Hadoop3 YARN集群中的磁盘I / O调度设计详解1
问题导读
1.磁盘IO实现共享,使用的是什么原理技术?
2.如何描述磁盘I / O资源?
3.磁盘I / O资源中的调度因素如何?
4.每个NodeManager如何执行每个本地任务的磁盘I / O资源使用?
1.背景
已经研究了Hadoop YARN中的资源共享和隔离技术实现了CPU和内存等资源。 任务(或容器)可以限制CPU核心的数量和允许使用的内存。 但是,YARN不支持I / O资源管理和隔离。 具有各种I / O需求的共同任务可能会相互竞争。 本文档重点介绍磁盘I / O资源调度,并提供I / O资源调度和隔离的解决方案。
建立可行的磁盘I / O资源调度机制是需要的。 不同任务有不同的磁盘I / O请求。 在两个无法完全满足两个请求的节点上一起调度两个磁盘I / O密集型任务将导致它们争夺I / O并相互减速。 另外,在不隔离磁盘I / O资源的情况下,YARN很难为I / O密集型任务提供稳定的性能。 例如,在I / O轻节点中调度I / O密集型任务可能比在I / O 重节点中运行得更快。
为了提供所需的磁盘I / O资源隔离,本文档介绍了磁盘I / O管理的公平共享机制。 每个任务都可以指定自己的磁盘I / O需求,调度程序可以保证分配给每个任务的I / O资源的数量。 这样可以缓解I / O资源竞争,确保一些优先级较高的任务(具有较高的I / O资源请求)不会被较低优先级的任务(具有较低的I / O资源请求)阻塞。
2.设计
本节主要讨论磁盘I / O调度的设计,包括:
(1)如何描述磁盘I / O资源?
(2)磁盘I / O资源中的调度因素如何?
(3)每个NodeManager如何执行每个本地任务的磁盘I / O资源使用?
2.1磁盘I / O资源描述
对于磁盘I / O资源描述,这里我们介绍一个额外的资源维度虚拟磁盘【vdisks】(virtual disks)现有的资源类型(CPU和内存)。 每个任务都可以根据自己的I / O请求,通过vdisks指定自己的磁盘I / O资源请求。 较大的vdisk意味着容器需要更多的磁盘I / O带宽。 默认的虚vdisks值设置为1,这意味着轻I / O。 请注意,vdisks不会暴露节点上的磁盘之间的异构性,这超出了本工作的范围。
2.2 调度
scheduler端的主要变化是将vdisks包括到DRF(Dominant Resource Fairness)策略中。 目前,调度器中的DRF支持cpu和内存。 我们还介绍了用户配置,以指定哪些资源应包含在DRF中。
2.3执行NodeManager
总之,我们想提供成比例的磁盘I / O公平共享。 可用磁盘I / O资源按比例方式在所有任务之间共享(vdisk值)。 我们使用Cgroups来实现这个解决方案。 在这里,我们首先说明Cgroup提供的函数,然后讨论实现细节。
Cgroups提供了一个名为blkio的子系统,它提供了两个策略来控制对磁盘I / O的访问:
●比例权重分配:实现在完全Fair队列I / O调度,此策略允许为特定的cgroup设置权重。 这意味着每个cgroup都有一个保留所有I / O操作的设置百分比(取决于cgroup的权重)。
●I / O限制(上限):该策略用于设置特定设备执行的I / O操作数量的上限。 这意味着一个设备可以有一个有限的读取或写入操作。
我们使用比例权重分配策略,在所有的容器中提供加权公平分享。如果容器指定其磁盘I/O请求为p,则可以直接设置该容器的权重为p。
3.实现
3.1第一阶段
这里我们总结一下代码库的主要变化。
3.1.1磁盘I / O资源描述
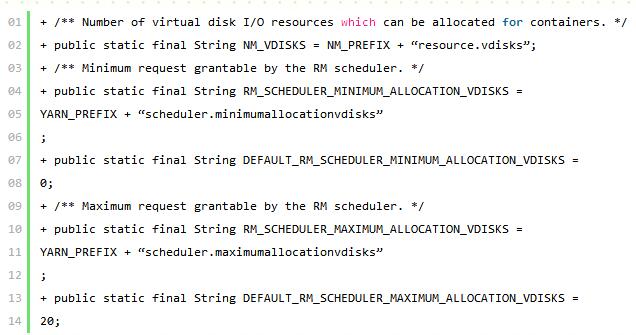
简介:将磁盘I / O维度(vdisks)添加到资源请求。
在yarn_protos.proto中添加字段vdisks到ResourceProto

添加字段到 org.apache.hadoop.yarn.api.records.Resource.

添加下面配置到org.apache.hadoop.yarn.conf.YarnConfiguration.
3.1.2调度变化
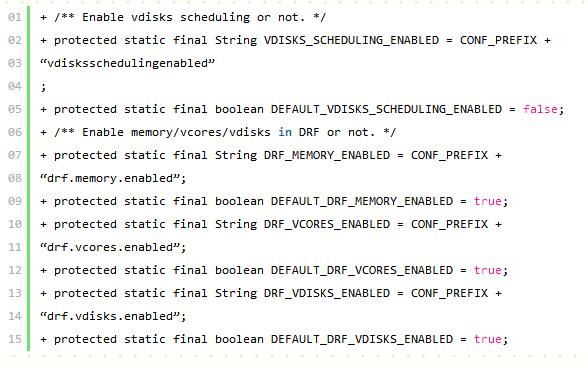
简介:调度方的主要变化包括(对于FairScheduler和CapacityScheduler):
● 配置调度程序是否执行磁盘I / O调度。 如果禁用,调度程序只能在内存和vcore上运行。
● 将vdisks添加到DRF策略,DRF计算时配置包含哪些资源。
3.1.3 NodeManager执行
简介:添加对NodeManager的支持,以执行每个任务的磁盘I / O资源使用情况。
3.1.3.1 准备
对org.apache.hadoop.yarn.server.nodemanager.util.CgroupsLCEResourcesHandler进行更改,挂载Cgroups路径包括blkio.
3.1.3.2 实例化新的Container
一般来说,每一个新的实例化Container c,在子系统blkio下创建一个新的cgroup。所有磁盘设备的cgroup权重设置为p。

添加C的进程到cgroup的任务文件中。

一旦容器完成,删除创建的cgroup。
3.1第二阶段
缓冲写入隔离:目前,Cgroups的blkio子系统只能支持同步I / O队列,并且不能强制执行缓冲写入通信(缓冲读取正常),因为1所有缓冲写入都是系统范围的,而不是每个组/进程。 解决这个问题的正确方法是在内核中支持buffered-writes。 虽然我们只支持在阶段1中读取I / O流量执行,但对于具有大量重读BI工作负载的情况,仍然是可取的。
为了解决缓冲写入问题,一种方法是添加覆盖在本地文件系统之上的FUSE2包装器【wrapper】。 由于包装器【wrapper】可以看到所有I / O流量,因此可以轻松执行监视和速率限制来执行共享策略。

时间:2018-10-09 22:35 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















