Kafka 客户端是如何找到 leader 分区的
我们知道, Kafka 是使用 Scala 语言编写的,但是其支持很多语言的客户端,包括:C/C++、PHP、Go以及Ruby等等(参见https://cwiki.apache.org/confluence/display/KAFKA/Clients)。这是为什么呢?这是因为 Kafka 内部实现了一套基于TCP层的协议,只要使用这种协议与Kafka进行通信,就可以使用很多语言来操作Kafka。
目前 Kafka 内部支持多达30多种协议,本文介绍的 Kafka 客户端是如何找到 leader 分区就涉及到 Kafka 内部的 Metadata 协议。Metadata 协议主要解决以下四种问题:
Kafka中存在哪些主题?
每个主题有几个分区?
Leader分区所在的broker地址及端口?
每个broker的地址及端口是多少?
客户端只需要构造相应的请求,并发送到Broker端,即可获取到上面四个问题的答案。整个过程如下:
客户端构造相应的请求
客户端将请求发送到Broker端
Broker端接收到请求处理,并将结果发送到客户端。
Metadata 请求协议(v0-v3版本)如下:
目前 Metadata 请求协议存在五个版本,v0-v3版本格式一致。但是这些协议存在一个问题:当 Kafka 服务器端将 auto.create.topics.enable 参数设置为 ture 时,如果我们查询的主题不存在,Kafka 将会自动创建这个主题,这很可能不是我们想要的结果。所以,基于这个问题,到了 Metadata 请求协议第五版,格式已经变化了,如下:客户端只需要构造一个 TopicMetadataRequest ,里面包括我们需要查询主题的名字(TopicNames);当然,我们可以一次查询多个主题,只需要将这些主题放进List里面即可。同时,我们还可以不传入任何主题的名字,这时候 Kafka 将会把内部所有的主题相关的信息发送给客户端。

Kafka 的 Broker 收到客户端的请求处理完之后,会构造一个 TopicMetadataResponse,并发送给客户端。TopicMetadataResponse 协议的格式如下:我们可以指定 allow_auto_topic_creation 参数来告诉 Kafka 是否需要在主题不存在的时候创建,这时候控制权就在我们了。

可以看到,相应协议里面包含了每个分区的 Leader、Replicas 以及 Isr 信息,同时还包括了Kafka 集群所有Broker的信息。如果处理出现了问题,会出现相应的错误信息码,主要包括下面几个:
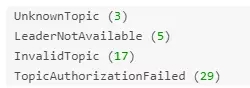
而且,Metadata 协议是目前唯一一个可以向任何 Broker 发送的协议。因为任何一个 Broker 在启动之后会存储这些Metadata信息的。而且,Kafka 提供的客户端在获取到 Metadata 信息之后也会将它存储到内存中的。并且在以下几种情况会更新已经缓存下来的 Metadata 信息:
在往Kafka发送请求是收到 Not a Leader 异常;
在 meta‐data.max.age.ms 参数配置的时间过期之后。
以上两种情况 Kafka提供的客户端会自动再发送一次 Metadata 请求,这样就可以获取到更新的信息。整个过程如下:

好了,说了半天的,我们来看看程序里面如何构造 TopicMetadataRequest 以及处理 TopicMetadataResponse。
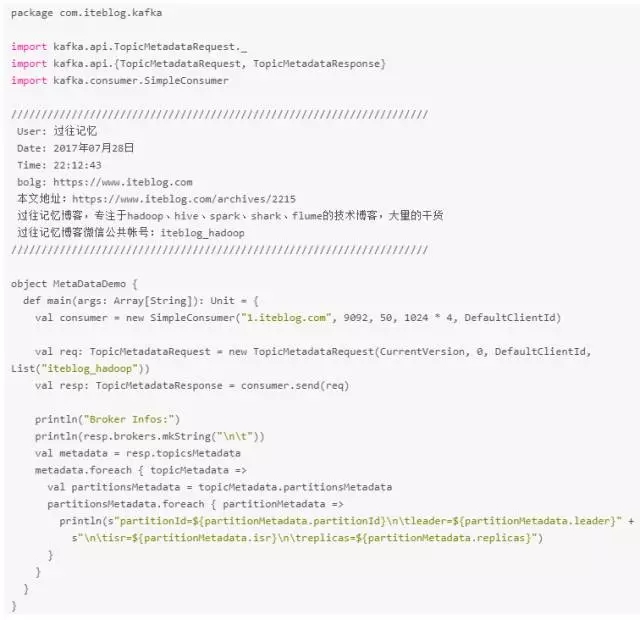
TopicMetadataRequest 是通过 SimpleConsumer 的 send 方法发送的,其返回的是 TopicMetadataResponse ,其中就包含了我们需要的信息。 运行上面的程序输出如下:

上面的输出就可以看到各个分区的leader所在机器、isr以及所有replicas等信息。有一点我们需要注意,因为目前存在多个版本的 Metadata 请求协议,我们可以使用低版本的协议与高版本的Kafka集群进行通信,因为高版本的 Kafka 能够支持低版本的 Metadata 请求协议;但是我们不能使用高版本的 Metadata 请求协议与低版本的 Kafka 通信。

时间:2018-10-09 22:27 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]流数据并行处理性能比较:Kafka vs Pulsar vs Praveg
- [数据挖掘]实时数据仓库必备技术:Kafka 知识梳理
- [数据挖掘]Twitter 把 Kafka 当作存储系统使用
- [数据挖掘]盘点大数据处理引擎
- [数据挖掘]HBase数据迁移到Kafka?这种逆向操作你懵逼了吗?
- [数据挖掘]因为一次 Kafka 宕机,我明白了 Kafka 高可用原理!
- [数据挖掘]Kafka面试知识点深度剖析
- [数据挖掘]图文了解 Kafka 的副本复制机制
- [数据挖掘]Kafka 集群在马蜂窝大数据平台的优化与应用扩展
- [数据挖掘]Kafka加Flink不是终点!下一代大数据平台Pravega
相关推荐:
网友评论:















