
2. Configuration.set(MRJobConfig.QUEUE_NAME,String)
4. 队列的设置是可选的,如果没有设置,则使用默认的队列default
2. 计数器
1. Counters代表了全局计数器,可以被MapReduce框架或者应用程序进行定义。每一个计数器可以是任意的Enum类型,一个特殊的Enum的计数器被绑定进Counters.Group类型的组中
2. 应用程序可以定义任意的计数器,可以通过 Counters.incrCounter(Enum,long)或者Counters.incrCounter(String,String,long)进行更新,然后这些计数器被框架进行全局范围的聚合
3. 分布式缓存
1. 有效地描述了执行文件的、大型的、只读的
2. 是MapReduce框架提供的应用程序必须的缓存文件(text、archives、jars)的工具
3. 应用程序在Job中通过url(hdfs://)的形式指定可以被缓存的文件
4. 调试
1. 当MapReduce的任务失败时,用户可以运行一个debug脚本去执行任务,这脚本可以访问任务的标准输出、标准错误目录以及JobConf
2. 用户使用DistributedCache去分发和创建脚本的符号链接
3. 提交脚本的方式
1. 设置mapreduce.map.debug.script、mapreduce.reduce.debug.script
2. Configuration.set(MRJobConfig.MAP_DEBUG_SCRIPT,String)
Configuration.set(MRJobConfig.REDUCE_DEBUG_SCRIPT,String)
5. 数据压缩
1. MapReduce提供了写应用程序为Map的输出以及Job的输出指定压缩方式的工具
2. 中间输出结果
应用程序可以控制Map中间结果的压缩
Configuration.set(MRJobConfig.MAP_OUTPUT_COMPRESS,boolean)
Configuration.set(MRJobConfig.MAP_OUTPUT_CODEC,Class)
3. Job输出结果
FileOutputFormat.setCompressOutput(Job,boolean)
FileOutputFormat.SetOutputCompressorClass(Job,Class)
6. 跳过坏的记录
Hadoop提供了在处理Map输入过程中某些坏记录的一种方式

时间:2018-10-09 22:44 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















