hadoop+Spark+hbase集群动态增加节点
已有集群:
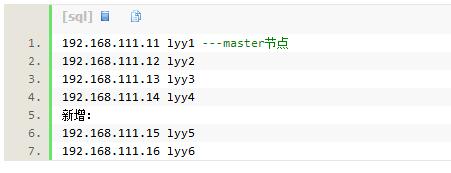
开始:
1.从lyy1节点克隆出两台虚拟机,保证所有配置和软件一样,然后修改ip和hostname
(本集群是基于proxmox的虚拟集群,可以很方便的复制、开关虚拟机等,如果是物理集群可以把master节点镜像拷贝给新节点)
2.修改vim /etc/hosts,加入ip映射。使用批处理命令并同步到所有机器

同时还要修改hadoop的workers,spark的slaves,hbase的regionservers,增加主机名
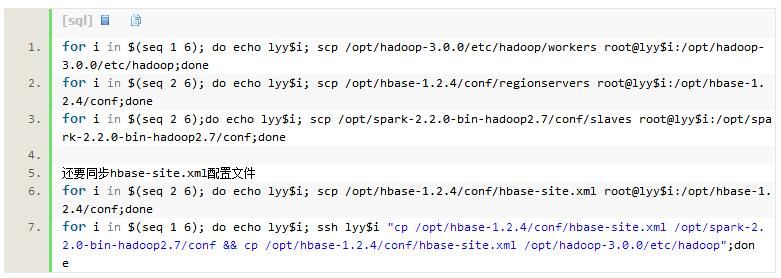
注:不用重启集群,直接在新增的节点上分别启动以下进程即可:
3.hadoop增加datanode节点

4.spark新增worker节点

5.hbase新增RegionServer

6.负载均衡
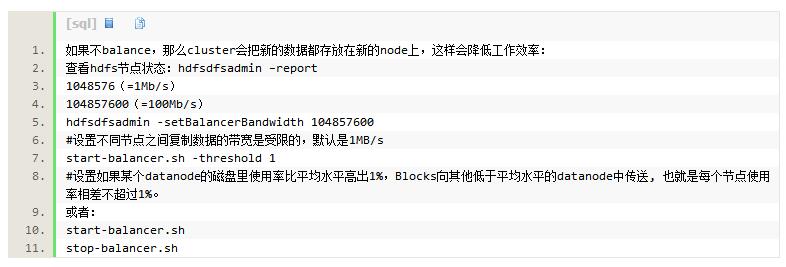
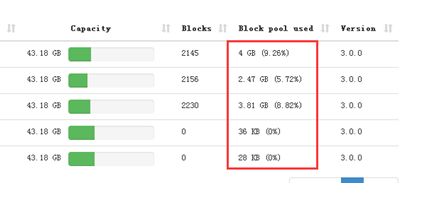
负载均衡之前的使用率
负载均衡之后各节点硬盘使用率趋于平衡:
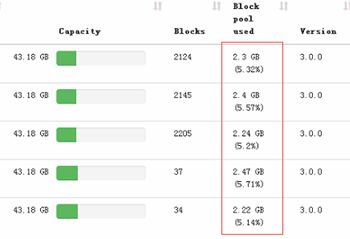
负载均衡之后的使用率
此外Hbase也需要负载均衡:
hbase shell中输入: balance_switch true
至此可以就完成了节点扩展,现在集群已经有6个节点了,可以分别在hadoop、spark、hbase的监控页面上查看到节点。

时间:2018-10-09 22:27 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















