Python实践:seaborn的散点图矩阵(Pairs Plots)可视
一旦你有了一个很好的被清理过的数据集,下一步就是探索性数据分析(EDA)。EDA是确定数据可以告诉我们的过程,我们使用EDA来查找模式、关系或异常情况,以便指导我们后续的工作。然而在EDA中有很多的方法,但最有效的工具之一是对图(也称为散点图矩阵)。散点图矩阵让我们看到了两个变量之间的关系。散点图矩阵是识别后续分析趋势的好方法,幸运的是,它们很容易用Python实现!
在本文中,我们将通过使用seaborn可视化库在Python中进行对图的绘制和运行。我们将看到如何创建默认配对图以快速检查我们的数据,以及如何自定义可视化以获取更深入的洞察力。该项目的代码在GitHub上以Jupyter Notebook的形式提供。在这个项目中,我们将探索一个真实世界的数据集,由GapMinder收集的国家级社会经济数据组成。
Seaborn的散点图矩阵(Pairs Plots)
在开始之前,我们需要知道我们有什么数据。我们可以将社会经济数据用熊猫(Pandas)数据框加载并查看列:
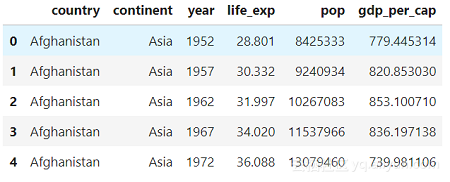
每行数据代表一个国家在一年内的结果,列中包含变量(这种格式的数据称为整洁数据)。有2个分类专栏(国家和大陆)和4个数字专栏。这些专栏包括:life_exp是几年出生时的预期寿命,pop是人口,gdp_per_cap是以国际美元为单位的人均国内生产总值。
虽然后面我们将使用分类变量进行着色,但seaborn中的默认对图仅绘制了数字列。创建默认的散点图矩阵很简单:我们加载到seaborn库并调用pairplot函数,将它传递给我们的数据框:
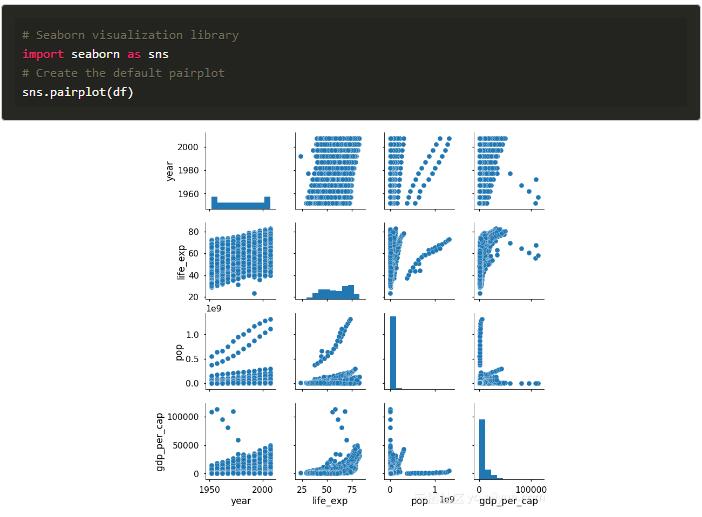
我仍然惊讶于一行简单的代码就可以完成我们整个需求!散点图矩阵建立在两个基本图形上,直方图和散点图。对角线上的直方图允许我们看到单个变量的分布,而上下三角形上的散点图显示了两个变量之间的关系。例如,第二行中最左边的图表显示life_exp与年份的散点图。
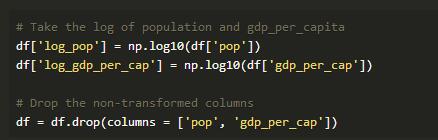
默认的散点图矩阵图经常给我们提供有价值的见解。我们看到人均预期寿命和人均GDP是正相关的,这表明高收入国家的人们倾向于更长寿(尽管这当然不能证明导致其他人也是如此)。它也似乎看起来是全世界的预期寿命随着时间的推移而上升。为了在未来的图中更好地显示这些变量,我们可以通过取这些值的对数来转换这些列:
虽然这种制图本身可以用于分析,但我们可以发现,通过对诸如大陆这样的分类变量进行数字着色,使其更有价值。这在seaborn中非常简单!我们所需要做的就是在hue中使用sns.pairplot函数调用使用关键字:
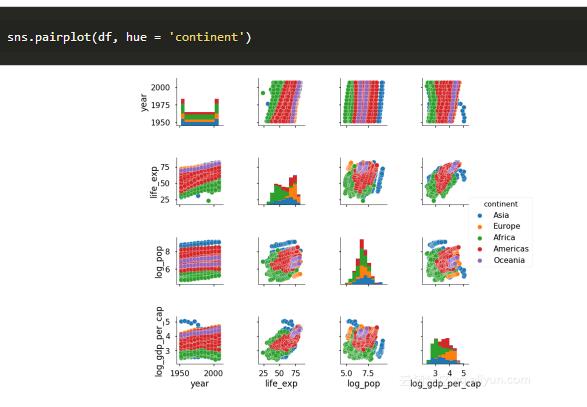
现在我们看到大洋洲和欧洲的人均预期寿命最高,亚洲人口最多。请注意,我们对人口和gdp的日志转换使这些变量正态分布,从而更全面地表示值。
上图更具信息性,但仍然存在一些问题:找不到叠加的直方图,就像在对角线上那样,它非常易于理解。显示来自多个类别的单变量分布的更好方法是密度图。我们可以在函数调用中交换柱状图的密度图。当我们处理它时,我们会将一些关键字传递给散点图,以更改点的透明度,大小和边缘颜色。

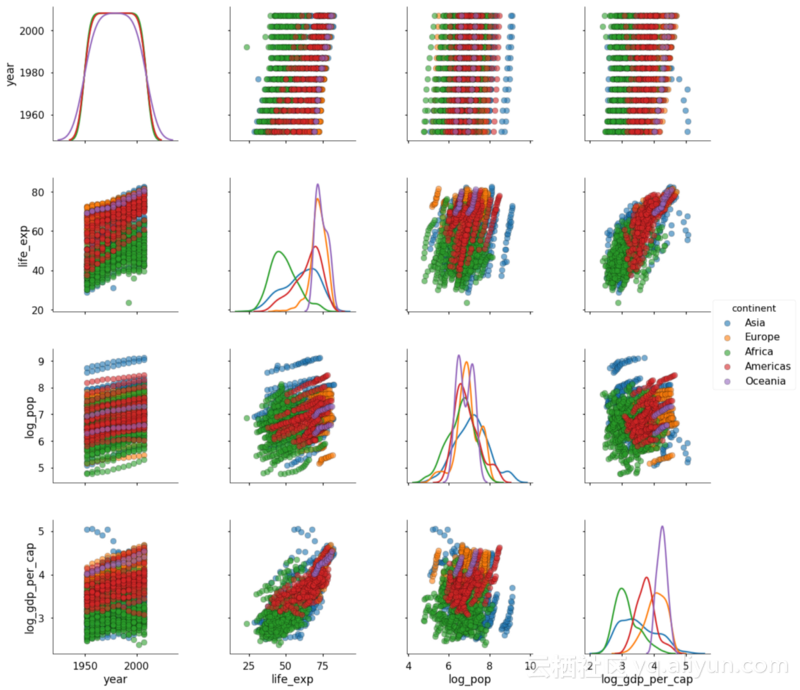
对角线上的密度图比堆积条更容易比较各大洲之间的分布。改变散点图的透明度可以提高可读性,因为这些数字有相当多的重叠(称为重叠绘图)。
作为pairplot默认的最后一个例子,让我们通过绘制2000年后的年份来减少数据混乱。我们仍然会按照大陆分布着色,但现在我们不会绘制年份列。为了限制绘制的列,我们将一个列表传递vars给函数。为了说明情节,我们还可以添加标题。

这开始看起来很不错!如果我们要进行建模,我们可以使用这些图中的信息来帮助我们进行选择。例如,我们知道log_gdp_per_cap与life_exp正相关,所以我们可以创建一个线性模型来量化这种关系。对于这篇文章,我们将坚持绘图,如果我们想要更多地探索我们的数据,我们可以使用PairGrid类自定义散点图矩阵。
使用PairGrid进行自定义
与sns.pairplot函数相反,sns.PairGrid是一个类,它意味着它不会自动填充我们的网格plot。相反,我们创建一个类实例,然后将特定函数映射到网格的不同部分。要用我们的数据创建一个PairGrid实例,我们使用下面的代码,这也限制了我们将显示的变量:
如果我们要显示它,我们会得到一个空白图,因为我们没有将任何函数映射到网格部分。有三个网格部分填写PairGrid:上三角形、下三角形和对角线。要将网格映射到这些部分,我们使用grid.map 部分中的方法。例如,要将散点图映射到我们使用的上三角形:

该map_upper方法接受任何两个变量数组(如plt.scatter)和关联的关键字(如color)的函数。该map_lower方法完全相同,但填充网格的下三角形。因为它需要在接受单个阵列(记住对角线仅示出了一个变量)的函数略有不同。一个例子是plt.hist我们用来填写下面的对角线部分:
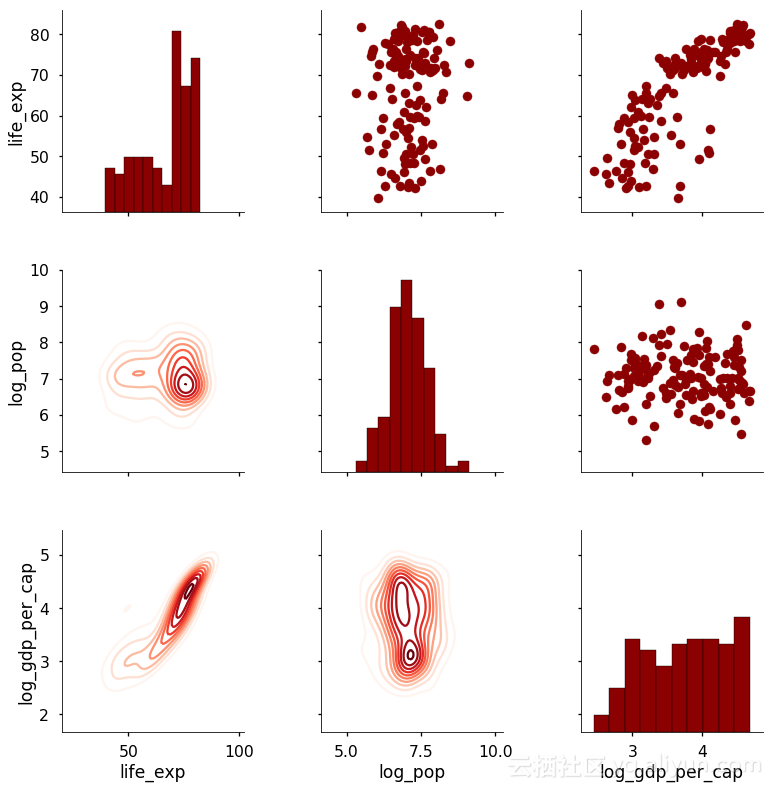
在这种情况下,我们在下三角形中使用2-D(密度图)的核密度估计值。放在一起,这段代码给了我们下面的图:
使用PairGrid类的真正好处在于我们想要创建自定义函数来将不同的信息映射到图上。例如,我可能想要将两个变量之间的Pearson相关系数添加到散点图中。为此,我会编写一个函数,它接受两个数组、计算统计量,然后在图上绘制它。下面的代码显示了这是如何完成的(归功于这个Stack Overflow答案):
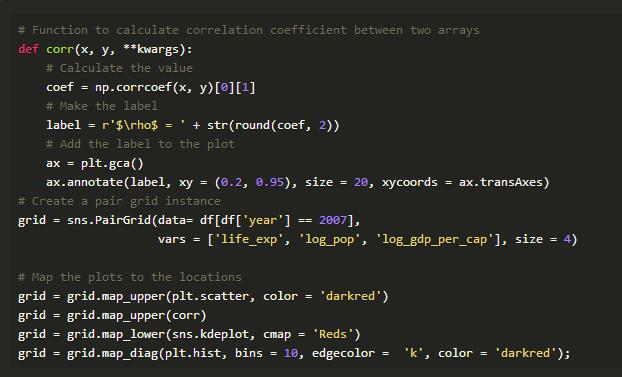
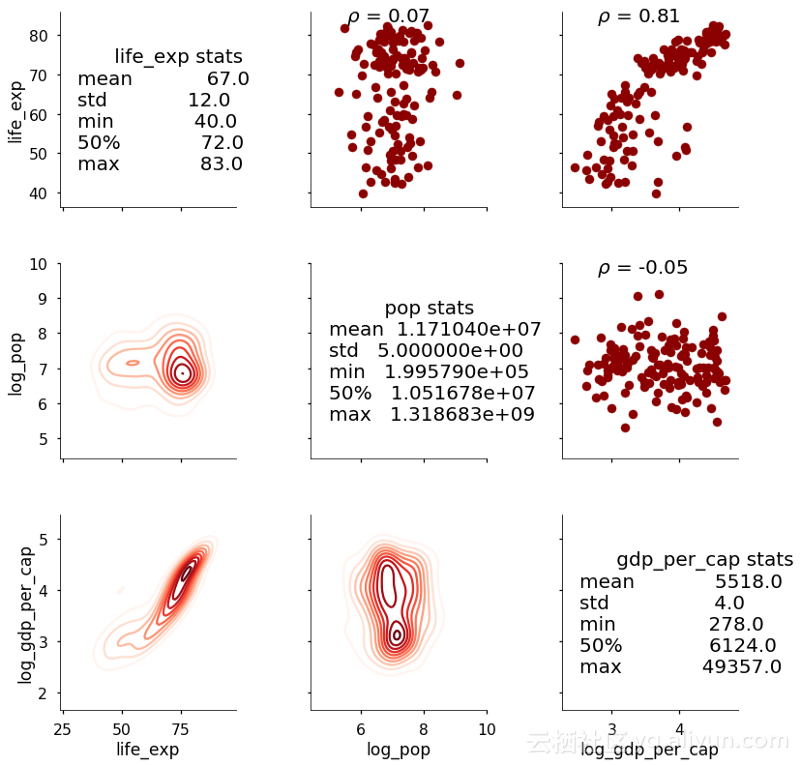
我们的新函数映射到上三角形,因为我们需要两个数组来计算相关系数(还要注意我们可以将多个函数映射到网格部分)。这会产生以下图形:

相关系数现在出现在散点图上方。这是一个相对直接的例子,但我们可以使用PairGrid将我们想要的任何函数映射到图上。我们可以根据需要添加尽可能多的信息,只要我们能够弄清楚如何编写函数!作为最后一个例子,这里是一个显示对角线而不是网格的汇总统计图。
它显示了我们只做图标的总体思路,除了使用库中的任何现有功能(例如matplotlib将数据映射到图上)之外,我们还可以编写自己的函数来显示自定义信息。
结论
散点图矩阵是快速探索数据集中的分布和关系的强大工具。Seaborn提供了一个简单的默认方法,可以通过Pair Grid类来定制和扩展散点图矩阵。在一个数据分析项目中,价值的主要部分往往不在于浮华的机器学习,而在于直观的数据可视化。散点图举证为我们提供了全面的数据分析,是数据分析项目的一个很好的起点。

时间:2018-10-09 22:27 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]底层I/O性能大PK:Python/Java被碾压,Rust有望取代
- [数据挖掘]大数据分析的技术有哪些?
- [数据挖掘]大数据分析会遇到哪些难题?
- [数据挖掘]RedMonk语言排行:Python力压Java,Ruby持续下滑
- [数据挖掘]不得了!Python 又爆出重大 Bug~
- [数据挖掘]TIOBE 1 月榜单:Python年度语言四连冠,C 语言再次
- [数据挖掘]TIOBE12月榜单:Java重回第二,Python有望四连冠年度
- [数据挖掘]这个可能打败Python的编程语言,正在征服科学界
- [数据挖掘]2021年编程语言趋势预测:Python和JavaScript仍火热,
- [数据挖掘]Spark 3.0重磅发布!开发近两年,流、Python、SQL重
相关推荐:
网友评论:















