如何在Python中从零开始实现随机森林
根据您的测试数据样本构建多个模型(称为套袋)可以减少这种差异,但是树本身是高度相关的。
随机森林是套袋(方法)的延伸,除了基于多个测试数据样本构建树木之外,它还限制了可用于构建树木的特征,使得树木间具有差异。这反过来可以提升算法的表现。
在本教程中,您将了解如何在Python中从头开始实现随机森林算法。
完成本教程后,您将知道:
套袋决策树和随机森林算法的区别。
如何构造更多方差的袋装决策树。
如何将随机森林算法应用于预测建模问题。
让我们开始吧。
2017年1月更新:将cross_validation_split()中fold_size的计算更改为始终为整数。修复了Python 3的问题。
2017年2月更新:修复了build_tree中的错误。
2017年8月更新:修正了基尼计算中的一个错误,增加了群组大小(基于迈克尔!)。
如何在Python中从头开始实现随机森林
描述
本节简要介绍本教程中使用的随机森林算法和Sonar数据集。
随机森林算法
决策树涉及从数据集中(利用)贪婪选择选取最佳分割点过程中的每一步。
如果不精简(该算法),此算法容易使决策树出现高方差。这种高方差(结果)可以通过创建包含测试数据集中(多个)不同的实例(问题的不同观点)的多重树,接着将实例所有的可能结果结合,这种方法简称为bootstrap聚合或套袋。
套袋的局限性在于,它使用相同的贪婪算法来创建每棵树,这意味着在每棵树中可能会选择相同或非常相似的分割点,使得不同的树非常相似(树将被关联)。这反过来又使他们的预测相似,从而缩减了最初寻求的差异。
我们可以通过贪婪算法在创建树时在每个分割点评估的特征(行)来限制决策树不同。这被称为随机森林算法。
像装袋一样,测试数据集的多个样本在被采集后,接着在每个样本上训练不同的树。不同之处在于在每一点上,拆分是在数据中进行并添加到树中的,且只考虑固定的属性子集。
对于分类问题,我们将在本教程中讨论的问题的类型——分割中输入特点数的平方根值对为分割操作考虑的属性个数的限制。
num_features_for_split = sqrt(total_input_features)
这一小变化的结果是树之间变得更加不同(不关联),作为结果会有更加多样化的预测,这样的结果往往好于一个单独的树或者单独套袋得到的结果。
声纳数据集
我们将在本教程中使用的数据集是Sonar数据集。
这是一个描述声纳声音从不同曲面反弹后返回(数据)的数据集。输入的60个变量是声呐从不同角度返回的力度值。这是一个二元分类问题,需要一个模型来区分金属圆柱中的岩石。这里有208个观察对象。
这是一个很好理解的数据集。所有变量都是连续的且范围一般是0到1。输出变量是“Mine”字符串中的“M”和“rock”中的“R”,需要转换为整数1和0。
通过预测在数据集(“M”或“mines”)中观测数最多的类,零规则算法可以达到53%的准确度。
您可以在UCI Machine Learning repository了解关于此数据集的更多信息。
下载免费的数据集,并将其放置在工作目录中,文件名为sonar.all-data.csv。
教程
本教程分为2个步骤。
计算分割。
声纳数据集案例研究。
这些步骤为您需要将随机森林算法应用于自己的预测建模问题奠定了基础。
1.计算分割
在决策树中,通过利用最低成本找到指定属性和该属性的值方法来确定分割点。
对于分类问题,这个成本函数通常是基尼指数,它计算分割点创建的数据组的纯度。基尼指数为0是完美纯度,其中在两类分类问题的情况下,将类别值完全分成两组。
在决策树中找到最佳分割点涉及到为每个输入的变量评估训练数据集中每个值的成本。
对于装袋和随机森林,这个程序是在测试数据集的样本上执行的,并且是可替换的。更换取样意味着同一行(数据)会不止一次的被选择并将其添加到取样中。
我们可以优化随机森林的这个程序。我们可以创建一个输入属性样本来考虑,而不是在搜索中枚举输入属性的所有值。
这个输入属性的样本可以随机选择而不需要替换,这意味着每个输入属性在查找具有最低成本的分割点的过程中只被考虑一次。
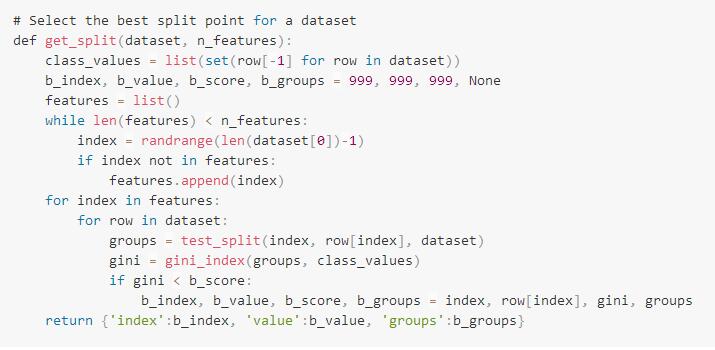
下面是实现此过程的函数名称get_split()。它将数据集和固定数量的输入要素作为输入参数进行评估,此数据集可能是实际测试数据集的一个样本。
helper函数test_split()用于通过候选分割点拆分数据集,gini_index()用于根据创建的行组来计算给定拆分的花费。
我们可以看到,通过随机选择特征索引并将其添加到列表(称为特征)来创建特征列表,然后枚举该特征列表并且将测试数据集中的特定值评估作为分割点。
现在我们知道如何修改决策树算法以便与随机森林算法一起使用,我们可以将它与一个bagging实现一起使用,并将其应用于现实生活中的数据集。
2.声纳数据集案例研究
在本节中,我们将把随机森林算法应用到声纳数据集。
该示例假定数据集的CSV副本位于当前工作目录中,文件名为sonar.all-data.csv。
首先加载数据集,将字符串值转换为数字,并将输出列从字符串转换为0和1的整数值。这可以通过使用帮助器函数load_csv(),str_column_to_float()和str_column_to_int()来加载和预备数据集。
我们将使用k-fold交叉验证来估计未知数据的学习模型的性能。这意味着我们将构建和评估k个模型,并将性能估计为平均模型误差。分类准确性将用于评估每个模型。这些工具或是算法在cross_validation_split(),accuracy_metric()和evaluate_algorithm()辅助函数中提供。
我们也将使用适合套袋包括辅助功能分类和回归树(CART)算法的实现)test_split(拆分数据集分成组,gini_index()来评估分割点,我们修改get_split()函数中讨论在前一步中,to_terminal(),split()和build_tree()用于创建单个决策树,预测()使用决策树进行预测,subsample()创建训练数据集的子采样,以及bagging_predict()用决策树列表进行预测。
开发了一个新的函数名称random_forest(),首先根据训练数据集的子样本创建一个决策树列表,然后使用它们进行预测。
正如我们上面所说的,随机森林和袋装决策树之间的关键区别是对树的创建方式中的一个小的改变,这里是在get_split()函数中。
完整的例子如下所示。

构建深度树的最大深度为10,每个节点的最小训练行数为1。训练数据集样本的创建大小与原始数据集相同,这是随机森林算法的默认期望值。
在每个分割点处考虑的特征的数量被设置为sqrt(num_features)或者sqrt(60)= 7.74被保留为7个特征。
对一套有着3种不同数量的树木(示例)进行评测在此过程中进行比较,结果表明随着更多树木的添加,(处理)技能也随之提升。
运行该示例将打印每个折叠的分数和每个配置的平均分数。

扩展
本节列出了您可能有兴趣探索的关于本教程的扩展。
算法优化。发现教程中使用的配置有一些试验和错误,但没有进行优化。尝试更多的树木,不同数量的特征,甚至不同的树形配置来提高性能。
更多的问题。将该技术应用于其他分类问题,甚至将其应用于回归,具有新的成本函数和结合树预测的新方法。
你有没有尝试这些扩展?
在下面的评论中分享你的经验。
评论
在本教程中,您了解了如何从头开始实现随机森林算法。
具体来说,你了解到:
随机森林和Bagged决策树的区别。
如何更新决策树的创建以适应随机森林过程。
如何将随机森林算法应用于现实世界的预测建模问题。

时间:2018-10-09 22:31 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]底层I/O性能大PK:Python/Java被碾压,Rust有望取代
- [数据挖掘]大数据分析的技术有哪些?
- [数据挖掘]大数据分析会遇到哪些难题?
- [数据挖掘]RedMonk语言排行:Python力压Java,Ruby持续下滑
- [数据挖掘]不得了!Python 又爆出重大 Bug~
- [数据挖掘]TIOBE 1 月榜单:Python年度语言四连冠,C 语言再次
- [数据挖掘]TIOBE12月榜单:Java重回第二,Python有望四连冠年度
- [数据挖掘]这个可能打败Python的编程语言,正在征服科学界
- [数据挖掘]2021年编程语言趋势预测:Python和JavaScript仍火热,
- [数据挖掘]Spark 3.0重磅发布!开发近两年,流、Python、SQL重
相关推荐:
网友评论:















