hadoop|计算框架从MapReduce1.0到Yarn
前面介绍了hadoop的分布式存储框架(HDFS),这个框架解决了大数据存储的问题,这是第一步。知道海量数据如何存储后,脚步不能停留,下一步要设计一个框架,用来玩(计算)这些数据时,资源(计算机集群)该如何调度,比如已知1PB的数据存储在了集群(1000台电脑组成)中的10台计算机(DataNode)中,现在要对这些数据进行Map和Reduce计算,该如何做呢?
在理解以下知识前,需要理解一些知识点。任何应用,比如打开一个word文档,打开QQ,都会占用一定的系统资源(CPU,内存,网络资源等),也就是应用要想正常运行就必须分配给它一定的资源,是谁负责分配给QQ软件资源的,一般都是操作系统内核中的资源调度器。
MapReduce1.0计算框架
通俗地讲,首先找到HDFS中的NameNode,因为这个节点可以提供我们1PB的数据都分布存储在哪些计算机中,找到后,直接去这些计算机上进行map和reduce计算就行了。
知道这个基本目标后,理解MapReduce的计算框架就会很简单,因为分布式框架的基本思想一般是Master-Slave模式,所以它也不例外,拿出一个进程作为Master,就是JobTracker,运行和监控MapReduce的Job,负责将Task分配给TaskTracker,TaskTracker是什么?
TaskTracker是一个hadoop计算进程,运行在hadoop集群的DataNode节点上。TaskTracker的主要任务是运行JobTracker分配给它的实际计算任务,如运行Map、Reduce函数,Shuffle过程。TaskTracker任务具体运行在一组slots上,slots的数量可以配置,一般slots的数量会配置成和这台机器的CPU核心数量一致,TaskTracker被分配的task数量决定于当前还有多少个空闲的slots。当TaskTracker收到JobTracker分配的一个Task时,JobTracker会为这个Task单独启动一个jvm进程,也就是说,每个map、reduce任务都会单独运行在一个jvm进程中。TaskTracker在运行task的过程中会向JobTracker发送心跳信息,以此报告给JobTracker自己是否还活着。
当一个client向JobTracker提交任务时,具体过程如下:
client提交任务,JobTracker会接收Job请求;
JobTracker根据Job的输入参数向NameNode请求包含这些文件数据块的DataNode节点列表;
JobTracker确定Job的执行计划:确定执行此job的Map、Reduce的task数量,并且分配这些task到离数据块最近的节点上;
JobTracker提交所有task到每个TaskTracker节点。TaskTracker会定时向JobTracker发送心跳,若一定时间没有收到心跳,JobTracker认为这个TaskTracker节点失败,然后JobTracker会把此节点上的task重新分配到其它节点上;
一旦所有的task执行完成,JobTracker会更新job状态为完成,若一定数量的task总数执行失败,这个job就会被标记为失败;
JobTracker发送job运行状态信息给Client端,完成闭环。
MapReduce1.x的主要缺点
在MapReduce1.x中,JobTracker同时负责job的监控和系统资源的分配;Hadoop架构只支持MapReduce类型的job,所以它不是一个通用的框架,JobTracker和TaskTracker组件是深度耦合的。
根据设计模式中单一职责的原则,在MapReduce2.x,即Yarn中得到了解决,下面看下Yarn框架。
MapReduce2.0(Yarn)框架
在Yarn中把job的概念换成了application,因为在新的Hadoop2.x中,运行的应用不只是MapReduce了,还有可能是其它应用如一个DAG(有向无环图Directed Acyclic Graph,例如storm应用),还能很方便的管理诸如Hive、Hbase、Pig、Spark/Shark等应用。
这种新的架构设计能够使得各种类型的应用运行在Hadoop上面,并通过Yarn从系统层面进行统一的管理,各种应用就可以互不干扰的运行在同一个Hadoop系统中,Yarn的地位相当于windows和linux操作系统的地位,这些操作系统的内核管理运行在它上面的各种进程,比如QQ,Chrom浏览器进程。
Yarn如何完成以上功能的?
Yarn,也就是二代MapReduce,主要的思想如下:
The fundamental idea of YARN is to split up the functionalities of resource management and job scheduling/monitoring into separate daemons. The idea is to have a global ResourceManager (RM)and per-application ApplicationMaster (AM). An application is either a single job or a DAG of jobs.
把一代MapReduce的JobTracker同时做的两件事(资源调度和Job监控)分开,资源管理交给ResourceManager去做,Job监控交给基于应用(类比于原来一代MapReduce中的Job)的App Master(AM)去做。
下面看下,ResourceManager和Application Master如何实现上述功能的?
4.1 ResourceManager
ResourceManage里头主要包括两个组件:Scheduler 和 ApplicationManager。
4.1.1 Scheduler
Scheduler是一个纯粹的资源调度器,负责协调集群中各个应用的资源分配,保障整个集群的运行效率。
补充:
Yarn中将资源抽象出了一个模型:Container,是Yarn框架的计算单元,是具体执行应用(如map task、reduce task)的基本单位,一个Container就是一组分配的系统资源,比如CPU,内存,磁盘、网络等资源。Container和集群节点的关系是:一个节点会运行多个Container,但一个Container不会跨节点。
4.1.2 ApplicationManager
另一个组件ApplicationManager主要负责:
接收应用的提交请求,为应用分配第一个Container来运行ApplicationMaster,
负责监控ApplicationMaster,在遇到失败时重启ApplicationMaster运行的Container。
4.2 Application Master
还记得一代MapReduce1.x中,JobTracker负责job的监控。而在MapReduce2中,每个应用的管理、监控交由相应的分布在集群节点NodeManager中的ApplicationMaster,如果某个ApplicationMaster失败,ResourceManager还可以重启它,这大大提高了集群的拓展性。
App master实例是在Container中启动起来的。App Master向ResourceManager进行注册,注册之后客户端就可以查询ResourceManager获得自己ApplicationMaster的详细信息,以后就可以和自己的ApplicationMaster直接交互了。
在应用程序运行期间,提交应用的client主动和Application Master交流获得应用的运行状态、进度更新等信息。
4.3 NodeManager
每个节点都会有自己的NodeManager,NodeManager管理这个节点上的资源分配和监控运行节点的健康状态,这是与一代MapReduce不同的地方,一代中统一由JobTracker集中管理。
NodeManager是一个slave服务:它负责接收ResourceManager的资源请求,然后交给Container,相关的应用运行在这个Container中。同时,它还负责监控并报告Container的使用信息给ResourceManager。
Yarn的架构示意图如下,应用(如map,reduce操作等)运行在Container中,NodeManager定时汇报自己的状态给ResourceManager,App master也汇报自己的状态给ResourceManager中的App manager。
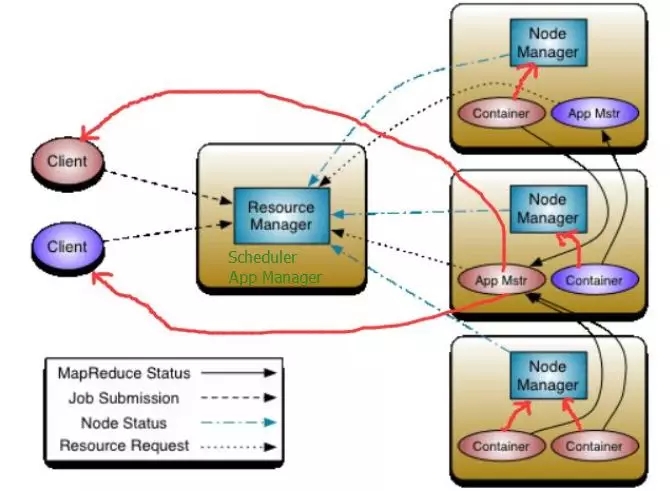
MapReduce2.0的优势
Yarn框架相对一代的MapReduce有如下的优势,这些都在上文中做过阐述,具体如下:
大大减小了 ResourceManager 的资源消耗,因为有很多任务都分布到NodeManager节点上了;
ApplicationMaster 是一个可变更的部分,用户可以定制App master,让更多类型的编程模型能够跑在 Hadoop 集群中;
一代框架中,JobTracker 一个很大的负担就是监控 JobTracker 的运行状况,现在,这个部分就扔给 ApplicationMaster 做了,各个App master的运行情况交给ResourceManager 中的组件ApplicationsManager负责监测 ApplicationMaster 的运行状况。
Container 是 Yarn 为了将来作资源隔离而提出的一个框架。这一点应该借鉴了 Mesos 的工作,目前是一个框架,仅仅提供 java 虚拟机内存的隔离 。

时间:2018-10-09 22:38 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















