hdfs,mapreduce相关流程总结
写
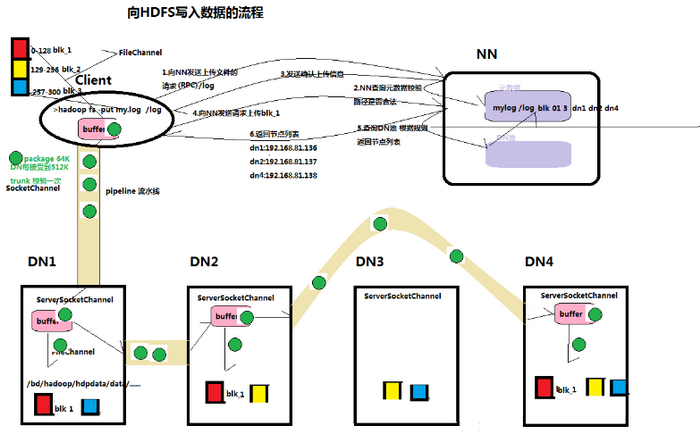
1)client向namenode发送请求,namenode从元数据中检查目标文件是否存在,上传路径路径是否合法
2)namenode返回是否可以上传文件,假设可以上传
3)client请求第一个 block该传输到哪些datanode服务器上
4)namenode返回可以上传的datanode 服务器dn1 dn2 dn4
5)client将于datanode中最近的一个datanode 建立RPC连接 ,形成pipeline 通道 , pipeline会连接所有将被上传的datanode机器,
6)、client开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn4
7)当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。最终完成上传
读
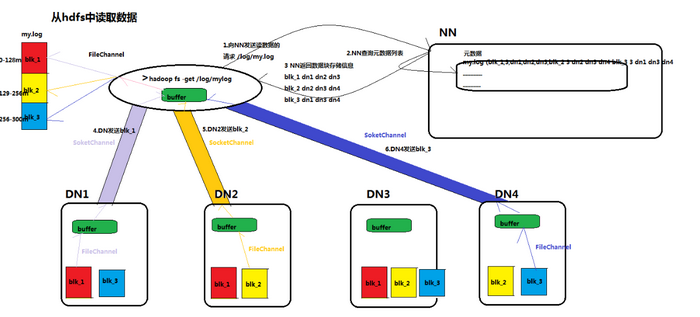
1)client向namenode通信查询元数据,找到存放block文件的datanode
2)挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流 利用FileChannel读取数据
3)datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
4)客户端以packet为单位接收,现在本地缓存,然后写入目标文件
mapreduce的执行流程 (大体流程)
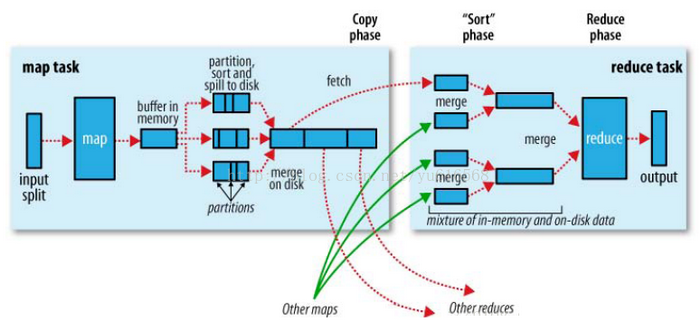
1、 一个mr程序启动的时候,最先启动的是MRAppMaster,MRAppMaster启动后根据本次job的描述信息,计算出需要的maptask实例数量,然后向集群申请机器启动相应数量的maptask进程
2、 maptask进程启动之后,根据给定的数据切片范围进行数据处理,主体流程为:T
a) 利用客户指定的inputformat来获取RecordReader读取数据,形成输入KV对
b) 将输入KV对传递给客户定义的map()方法,做逻辑运算,并将map()方法输出的KV对收集到缓存
c) 将缓存中的KV对按照K分区排序后不断溢写到磁盘文.件
3、 MRAppMaster监控到所有maptask进程任务完成之后,会根据客户指定的参数启动相应数量的reducetask进程,并告知reducetask进程要处理的数据范围(数据分区)
4、 Reducetask进程启动之后,根据MRAppMaster告知的待处理数据所在位置,从若干台maptask运行所在机器上获取到若干个maptask输出结果文件,并在本地进行重新归并排序,然后按照相同key的KV为一个组,调用客户定义的reduce()方法进行逻辑运算,并收集运算输出的结果KV,然后调用客户指定的outputformat将结果数据输出到外部存储
mapTast 的 并行机制
一个job的map阶段并行度由客户端在提交job时决定。而客户端对应map阶段并行度的划分规则:
将文件划分为多个split 每个split 交给一个mapTast进行处理 一个split的大小默认为128MB
切片的形成是由FileInputFormat实现类的getSplits()方法完成,
如果input的文件非常的大,比如1TB,可以考虑将hdfs上的每个block size设大,比如设成256MB或者512MB
如果input的文件的文件非常小 ,且非常多 启动多个maptast明显会降低程序的效率 , 可以先将小文件合并成大文件 再交给mapreduce处理
FileInputFormat切片机制
1、切片定义在InputFormat类中的getSplit()方法
2、FileInputFormat中默认的切片机制:
简单地按照文件的内容长度进行切片 切片大小,默认等于block大小 切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
比如待处理数据有两个文件:
file1.txt 320M
file2.txt 10M
经过FileInputFormat的切片机制运算后,形成的切片信息如下:
file1.txt.split1-- 0~128
file1.txt.split2-- 128~256
file1.txt.split3-- 256~320
file2.txt.split1-- 0~10M
3、FileInputFormat中切片的大小的参数配置
通过分析源码,在FileInputFormat中,计算切片大小的逻辑:Math.max(minSize, Math.min(maxSize, blockSize)); 切片主要由这几个值来运算决定
minsize:默认值:1
配置参数:
mapreduce.input.fileinputformat.split.minsize
maxsize:默认值:Long.MAXValue
配置参数:mapreduce.input.fileinputformat.split.maxsize
blocksize
因此,默认情况下,切片大小=blocksize
maxsize(切片最大值):
参数如果调得比blocksize小,则会让切片变小,而且就等于配置的这个参数的值
minsize (切片最小值):
参数调的比blockSize大,则可以让切片变得比blocksize还大
选择并发数的影响因素:
运算节点的硬件配置 运算任务的类型:CPU密集型还是IO密集型 运算任务的数据量
ReduceTask并行度的决定
这个是由我们自己设置的
//默认值是1,手动设置为4
job.setNumReduceTasks(4);
如果数据分布不均匀,就有可能在reduce阶段产生数据倾斜
注意: reducetask数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个reducetask
尽量不要运行太多的reduce task。对大多数job来说,最好rduce的个数最多和集群中的reduce持平,或者比集群的 reduce slots小。这个对于小集群而言,尤其重要。
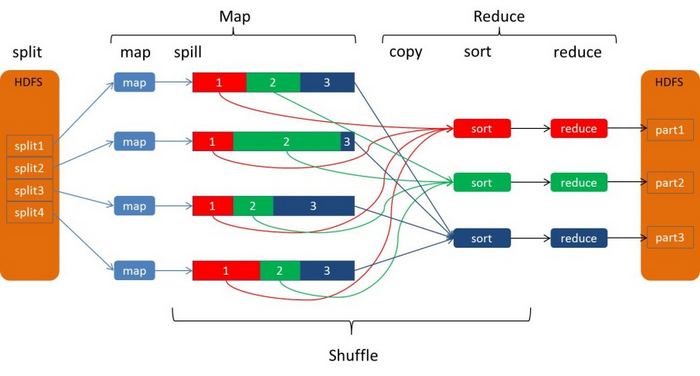
mapreduce的shuffle机制(只能简单概述一下以统计统计单词为例)
shuffle 分为map端和reduce端
map端
当map函数通过context.write()开始输出数据数,outputCollector将数据以
环形缓冲区(kvbuffer) 默认大小为100 实际上是是一个 字节数组 ,其中包括了数据区,和索引区 当输出到环形缓冲区的数据达到阀值的时候,
默认为80% 系统就会开启一个线程将数据写入磁盘, 这个过程叫做spill (索引区的内容保存在内存, 也肯也写入到文件中)
在写入之前 , 通过调用Partitioner的getPartition(),计算出数据要分到那个reduce,将这个信息同数据一起保存kvbuffer, 并对数据的key进行了一个快速排序(QuickSort)
排序后的数据被写入到mapreduce.cluster.local.dir配置的目录中的其中一个,Spill文件名像sipll0.out,spill1.out等
最后, 多个spill小文件 ,会合并成一个大文件 (这里进行了一个合并排序, 分区),并最终形成一个唯一大文件 以及相对于的索引文件 建立索引文件是为了方便进行数据的查找,

Reducer端
Reducer端的shuffle主要包括三个阶段,copy、sort(merge)和reduce。
copy: Mrappmaster告知reduce ,mapTast的位置 , 每个Reducer只获取属于自己分区的数据
sort:这个阶段按照 ,在每个reduce对自己这个分区的数据 进行一个归并排序 ,
reduce: 合并后的文件作为输入传递给Reducer,Reducer针对每个key及其排序的数据调用reduce函数。产生的reduce输出一般写入到HDFS

时间:2018-10-09 22:18 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]Oracle 行贿 10 万元:中标 1980 万元数据库项目
- [数据挖掘]面对业务增长,Uber是如何扩展HDFS文件系统的
- [数据挖掘]Router-Based HDFS Federation 在滴滴大数据的应用
- [数据挖掘]HDFS监控背后那些事儿,构建Hadoop监控共同体
- [数据挖掘]一套很专业的监控方案:HDFS监控落地背后的思考
- [数据挖掘]深入理解Hadoop之HDFS架构
- [数据挖掘]Hadoop 2.x HDFS和YARN的启动方式
- [数据挖掘]在shell中如何判断HDFS中的文件目录是否存在
- [数据挖掘]Flume + kafka + HDFS构建日志采集系统
相关推荐:
网友评论:















