java操作HBase进行数据的添加和查询
最近项目中使用了hadoop,这里记录一下使用java操作HBase的一些代码供读者参考.
好了,进入今天的正题:
使用这边博文的代码必须建立在,你的hadoop环境已经建好,hbase也已经建好,如何搭建这里就不在说明了,可以自行搜索一下
首先是初始化连接hbase的HbaseTemplate :我使用的是springboot
引入需要的jar包,需要哪些jar包需要自己搜索一下,项目中的不方便粘贴过来,不过要提醒一下的是下面这个jar包的引入,需要排除log4j这个类,因为会和apache中冲突
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>0.96.1.1-hadoop2</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
初始化HbaseTemplate
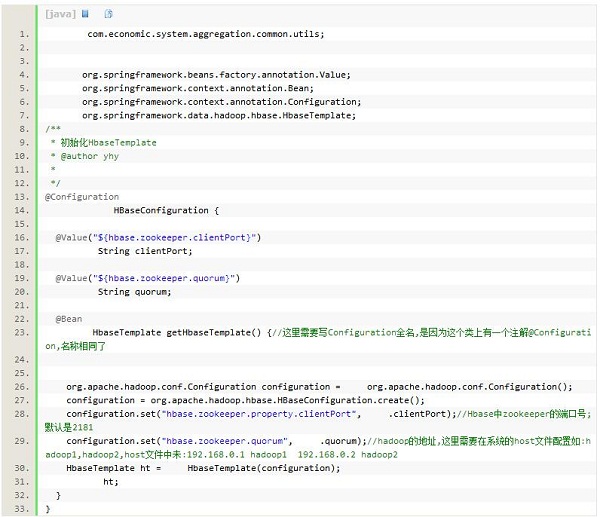
这样,就把HbaseTemplate初始化好了,就可以开始使用了
这里使用了一个service接口和一个实现类

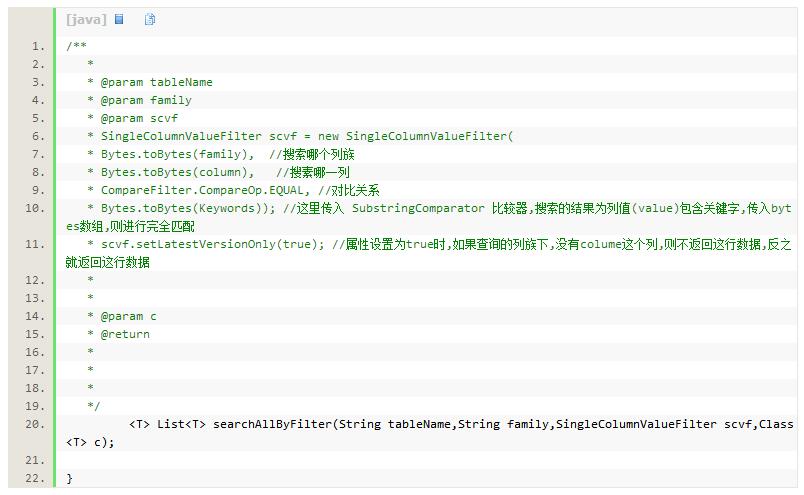
实现类:

最后是调用了,方法就自己写吧,就调用service中的方法就行了.
这里有一个地方需要说明下,上面的代码是建立在pojo类的所有属性(字段)都是String类型,如果有其他类型,有些方法就不怎么好用了,但可以使用getOne()中的方法修改其他方法,JSON.parseObject(obj.toJSONString(), c)这个方法可以将一定格式的字符串转为相应的格式.如
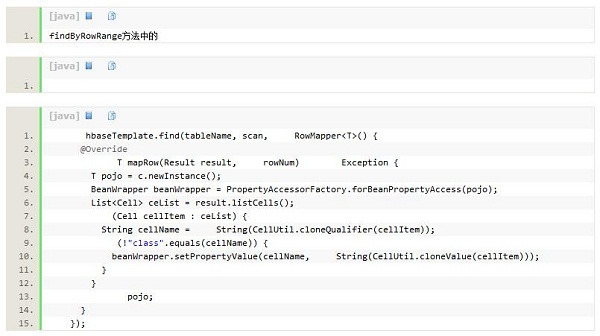
改为


时间:2018-10-09 22:31 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]HBase数据迁移到Kafka?这种逆向操作你懵逼了吗?
- [数据挖掘]Apache2019年度报告出炉,HBase、Flink、Beam成最活跃
- [数据挖掘]PinalyticsDB:基于HBase的时间序列数据库
- [数据挖掘]PinalyticsDB:基于HBase的时间序列数据库
- [数据挖掘]HBase 2.0 在时序数据存储方向的应用
- [数据挖掘]图解HBase--大数据平台技术栈
- [数据挖掘]快手HBase在千亿级用户特征数据分析中的应用与实
- [数据挖掘]百度智能监控场景下的 HBase 实践
- [数据挖掘]基于HBase的大数据存储在京东的应用
- [数据挖掘]实战解析:基于HBase的大数据存储在京东的应用场
相关推荐:
网友评论:















