基于Kafka Streams构建广告消耗预测系统
Pinterest 广告工程团队的宗旨是为我们的广告合作商提供最优质的服务体验,而广告超投,是我们极力要解决的问题之一。在Pinterest,我们使用了 Kafka Streams ,可以实现把广告消耗的预测数据在数秒钟的时间内发送给数千个广告投放服务。本文将会先解释什么是超投,然后分享一下我们是如何使用 Kafka Streams 构造预测系统来提供近实时的预测消耗数据、从而降低超投的。
关于超投
当广告主的预算耗尽时,如果他们的广告被继续投放,这多出来的投放部分将无法再进行收费,这种现象被称之为超投。超投会减少其他还有预算盈余的广告主的广告展现机会,从而降低了他们的产品和服务触及潜在顾客的机会。
要降低超投率,应从两个方面着手:
- 计算实时消耗:广告曝光展示的信息应在数秒内反馈给广告系统,系统才能及时关闭那些已耗尽预算的广告计划。
- 进行消耗预测:除了让已发生的消耗数据及时传达以外,系统还应具备预测未来消耗的能力,在预计某些计划快要达到预算上限的时候,应降低它们的投放速度,从而使计划平滑地到达预算上限。因为已经投放出去的广告会停留在用户界面上,用户依然可以对它进行操作。这种行为的滞后性会让短时间内的广告消耗难以准确地衡量。而这种自然延迟是不可避免的,我们唯一能确信的只有广告投放事件。
我们举个例子来详细说明一下。假设有一个能提供广告投放的互联网公司,广告主X向该公司购买了出价为$0.10元/曝光 、预算为$100元/天的广告服务。这意味着该广告每天最多曝光1000次。

该公司为广告主快速实现了一个简单明了的投放系统:
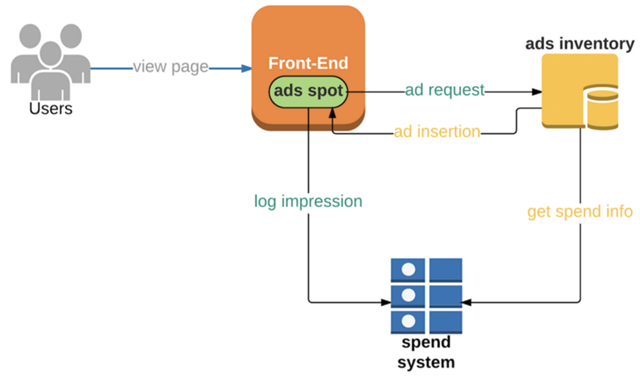
当网站上出现新的广告展现机会时,前端会向广告库(ad inventory)请求一条广告。广告库根据广告主X的剩余预算来决定是否投放他们的广告。如果预算仍然充足,广告库将通知前端进行一次广告投放(比如在用户端APP的一个广告位上展示出来)。当用户浏览了该广告后,一个曝光事件会发往计费系统。
然而,当该公司检查他们的收入时,发现事情的进展与预想的并不一样。
广告主X的广告实际展示了1100次,由于预算只有$100,因此平均每次曝光的价格实际只有$0.09元。比计划多出来的100次曝光相当于是免费投放了,而且这些曝光机会本来可以用来展示其他广告主的广告。这就是业界常谈的超投问题。
那么为什么会发生超投?在这个例子中,我们假设是由于结算系统的响应时间太长所导致的。假设系统对一次曝光的处理有5分钟的延迟,从而导致了超投。因此,这个互联网公司采取了一些优化手段来提高了系统性能,结果成功地多赚了$9元!因为它把原本100次无效曝光中的90次让给了其他预算充足的广告主,从而把超投率降低到10/1000 = 1%。
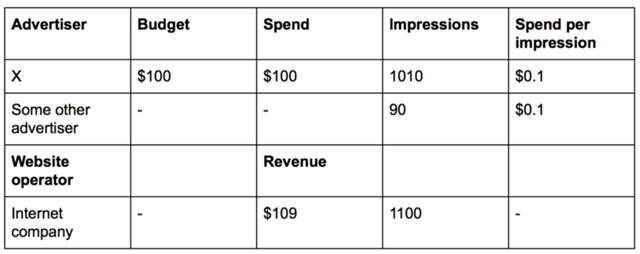
不久之后,另一位广告主Y也联系了这家公司,并希望以$100元/天的预算、$2.0元/点击(例如,一个用户通过点击广告链接到达广告主Y自己的网站)、最多每天50次点击的价格购买广告。这家公司把广告主Y加到他们的广告投放流程里,并在他们的系统增加了点击事件的跟踪。
一天下来,这家公司的广告系统再次发生了超投。

结算下来,广告主Y竟然得到了10个免费点击!而这家互联网公司发现,即使结算系统处理速度足够快,但却无法预知一个投放出去的广告是否会被点击,由于缺乏这些未来的消耗信息,超投将永远都无法避免。
本例子中的主人公最后找到了一个非常聪明的解决办法:给每个广告主计算预测消耗。预测消耗指的是已经投放出去了但尚未发生消耗的那部分。如果实际消耗+预测消耗>每日预算,则停止该广告主的广告投放。
构建预测系统
初衷
我们的用户每天在Pinterest上进行浏览以获取新的灵感:从个性化推荐,到搜索,再到运营推荐位。我们需要构建一个兼具可靠性和可扩展性的广告系统来进行广告投放,并确保利用好我们广告主的每一笔预算。
需求
我们着手设计了一个消耗预测系统,系统目标如下:
- 能处理不同的广告类型(曝光、点击)
- 必须具备每秒能处理数以万计的事件的能力
- 能向超过1000个消费者广播更新消息
- 端到端的延迟不能超过10秒
- 保证100%的运行时间(Uptime)
- 在工程上应尽量保持轻量和可维护性
为什么选择Kafka Streams
我们评估过不同类型的流式服务,其中也包括 Spark 和 Flink 。这些技术在数据规模上都能满足我们的要求,但对我们来说,Kafka Streams还具备了一些特殊的优势:
- 毫秒级延迟:Kafka Streams提供毫秒级的延迟保证,这一点是Spark和Flink做不到的
- 轻量:Kafka Streams是一个没有重度外部依赖(比如专用集群)的Java应用,这会减轻我们的维护成本。
具体实施
下图在高层次上展示了加入了消耗预测之后的系统结构:
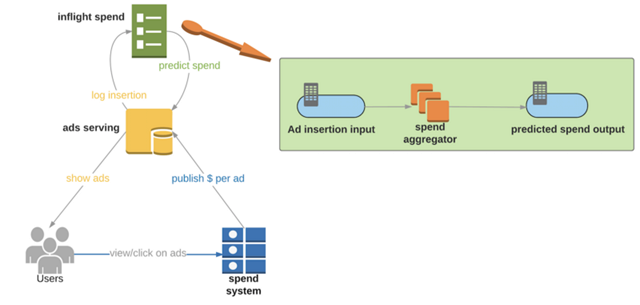
- 广告投放系统(Ads serving):负责分发广告到用户端、记录广告投放、并从消耗预测服务(”inflight spend” service)中获取预测消耗数据。
- 结算系统(Spend system):对广告事件进行聚合并把每个广告主的当前消耗信息告知给广告投放系统。
- 消耗预测服务(Inflight spend):
- 广告投放记录(Ad insertion input):每发生一次投放,投放系统应向“input” topic发送如下消息:{key: adgroupId, value: inflight_spend},其中:
- adgroupId是指在相同的预算约束下的广告组的id
- inflight_spend = price * impression_rate * action_rate,其中:
- price: 当前广告的出价
- impression_rate:广告从投放到曝光的转化率的历史经验值。注意并不是每次投放的广告都一定能被曝光给用户
- action_rate:对按点击付费的广告主来说,这表示用户点击这条广告的概率;对按曝光付费的广告主来说,这个值为1
- 消耗聚合器(spend aggregator):订阅 “input” topic 并利用Kafka Streams对每个 adgroup 进行消耗数据的聚合。我们使用了一个10秒的窗口(window) 来计算每个 adgroup 的预测消耗。而“output” topic会被投放系统进行消费,当收到新的消息时,投放系统会更新预测消耗的数据。
- 广告投放记录(Ad insertion input):每发生一次投放,投放系统应向“input” topic发送如下消息:{key: adgroupId, value: inflight_spend},其中:
在实际应用中,我们的消耗预测的准确率非常高。在整个预算预测系统上线之后,我们的超投率明显下降了。下图是我们的实际消耗与预测消耗的一个对比测试结果样例。
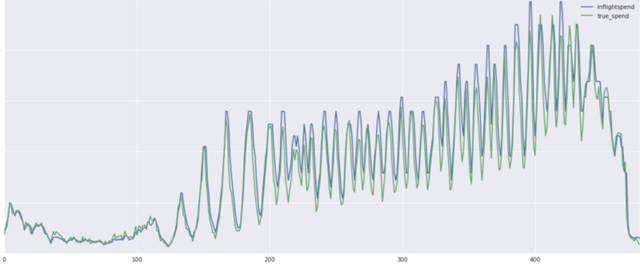
说明:图中的横轴是以3分钟为单位的时间轴;纵轴表示单位时间内的消耗。其中蓝线表示预测消耗,绿线表示实际消耗
一些经验
- 窗口(Window)如果取得不好会严重影响性能。我们在使滚动窗口(tumbling windows)代替原有的跳跃窗口(hopping windows)后得到了18倍的性能提升。最初我们的实现是使用跳跃窗口去计算3分钟内的预测消耗。在我们的实际案例中,一个窗口的大小是3分钟,前进步长是10秒,这样就会产生180秒 / 10秒 = 18个开放窗口。每一个通过Kafka Streams处理的事件会同时更新到18个窗口中,导致很多不必要的计算。为了解决这个问题,我们把跳跃窗口改成了滚动窗口。相比起跳跃窗口,滚动窗口的特点是每个窗口之间不会互相重叠,意味着每收到一个事件只需要更新一个窗口就可以了。因为把更新操作从18减到了1,因此这个窗口类型更换的操作使整体吞吐量增加了18倍。
- 信息压缩策略:为了降低对消费者广播的数据量,我们对 adgroup ID进行了差分编码,并使用查找表存储消耗数据。经过压缩后,我们把信息传输大小压缩到原有的四分之一。
结论
使用Apache Kafka Streams来构建预测消耗系统是我们广告基础组件的一个新的尝试,而该系统也达到了高效、稳定、高容错与可扩展的要求。我们计划在未来将会持续探索由Confluent推出的 Kafka 1.0 和 KSQL 并应用到系统设计上。

时间:2018-10-09 22:42 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















