构建基于Spark的推荐引擎(Python)
在这里我们的推荐模型选用协同过滤这种类型,使用Spark的MLlib中推荐模型库中基于矩阵分解(matrix factorization)的实现。
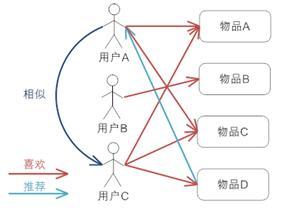
协同过滤(Collaborative Filtering)
协同过滤简单来说是利用某兴趣相投、拥有共同经验之群体的喜好来推荐用户感兴趣的信息,个人通过合作的机制给予信息相当程度的回应(如评分)并记录下来以达到过滤的目的进而帮助别人筛选信息,回应不一定局限于特别感兴趣的,特别不感兴趣信息的纪录也相当重要。
很简单的例子来介绍就是日常我们生活中经常找电影会通过向和自己品味类似的朋友要求推荐,这就是协同过滤的思想
基于用户的协同过滤推荐机制的基本原理
基于用户或物品的方法的得分取决于若干用户或是物品之间依据相似度所构成的集合(即邻居),故它们也常被称为最邻近模型。
矩阵分解
这里我们要处理的数据是用户提供的自身偏好数据,即用户对物品的打分数据。
这些数据可以被转换成用户为行,物品为列的二维矩阵,即评分矩阵A(m*n)表示m个用户对n个物品的打分情况
UIi1i2i3
u13.03.0?
u2?2.04.0
u3?5.0?
这个矩阵A很多元素都是空的,我们称其为缺失值(missing value)
协同过滤提出了一种支持不完整评分矩阵的矩阵分解方法,不用对评分矩阵进行估值填充。
在推荐系统中,我们希望得到用户对所有物品的打分情况,如果用户没有对一个物品打分,那么就需要预测用户是否会对该物品打分,以及会打多少分。这就是所谓的矩阵补全(矩阵分解)
对于这个矩阵分解的方式就是找出两个低维度的矩阵,使得他们的乘积是原始的矩阵。
因此这也是一种降维技术。要找到和‘用户-物品’矩阵近似的k维矩阵,最终要求得出表示用户的m x k维矩阵,和一个表示物品的k x n维矩阵。
这两个矩阵也称作因子矩阵。
对于k的理解为对于每个产品,这里已电影为例,可以从k个角度进行评价,即k个特征值
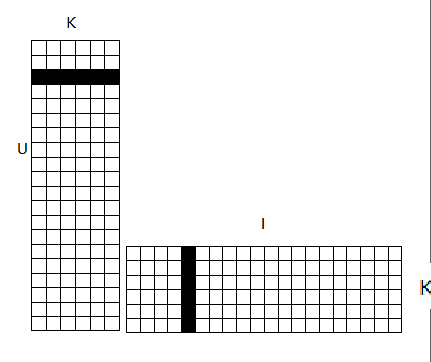
由于是对‘用户-物品’矩阵直接建模,用这些模型进行预测也相对直接,要计算给定用户对某个物品的预计评级,就从用户因子矩阵和物品因子矩阵分别选取对应的行与列,然后计算两者的点积。
假设对于用户A,该用户对一部电影的综合评分和电影的特征值存在一定的线性关系,
即电影的综合评分=(a1d1+a2d2+a3d3+a4d4)
其中a1-4为用户A的特征值,d1-4为之前所说的电影的特征值
最小二乘法实现协同
最小二乘法(Alternating Least Squares, ALS)是一种求解矩阵分解问题的最优化方法。它功能强大、效果理想而且被证明相对容易并行化。这使得它很适合如Spark这样的平台。
使用用户特征矩阵U(m∗k) 中的第i个用户的特征向量ui
和产品特征矩阵V(n∗k)第j个物品的特征向量vi来预测打分矩阵A(m∗n)中的aij,
得出矩阵分解模型的损失函数如下: C=∑(i,j)∈R[(aij−uivTj)2+λ(u2i+v2j)]
通常的优化方法分为两种:交叉最小二乘法(alternative least squares)和随机梯度下降法(stochastic gradient descent)。Spark使用的是交叉最小二乘法(ALS)来最优化损失函数。
算法的思想就是:我们先随机生成然后固定它求解,再固定求解,这样交替进行下去,直到取得最优解min(C)
使用PySpark实现
我们这里的数据集是Movielens 100k数据集,包含了多个用户对多部电影的10万次评级数据
读取评级数据集,该数据包括用户ID,影片ID,星级和时间戳等字段,使用/t分隔
通过sc.textFile()读取数据为RDD,通过分隔符取前3个属性分别为用户ID,影片ID,星级
rawData = sc.textFile('/home/null/hadoop/data/ml-100k/u.data')
rawData.first()
type(rawData)
pyspark.rdd.RDD
rawRatings = rawData.map(lambda line: line.split("\t")[:3])
rawRatings.first()
['196', '242', '3']
# 导入spark中的mllib的推荐库
import pyspark.mllib.recommendation as rd
生成Rating类的RDD数据
# 由于ALS模型需要由Rating记录构成的RDD作为参数,因此这里用rd.Rating方法封装数据
ratings = rawRatings.map(lambda line: rd.Rating(int(line[0]), int(line[1]), float(line[2])))
ratings.first()
Rating(user=196, product=242, rating=3.0)
训练ALS模型
rank: 对应ALS模型中的因子个数,即矩阵分解出的两个矩阵的新的行/列数,即A≈UVT,k<
iterations: 对应运行时的最大迭代次数
lambda: 控制模型的正则化过程,从而控制模型的过拟合情况。
# 训练ALS模型
model = rd.ALS.train(ratings, 50, 10, 0.01)
model
# 对用户789预测其对电影123的评级
predictedRating = model.predict(789,123)
predictedRating
3.1740832151065774
# 获取对用户789的前10推荐
topKRecs = model.recommendProducts(789,10)
topKRecs
[Rating(user=789, product=429, rating=6.302989890089658),
Rating(user=789, product=496, rating=5.782039583864358),
Rating(user=789, product=651, rating=5.665266358968961),
Rating(user=789, product=250, rating=5.551256887914674),
Rating(user=789, product=64, rating=5.5336980239740186),
Rating(user=789, product=603, rating=5.468600343790217),
Rating(user=789, product=317, rating=5.442052952711695),
Rating(user=789, product=480, rating=5.414042111530209),
Rating(user=789, product=180, rating=5.413309515550101),
Rating(user=789, product=443, rating=5.400024900653429)]
检查推荐内容
这里首先将电影的数据读入,讲数据处理为电影ID到标题的映射
然后获取某个用户评级前10的影片同推荐这个用户的前10影片进行比较
#检查推荐内容
movies = sc.textFile('/home/null/hadoop/data/ml-100k/u.item')
movies.first()
'1|Toy Story (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Toy%20Story%20(1995)|0|0|0|1|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0'
titles_data= movies.map(lambda line: line.split("|")[:2]).collect()
titles = dict(titles_data)
titles
moviesForUser = ratings.keyBy(lambda rating: rating.user).lookup(789)
type(moviesForUser)
list
moviesForUser = sorted(moviesForUser,key=lambda r: r.rating, reverse=True)[0:10]
moviesForUser
[Rating(user=789, product=127, rating=5.0),
Rating(user=789, product=475, rating=5.0),
Rating(user=789, product=9, rating=5.0),
Rating(user=789, product=50, rating=5.0),
Rating(user=789, product=150, rating=5.0),
Rating(user=789, product=276, rating=5.0),
Rating(user=789, product=129, rating=5.0),
Rating(user=789, product=100, rating=5.0),
Rating(user=789, product=741, rating=5.0),
Rating(user=789, product=1012, rating=4.0)]
[(titles[str(r.product)], r.rating) for r in moviesForUser]
[('Godfather, The (1972)', 5.0),
('Trainspotting (1996)', 5.0),
('Dead Man Walking (1995)', 5.0),
('Star Wars (1977)', 5.0),
('Swingers (1996)', 5.0),
('Leaving Las Vegas (1995)', 5.0),
('Bound (1996)', 5.0),
('Fargo (1996)', 5.0),
('Last Supper, The (1995)', 5.0),
('Private Parts (1997)', 4.0)]
[(titles[str(r.product)], r.rating) for r in topKRecs]
[('Day the Earth Stood Still, The (1951)', 6.302989890089658),
("It's a Wonderful Life (1946)", 5.782039583864358),
('Glory (1989)', 5.665266358968961),
('Fifth Element, The (1997)', 5.551256887914674),
('Shawshank Redemption, The (1994)', 5.5336980239740186),
('Rear Window (1954)', 5.468600343790217),
('In the Name of the Father (1993)', 5.442052952711695),
('North by Northwest (1959)', 5.414042111530209),
('Apocalypse Now (1979)', 5.413309515550101),
('Birds, The (1963)', 5.400024900653429)]
推荐模型效果的评估
均方差(Mean Squared Error,MSE)
定义为各平方误差的和与总数目的商,其中平方误差是指预测到的评级与真实评级的差值平方
直接度量模型的预测目标变量的好坏
均方根误差(Root Mean Squared Error,RMSE)
对MSE取其平方根,即预计评级和实际评级的差值的标准差
# evaluation metric
usersProducts = ratings.map(lambda r:(r.user, r.product))
predictions = model.predictAll(usersProducts).map(lambda r: ((r.user, r.product),r.rating))
predictions.first()
((316, 1084), 4.006135662882842)
ratingsAndPredictions = ratings.map(lambda r: ((r.user,r.product), r.rating)).join(predictions)
ratingsAndPredictions.first()
((186, 302), (3.0, 2.7544572973050236))
# 使用MLlib内置的评估函数计算MSE,RMSE
from pyspark.mllib.evaluation import RegressionMetrics
predictionsAndTrue = ratingsAndPredictions.map(lambda line: (line[1][0],line[1][3]))
predictionsAndTrue.first()
(3.0, 2.7544572973050236)
# MSE
regressionMetrics = RegressionMetrics(predictionsAndTrue)
regressionMetrics.meanSquaredError
0.08509832708963357
# RMSE
regressionMetrics.rootMeanSquaredError
0.2917161755707653

时间:2018-10-09 22:38 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]底层I/O性能大PK:Python/Java被碾压,Rust有望取代
- [数据挖掘]RedMonk语言排行:Python力压Java,Ruby持续下滑
- [数据挖掘]不得了!Python 又爆出重大 Bug~
- [数据挖掘]Spark 迁移到 K8S 在有赞的实践与经验
- [数据挖掘]TIOBE 1 月榜单:Python年度语言四连冠,C 语言再次
- [数据挖掘]TIOBE12月榜单:Java重回第二,Python有望四连冠年度
- [数据挖掘]这个可能打败Python的编程语言,正在征服科学界
- [数据挖掘]Spark Operator 初体验
- [数据挖掘]如何实现Spark on Kubernetes?
- [数据挖掘]2021年编程语言趋势预测:Python和JavaScript仍火热,
相关推荐:
网友评论:















