如何避免HBase写入过快引起的各种问题
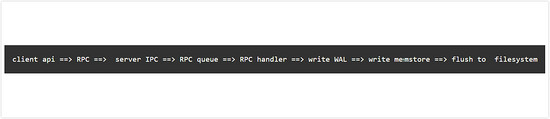
整个写入流程从客户端调用API开始,数据会通过protobuf编码成一个请求,通过scoket实现的IPC模块被送达server的RPC队列中。最后由负责处理RPC的handler取出请求完成写入操作。写入会先写WAL文件,然后再写一份到内存中,也就是memstore模块,当满足条件时,memstore才会被flush到底层文件系统,形成HFile。
当写入过快时会遇见什么问题?
写入过快时,memstore的水位会马上被推高。
你可能会看到以下类似日志:
这个是Region的memstore占用内存大小超过正常的4倍,这时候会抛异常,写入请求会被拒绝,客户端开始重试请求。当达到128M的时候会触发flush memstore,当达到128M * 4还没法触发flush时候会抛异常来拒绝写入。两个相关参数的默认值如下:

或者这样的日志:

这是所有region的memstore内存总和开销超过配置上限,默认是配置heap的40%,这会导致写入被阻塞。目的是等待flush的线程把内存里的数据flush下去,否则继续允许写入memestore会把内存写爆

当写入被阻塞,队列会开始积压,如果运气不好最后会导致OOM,你可能会发现JVM由于OOM crash或者看到如下类似日志:

HBase这里我认为有个很不好的设计,捕获了OOM异常却没有终止进程。这时候进程可能已经没法正常运行下去了,你还会在日志里发现很多其它线程也抛OOM异常。比如stop可能根本stop不了,RS可能会处于一种僵死状态。
如何避免RS OOM?
一种是加快flush速度:

当达到hbase.hstore.blockingStoreFiles配置上限时,会导致flush阻塞等到compaction工作完成。阻塞时间是hbase.hstore.blockingWaitTime,可以改小这个时间。hbase.hstore.flusher.count可以根据机器型号去配置,可惜这个数量不会根据写压力去动态调整,配多了,非导入数据多场景也没用,改配置还得重启。
同样的道理,如果flush加快,意味这compaction也要跟上,不然文件会越来越多,这样scan性能会下降,开销也会增大。

增加compaction线程会增加CPU和带宽开销,可能会影响正常的请求。如果不是导入数据,一般而言是够了。好在这个配置在云HBase内是可以动态调整的,不需要重启。
上述配置都需要人工干预,如果干预不及时server可能已经OOM了,这时候有没有更好的控制方法?
直接限制队列堆积的大小。当堆积到一定程度后,事实上后面的请求等不到server端处理完,可能客户端先超时了。并且一直堆积下去会导致OOM,1G的默认配置需要相对大内存的型号。当达到queue上限,客户端会收到CallQueueTooBigException 然后自动重试。通过这个可以防止写入过快时候把server端写爆,有一定反压作用。线上使用这个在一些小型号稳定性控制上效果不错。

时间:2018-10-09 22:27 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]大数据关键技术浅谈之大数据存储及管理
- [数据挖掘]HBase数据迁移到Kafka?这种逆向操作你懵逼了吗?
- [数据挖掘]Apache2019年度报告出炉,HBase、Flink、Beam成最活跃
- [数据挖掘]PinalyticsDB:基于HBase的时间序列数据库
- [数据挖掘]PinalyticsDB:基于HBase的时间序列数据库
- [数据挖掘]HBase 2.0 在时序数据存储方向的应用
- [数据挖掘]数据中台是“一把手”工程,动组织肯定会有矛盾
- [数据挖掘]数据中台之结构化大数据存储设计
- [数据挖掘]图解HBase--大数据平台技术栈
- [数据挖掘]快手HBase在千亿级用户特征数据分析中的应用与实
相关推荐:
网友评论:















