大数据学习(1)Hadoop安装
hadoop的安装其实就是HDFS和YARN集群的配置,从下面的架构图可以看出,HDFS的每一个DataNode都需要配置NameNode的位置。同理YARN中的每一个NodeManager都需要配置ResourceManager的位置。
NameNode和ResourceManager的作用如此重要,在集群环境下,他们存在单点问题吗?在hadoop1.0中确实存在,不过在2.0中已经得到解决,具体参考:
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithNFS.html
https://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-name-node/index.html
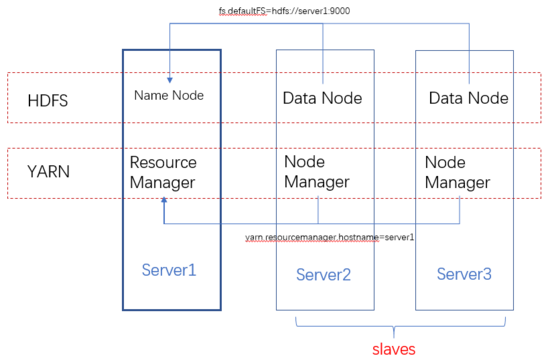
配置
因为每台机器上的配置都是一样的,所以配置时一般是配置好一台服务器,然后复制到其他服务器上。
JAVA_HOME
在hadoop-env.sh文件中配置JAVA_HOME.
core-site.xml
配置hdfs文件系统,通过fs.defaultFS配置hdfs的NameNode节点。
通过hadoop.tmp.dir配置hadoop运行时产生文件的存储目录
hdfs-site.xml
配置文件副本数量和 second namenode :
yarn-site.xml
配置YARN的ResourceManager:
和reducer获取数据的方式:
最后记得把hadoop的bin和sbin目录添加到环境变量中:
export HADOOP_HOME=/user/local/hadoop-2.6.5
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
格式化namenode
hdfs namenode -format (hadoop namenode -format)
启动Hadoop
先启动HDFS的NameNode:
hadoop-daemon.sh start datanode
在集群的DataNode上启动DataNode:
hadoop-daemon.sh start datanode
查看启动结果
[root@server1 ~]# jps
2111 Jps
2077 NameNode
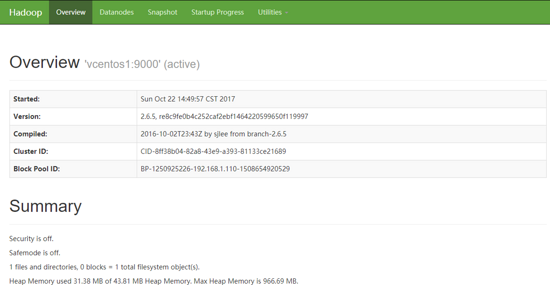
如果启动成功,通过http://server1:50070,可以看到类似下面的页面:
再启动YARN
[root@vcentos1 sbin]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop-2.6.5/logs/yarn-root-resourcemanager-vcentos1.out
vcentos3: starting nodemanager, logging to /usr/local/hadoop-2.6.5/logs/yarn-root-nodemanager-vcentos3.out
vcentos2: starting nodemanager, logging to /usr/local/hadoop-2.6.5/logs/yarn-root-nodemanager-vcentos2.out
[root@server1 sbin]# jps
2450 ResourceManager
2516 Jps
2077 NameNode
hadoop下的sbin目录下的文件是用来管理hadoop服务的:
hadoop-dameon.sh:用来单独启动namenode或datanode;
start/stop-dfs.sh:配合/etc/hadoop/slaves,可以批量启动/关闭NameNode和集群中的其他DataNode;
start/stop-yarn.sh:配合/etc/hadoop/slaves,可以批量启动/关闭ResourceManager和集群中的其他NodeManager;
bin目录下的文件可以提供hdfs、yarn和mapreduce服务:
[root@server1 bin]# hadoop fs
Usage: hadoop fs [generic options]
[-appendToFile
[-cat [-ignoreCrc]
[-checksum
[-chgrp [-R] GROUP PATH...]
[-chmod [-R]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l]
[-copyToLocal [-p] [-ignoreCrc] [-crc]
[-count [-q] [-h]
[-cp [-f] [-p | -p[topax]]
[-createSnapshot
[-deleteSnapshot
[-df [-h] [
[-du [-s] [-h]
[-expunge]
[-get [-p] [-ignoreCrc] [-crc]
[-getfacl [-R]
[-getfattr [-R] {-n name | -d} [-e en]
[-getmerge [-nl]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [
[-mkdir [-p]
[-moveFromLocal
[-moveToLocal
[-mv
[-put [-f] [-p] [-l]
[-renameSnapshot
[-rm [-f] [-r|-R] [-skipTrash]
[-rmdir [--ignore-fail-on-non-empty]
[-setfacl [-R] [{-b|-k} {-m|-x }
[-setfattr {-n name [-v value] | -x name}
[-setrep [-R] [-w]
[-stat [format]
[-tail [-f]
[-test -[defsz]
[-text [-ignoreCrc]
[-touchz
[-usage [cmd ...]]

时间:2018-10-09 22:38 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















