Spark核心技术原理透视--Spark运行模式
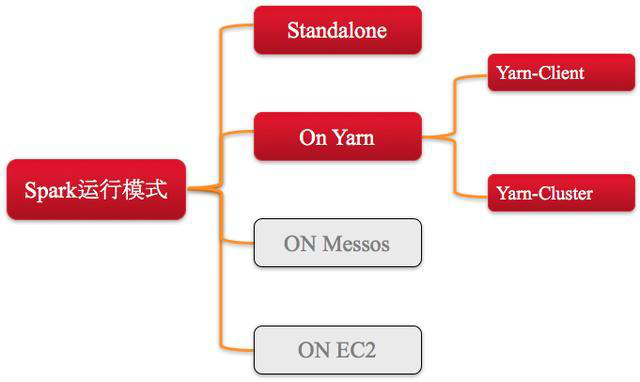
1、Spark运行模式主要分为以下几种,如图所示。
2、Spark on Standalone 模式Standalone模式如下图所示。
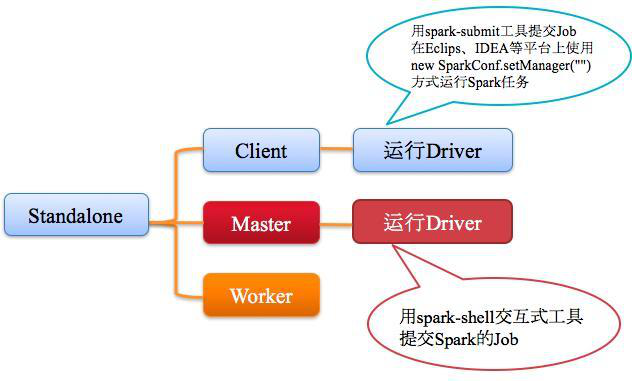
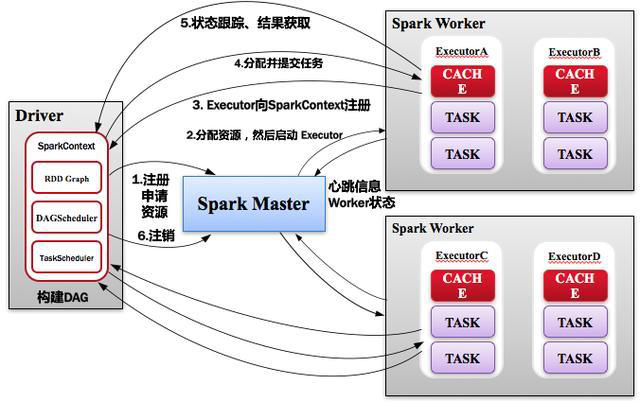
3、Standalone运行过程
1)SparkContext连接到Master,向Master注册并申请资源(CPU Core and Memory);
2) uMaster根据SparkContext的资源申请要求和Worker心跳周期内报告的信息决定在哪个Worker上分配资源,然后在该Worker上获取资源,然后启动Executor; Executor向SparkContext注册;
3)SparkContext将Applicaiton代码发送给Executor;同时SparkContext解析Applicaiton代码,构建DAG图,并提交给DAGScheduler分解成Stage,然后以Stage(或者称为TaskSet)提交给TaskScheduler,TaskScheduler负责将Task分配到相应的Worker,最后提交给Executor执行;
4)Executor会建立Executor线程池,开始执行Task,并向SparkContext报告,直至Task完成;
5)所有Task完成后,SparkContext向Master注销,释放资源。如图所示。
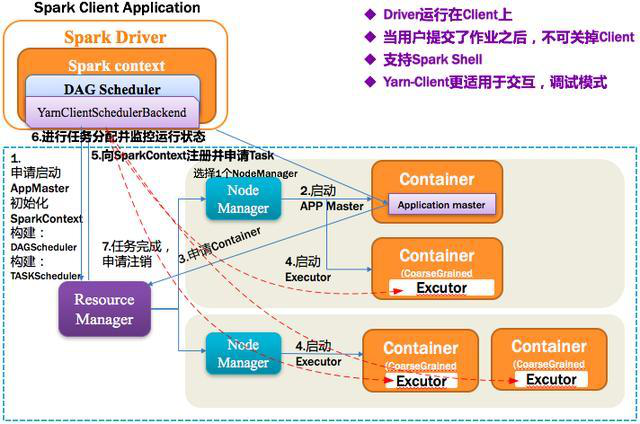
4、Spark on Yarn-Client 模式
1)Yarn-Client 第一步:Spark Yarn Client向Yarn的ResourceManager申请启动Application Master。同时在SparkContent初始化中将创建DAGScheduler和TASKScheduler;
2)Yarn-Client 第二步:ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的Application Master;
3)Yarn-Client 第三步:Client中的SparkContext初始化完毕后,与ApplicationMaster建立通讯,向ResourceManager注册,根据任务信息向ResourceManager申请资源;
4)Yarn-Client 第四步:一旦ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它在获得的Container中启动Executor,启动后会向Client中的SparkContext注册并申请Task;
5)Yarn-Client 第五步:Client中的SparkContext分配Task给Executor执行,Executor运行Task并向Driver汇报运行的状态和进度,以让Client随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
6)Yarn-Client 第六步:应用程序运行完成后,Client的SparkContext向ResourceManager申请注销并关闭自己。如图所示。
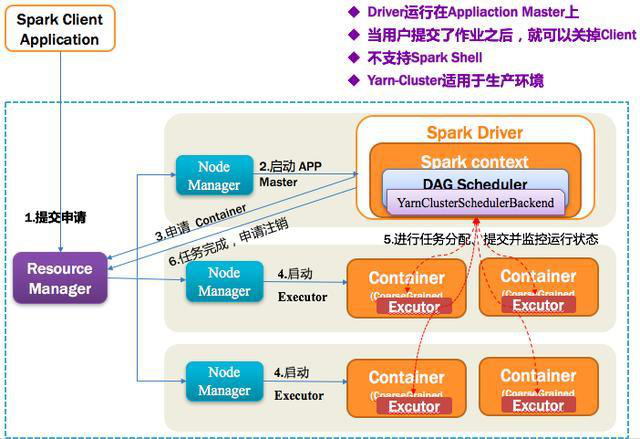
5、Spark on Yarn-Cluster模式
1)Yarn-Cluster 第一步:Spark Yarn Client向Yarn中提交应用程序,包括ApplicationMaster程序、启动ApplicationMaster的命令、需要在Executor中运行的程序等;
2)Yarn-Cluster 第二步:ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,其中ApplicationMaster进行SparkContext等的初始化;
3)Yarn-Cluster 第三步:ApplicationMaster向ResourceManager注册,这样用户可以直接通过ResourceManage查看应用程序的运行状态,然后它将采用轮询的方式通过RPC协议为各个任务申请资源,并监控它们的运行状态直到运行结束;
4)Yarn-Cluster 第四步:一旦ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它在获得的Container中启动启动Executor,启动后会向ApplicationMaster中的SparkContext注册并申请Task;
5)Yarn-Cluster 第五步:ApplicationMaster中的SparkContext分配Task给Executor执行,Executor运行Task并向ApplicationMaster汇报运行的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
6)Yarn-Cluster 第六步:应用程序运行完成后,ApplicationMaster向ResourceManager申请注销并关闭自己。如下图所示。
6、几种模式对比(Yarn-Cluster VS Yarn-Client VS Standalone)
官网描述如下图所示,有兴趣的童鞋可以去Apache官网查询。


时间:2018-10-09 22:31 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]大数据分析的技术有哪些?
- [数据挖掘]大数据分析会遇到哪些难题?
- [数据挖掘]Spark 迁移到 K8S 在有赞的实践与经验
- [数据挖掘]Spark Operator 初体验
- [数据挖掘]如何实现Spark on Kubernetes?
- [数据挖掘]Spark SQL 物化视图技术原理与实践
- [数据挖掘]Spark on K8S 的最佳实践和需要注意的坑
- [数据挖掘]Spark 3.0重磅发布!开发近两年,流、Python、SQL重
- [数据挖掘]Spark 3.0开发近两年终于发布,流、Python、SQL重大
- [数据挖掘]Apache Spark 3.0.0 正式版终于发布了,重要特性全面
相关推荐:
网友评论:















