一条数据的HBase之旅,简明HBase入门教程
一些常见的HBase新手问题:
什么样的数据适合用HBase来存储?
既然HBase也是一个数据库,能否用它将现有系统中昂贵的Oracle替换掉?
存放于HBase中的数据记录,为何不直接存放于HDFS之上?
能否直接使用HBase来存储文件数据?
Region(HBase中的数据分片)迁移后,数据是否也会被迁移?
为何基于Spark/Hive分析HBase数据时性能较差?
开篇
用惯了Oracle/MySQL的同学们,心目中的数据表,应该是长成这样的:

这种表结构规整,每一行都有固定的列构成,因此,非常适合结构化数据的存储。但在NoSQL领域,数据表的模样却往往换成了另外一种"画风":

行由看似"杂乱无章"的列组成,行与行之间也无须遵循一致的定义,而这种定义恰好符合半结构化数据或非结构化数据的特点。本文所要讲述的HBase,就属于该派系的一个典型代表。这些"杂乱无章"的列所构成的多行数据,被称之为一个"稀疏矩阵",而上图中的每一个"黑块块",在HBase中称之为一个KeyValue。
Apache HBase官方给出了这样的定义:
Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
即:Apache HBase是基于Hadoop构建的一个分布式的、可伸缩的海量数据存储系统。
HBase常被用来存放一些海量的(通常在TB级别以上)结构比较简单的数据,如历史订单记录,日志数据,监控Metris数据等等,HBase提供了简单的基于Key值的快速查询能力。
HBase在国内市场已经取得了非常广泛的应用,在搜索引擎中,也可以看出来,HBase在国内呈现出了逐年上升的势态:

从Apache HBase所关联的github项目的commits统计信息来看,也可以看出来该项目非常活跃:
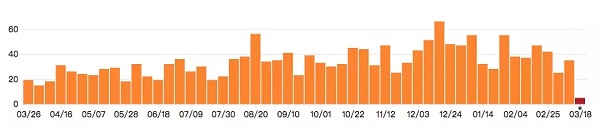
(需要说明的一点:HBase中的每一次commit,都已经过社区Commiter成员严格的Review,在commit之前,一个Patch可能已经被修改了几十个版本)
令人欣喜的是,国内的开发者也积极参与到了HBase社区贡献中,而且被社区接纳了多名PMC以及Committer成员。
本文将以一条数据在HBase中的“旅程”为线索,介绍HBase的核心概念与流程,几乎每一部分都可以展开成一篇独立的长文,但本文旨在让读者能够快速的了解HBase的架构轮廓,所以很多特性/流程被被一言带过,但这些特性在社区中往往经历了漫长的开发过程。至于讲什么以及讲到什么程度,本文都做了艰难的取舍,在讲解的过程中,将会穿插解答本文开始所提出的针对初学者的一些常见问题。
本文适用于HBase新手,而对于具备一定经验的HBase开发人员,相信本文也可以提供一些有价值的参考。本文内容基于HBase 2.0 beta 2版本,对比于1.0甚至是更早期的版本,2.0出现了大量变化,下面这些问题的答案将揭示部分关键的变化(新手可以直接跳过这些问题):
• HBase meta Region在哪里提供服务?
• HBase是否可以保证单行操作的原子性?
• Region中写WAL与写MemStore的顺序是怎样的?
• 你是否遇到过Region长时间处于RIT的状态? 你认为旧版本中Assignment Manager的主要问题是什么?
• 在面对Full GC问题时,你尝试做过哪些优化?
• 你是否深究过HBase Compaction带来的“写放大”有多严重?
• HBase的RPC框架存在什么问题?
• 导致查询时延毛刺的原因有哪些?
本系列文章的整体行文思路如下:
• 介绍HBase数据模型
• 基于数据模型介绍HBase的适用场景
• 快速介绍集群关键角色以及集群部署建议
• 示例数据介绍
• 写数据流程
• 读数据流程
• 数据更新
• 负载均衡机制
• HBase如何存储小文件数据
这些内容将会被拆成几篇文章。至于集群服务故障的处理机制,集群工具,周边生态,性能调优以及最佳实践等进阶内容,暂不放在本系列文章范畴内。
约定
1. 本文范围内针对一些关键特性/流程,使用了加粗以及加下划线的方式做了强调,如"ProcedureV2"。这些特性往往在本文中仅仅被粗浅提及,后续计划以独立的文章来介绍这些特性/流程。
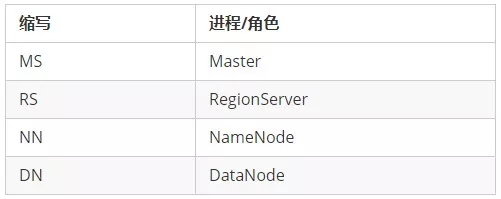
2. 术语缩写:对于一些进程/角色名称,在本文范围内可能通过缩写形式来表述:
数据模型
RowKey
用来表示唯一一行记录的主键,HBase的数据是按照RowKey的字典顺序进行全局排序的,所有的查询都只能依赖于这一个排序维度。
通过下面一个例子来说明一下"字典排序"的原理:
RowKey列表{"abc", "a", "bdf", "cdf", "defg"}按字典排序后的结果为{"a", "abc", "bdf", "cdf", "defg"}
也就是说,当两个RowKey进行排序时,先对比两个RowKey的第一个字节,如果相同,则对比第二个字节,依次类推...如果在对比到第M个字节时,已经超出了其中一个RowKey的字节长度,那么,短的RowKey要被排在另外一个RowKey的前面。
稀疏矩阵
参考了Bigtable,HBase中一个表的数据是按照稀疏矩阵的方式组织的,"开篇"部分给出了一张关于HBase数据表的抽象图,我们再结合下表来加深大家关于"稀疏矩阵"的印象:

看的出来:每一行中,列的组成都是灵活的,行与行之间并不需要遵循相同的列定义, 也就是HBase数据表"schema-less"的特点。
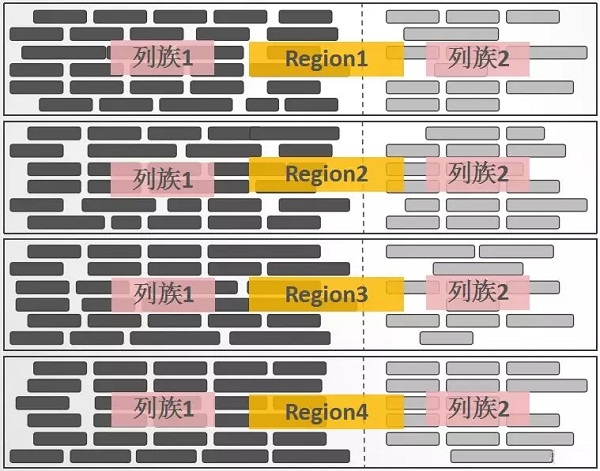
Region
区别于Cassandra/DynamoDB的"Hash分区"设计,HBase中采用了"Range分区",将Key的完整区间切割成一个个的"Key Range" ,每一个"Key Range"称之为一个Region。
也可以这么理解:将HBase中拥有数亿行的一个大表,横向切割成一个个"子表",这一个个"子表"就是Region:

Region是HBase中负载均衡的基本单元,当一个Region增长到一定大小以后,会自动分裂成两个。
Column Family
如果将Region看成是一个表的横向切割,那么,一个Region中的数据列的纵向切割,称之为一个Column Family。每一个列,都必须归属于一个Column Family,这个归属关系是在写数据时指定的,而不是建表时预先定义。
KeyValue
KeyValue的设计不是源自Bigtable,而是要追溯至论文"The log-structured merge-tree(LSM-Tree)"。每一行中的每一列数据,都被包装成独立的拥有特定结构的KeyValue,KeyValue中包含了丰富的自我描述信息:

看的出来,KeyValue是支撑"稀疏矩阵"设计的一个关键点:一些Key相同的任意数量的独立KeyValue就可以构成一行数据。但这种设计带来的一个显而易见的缺点:每一个KeyValue所携带的自我描述信息,会带来显著的数据膨胀。
适用场景
在介绍完了HBase的数据模型以后,我们可以回答本文一开始的前两个问题:
• 什么样的数据适合用HBase来存储?
• 既然HBase也是一个数据库,能否用它将现有系统中昂贵的Oracle替换掉?
HBase的数据模型比较简单,数据按照RowKey排序存放,适合HBase存储的数据,可以简单总结如下:
• 以实体为中心的数据
实体可以包括但不限于如下几种:
• 自然人/账户/手机号/车辆相关数据
• 用户画像数据(含标签类数据)
• 图数据(关系类数据)
描述这些实体的,可以有基础属性信息、实体关系(图数据)、所发生的事件(如交易记录、车辆轨迹点)等等。
• 以事件为中心的数据
• 监控数据
• 时序数据
• 实时位置类数据
• 消息/日志类数据
上面所描述的这些数据,有的是结构化数据,有的是半结构化或非结构化数据。HBase的“稀疏矩阵”设计,使其应对非结构化数据存储时能够得心应手,但在我们的实际用户场景中,结构化数据存储依然占据了比较重的比例。由于HBase仅提供了基于RowKey的单维度索引能力,在应对一些具体的场景时,依然还需要基于HBase之上构建一些专业的能力,如:
• OpenTSDB 时序数据存储,提供基于Metrics+时间+标签的一些组合维度查询与聚合能力
• GeoMesa 时空数据存储,提供基于时间+空间范围的索引能力
• JanusGraph 图数据存储,提供基于属性、关系的图索引能力
HBase擅长于存储结构简单的海量数据但索引能力有限,而Oracle等传统关系型数据库(RDBMS)能够提供丰富的查询能力,但却疲于应对TB级别的海量数据存储,HBase对传统的RDBMS并不是取代关系,而是一种补充。

时间:2018-10-09 22:31 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]大数据关键技术浅谈之大数据存储及管理
- [数据挖掘]HBase数据迁移到Kafka?这种逆向操作你懵逼了吗?
- [数据挖掘]Apache2019年度报告出炉,HBase、Flink、Beam成最活跃
- [数据挖掘]PinalyticsDB:基于HBase的时间序列数据库
- [数据挖掘]PinalyticsDB:基于HBase的时间序列数据库
- [数据挖掘]HBase 2.0 在时序数据存储方向的应用
- [数据挖掘]数据中台是“一把手”工程,动组织肯定会有矛盾
- [数据挖掘]数据中台之结构化大数据存储设计
- [数据挖掘]图解HBase--大数据平台技术栈
- [数据挖掘]快手HBase在千亿级用户特征数据分析中的应用与实
相关推荐:
网友评论:















