数据挖掘领域十大经典算法之—C4.5算法(超详细

简介
C4.5是决策树算法的一种。决策树算法作为一种分类算法,目标就是将具有p维特征的n个样本分到c个类别中去。常见的决策树算法有ID3,C4.5,CART。
基本思想
下面以一个例子来详细说明C4.5的基本思想

上述数据集有四个属性,属性集合A={ 天气,温度,湿度,风速}, 类别标签有两个,类别集合L={进行,取消}。
1. 计算类别信息熵
类别信息熵表示的是所有样本中各种类别出现的不确定性之和。根据熵的概念,熵越大,不确定性就越大,把事情搞清楚所需要的信息量就越多。

2. 计算每个属性的信息熵
每个属性的信息熵相当于一种条件熵。他表示的是在某种属性的条件下,各种类别出现的不确定性之和。属性的信息熵越大,表示这个属性中拥有的样本类别越不“纯”。

3. 计算信息增益
信息增益的 = 熵 - 条件熵,在这里就是 类别信息熵 - 属性信息熵,它表示的是信息不确定性减少的程度。如果一个属性的信息增益越大,就表示用这个属性进行样本划分可以更好的减少划分后样本的不确定性,当然,选择该属性就可以更快更好地完成我们的分类目标。
信息增益就是ID3算法的特征选择指标。

但是我们假设这样的情况,每个属性中每种类别都只有一个样本,那这样属性信息熵就等于零,根据信息增益就无法选择出有效分类特征。所以,C4.5选择使用信息增益率对ID3进行改进。
4.计算属性分裂信息度量
用分裂信息度量来考虑某种属性进行分裂时分支的数量信息和尺寸信息,我们把这些信息称为属性的内在信息(instrisic information)。信息增益率用信息增益 / 内在信息,会导致属性的重要性随着内在信息的增大而减小(也就是说,如果这个属性本身不确定性就很大,那我就越不倾向于选取它),这样算是对单纯用信息增益有所补偿。

5. 计算信息增益率
(下面写错了。。应该是IGR = Gain / H )

天气的信息增益率最高,选择天气为分裂属性。发现分裂了之后,天气是“阴”的条件下,类别是”纯“的,所以把它定义为叶子节点,选择不“纯”的结点继续分裂。

在子结点当中重复过程1~5。
至此,这个数据集上C4.5的计算过程就算完成了,一棵树也构建出来了。
总结算法流程为:

优缺点
优点
产生的分类规则易于理解,准确率较高。
缺点
在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。
代码
代码已在github上实现,这里也贴出来

测试数据集为MNIST数据集,获取地址为train.csv
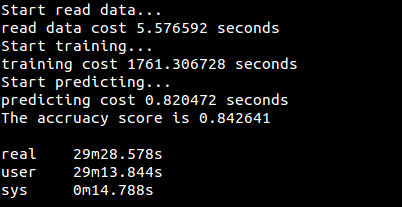
运行结果

时间:2018-10-09 22:27 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















