Sqoop数据导入到HBase遇上的问题及解决方法
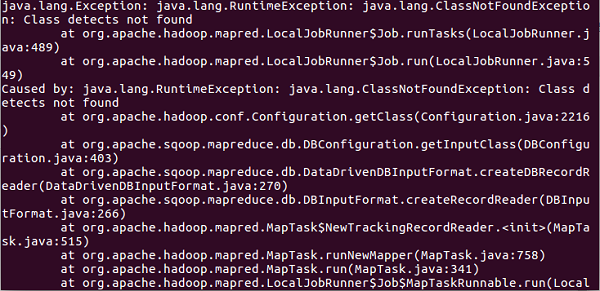
解决方法: 将/tmp/sqoop-hadoop/compile 文件夹下的 detects.jar包 放到sqoop安装目录lib下。重新执行即可。确实重新运行好了.
2.使用importtsv将文件数据导入到Hbase中,x运行${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/lib/hbase-server-1.2.6.jar,提示:
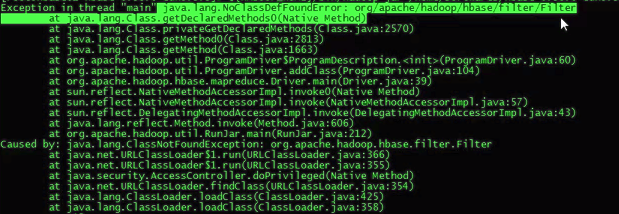
解决方法: 错误提示说明hadoop中找不到hbase的jar包,只要将hbase的路径添加到hadoop路径就可以了HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` ${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/lib/hbase-server-1.2.6.jar;
最后可以使用命令将文件数据导入到hbase中,例子:HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` ${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/lib/hbase-server-1.2.6.jar importtsv -Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:age -Dimporttsv.separator=, user /hbase_user -Dimporttsv.bulk.output=/hbase_user 将use数据导入到hbase的user中,提示Bad lines =0 就说明全部导入成功啦
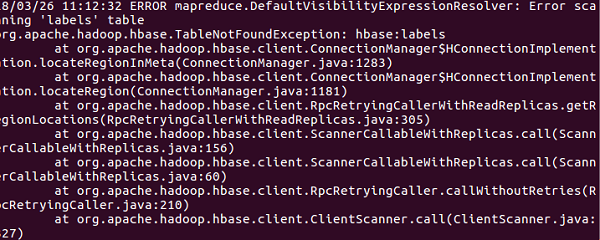
ps: 下图这个错误提示可以不用管他,不影响运行

时间:2018-10-09 22:31 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]HBase数据迁移到Kafka?这种逆向操作你懵逼了吗?
- [数据挖掘]Apache2019年度报告出炉,HBase、Flink、Beam成最活跃
- [数据挖掘]PinalyticsDB:基于HBase的时间序列数据库
- [数据挖掘]PinalyticsDB:基于HBase的时间序列数据库
- [数据挖掘]HBase 2.0 在时序数据存储方向的应用
- [数据挖掘]图解HBase--大数据平台技术栈
- [数据挖掘]快手HBase在千亿级用户特征数据分析中的应用与实
- [数据挖掘]百度智能监控场景下的 HBase 实践
- [数据挖掘]基于HBase的大数据存储在京东的应用
- [数据挖掘]实战解析:基于HBase的大数据存储在京东的应用场
相关推荐:
网友评论:















