在数据预处理阶段,特征的标准化有哪些方法?
特征标准化(Feature Standardization)的作用是将样本数据中的每一列特征缩放到一个统一的尺度。方法有很多种,我列几个最常用的。
1. 最大值最小值标准化
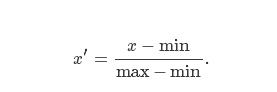
xx是原始数值,x′x′是标准化之后的数值。标准化之后,该列所有的数都将会在[0,1][0,1]之间。当然我们可以稍作调整,把数据缩放到[−1,1][−1,1]的尺度上。
其中![]() 。注意以上提到的最大值、最小值,都是指该列的最大值、最小值。
。注意以上提到的最大值、最小值,都是指该列的最大值、最小值。
2. 正态标准化
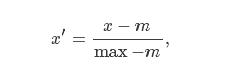
其中μμ和σσ分别是这列数据的均值和标准差。这个过程就和把一个正态分布标准化的过程是一样的,所以也称作正态标准化(Normalization)。根据正态分布的3σ3σ-原则,我们可以预计,在正态标准化之后,比较接近正态分布的数据在标准化后基本上都会在[−3,3][−3,3]之间。
3. 分位数标准化
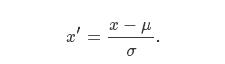
其中IQRIQR是四分位距,也就是第三四分位(3rd quartile)和第一四分位(1st quartile)的差,Median是这一列的中位数。分位数标准化后的数据尺度和数据本身的分散程度相关,但是通常也是在[−3,3][−3,3]的范围内。
4. 范数标准化
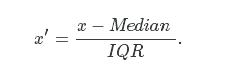
XX是这一列所有的数,∥X∥∥X∥是这一列的范数,可以取1-范数,也可以取2-范数。对特征进行范数标准化之后,这列所有的数值都会是在[0,1][0,1]之间。

时间:2018-10-09 22:41 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















