大数据-Hadoop小文件问题解决方案
HDFS中小文件是指文件size小于HDFS上block 大小的文件。大量的小文件会给Hadoop的扩展性和性能带来严重的影响。
大小的文件。大量的小文件会给Hadoop的扩展性和性能带来严重的影响。
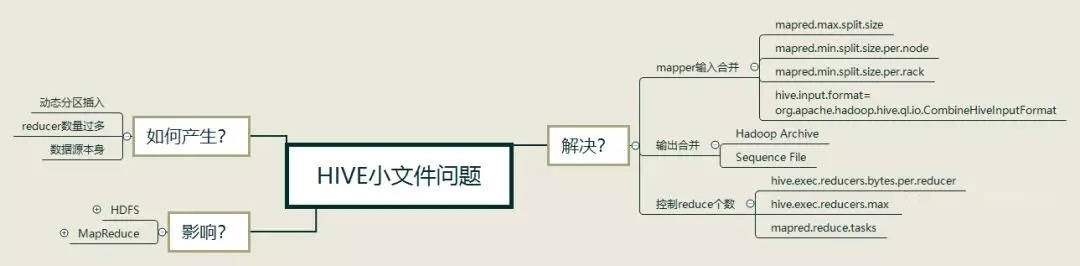
小文件是如何产生的?
动态分区插入数据,产生大量的小文件,从而导致map数量剧增
reduce数量越多,小文件也越多,reduce的个数和输出文件个数一致
数据源本身就是大量的小文件
小文件问题的影响
从Mapreduce的角度看,一个文件会启动一个map,所以小文件越多,map也越多,一个map启动一个jvm去执行,所以这些任务的初始化,启动,执行会浪费大量的资源,严重的影响性能。
从HDFS角度看,HDFS中文件元信息(位置,大小,分块等)保存在NameNode的内存中,每个对象大约占用150字节,如果小文件过多,会占用大量内存,直接影响NameNode的性能;HDFS读写小文件也会更加耗时,因为每次都需要从NameNode获取元信息,并与对应的DataNode建立连接。
如何解决小文件问题
输入合并,在Map前合并小文件
输出合并,在输出结果的时候合并小文件
控制reduce个数来实现减少小文件个数
配置Map输入合并
可以通过在输入mapper的之前将是输入合并,以减少map的个数。

配置Hive输出结果合并

Hadoop Archive(HAR)
Hadoop Archive是一种特殊的归档格式,Hadoop Archive映射到文件系统目录,一个HAR是以扩展名.har结尾 ,一个HAR目录包含元数据(以_index和_masterindex的形式)和data(part-*)文件。_index文件包含文件名称,这些文件是归档的一部分,并且包含这些文件在归档中的位置。
Hadoop Archive是一个高效地将小文件放入HDFS块中的文件存档工具,它能将多个小文件打包成一个HAR文件,这样在减少NameNode内存使用的同时,仍然允许对文件进行透明的访问。
• 使用hadoop命令进行文件归档
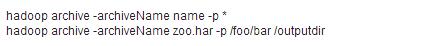
可以通过设置 参数来指定HAR的大小。
参数来指定HAR的大小。
• 在Hive中进行归档处理
Hive支持将已存的分区转换为HAR,从而使得分区下的文件数目大大减少。但是从HAR读数据需要额外的开销,因此查询归档下数据可能会变慢。

如果不是分区表,可以创建成外部表,使用har://协议来指定路径。
SequenceFile
控制reducer个数
为了提升MR的运算速度,可以通过增加reducer的个数,Hive也会做类似的优化,Reducer数量等于源数据量除以 所配置的量(默认是1G)。Reducer的数量决定了结果文件的数量。所以在合适的情况下控制reducer的数量,可以实现减少小文件数量。
所配置的量(默认是1G)。Reducer的数量决定了结果文件的数量。所以在合适的情况下控制reducer的数量,可以实现减少小文件数量。
• reducer决定因素:

时间:2018-10-09 22:27 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















