Streaming metadate checkpoint详解
如何checkpoint
如果要对metadata做checkpoint,首先要有一个可靠的文件系统保证数据的安全性,spark支持hdfs等。通过代码streamingContext.checkpoint(checkpointDirectory)指定具体的存储路径;
jobGenerator在每一个batch时间后调用generateJobs方法,在jobScheduler.submitJobSet提交任务后,执行doCheckpoint方法来保存metadata;
doCheckpoint方法中先判断是否需要checkpoint,条件为ssc.checkpointDuration != null && ssc.checkpointDir != null,最重要的是指定后面的ssc.checkpointDir指定路径,再判断是否到时间,如果满足条件进行正式代码;
通过ssc.graph.updateCheckpointData(time)调用DStream的updateCheckpointData,从而执行每个DStream子类的checkpointData.update(currentTime),以DirectKafkaInputDStream为例,最后执行的是DirectKafkaInputDStreamCheckpointData的update,目的是更新要持久的源数据checkpointData.data;通过dependencies.foreach(_.updateCheckpointData(currentTime))使所有依赖的DStream执行;

所有DStream都执行完update后,执行CheckpointWriter.write(new Checkpoint(ssc, time), clearCheckpointDataLater),本次batchcheckpoint完成;
当jobGenerator接收到batch完成事件后,通过jobGenerator.onBatchCompletion(jobSet.time)调用clearMetadata方法,最后执行DStream的clearMetadata删除generatedRDDs的过期RDD的metadata。
如何恢复
要从checkpoint中恢复,在创建StreamingContext时略有不同,代码如图

StreamingContext的getOrCreate方法中,先通过CheckpointReader.read( checkpointPath, new SparkConf(), hadoopConf, createOnError)反序列化出Checkpoint,如果Checkpoint不为空即路径存在且有数据,使用StreamingContext(null, _, null)构造方法创建StreamingContext;
StreamingContext.start后,在使用DStreamGraph的实例时时会判断此实例为新创建或从checkpoint中恢复,如从checkpoint中恢复,则执行graph.restoreCheckpointData(),通过DStream的restoreCheckpointData最终调用DStream子类内部的DStreamCheckpointData.restore将保存的RDD metadata写回到generatedRDDs里;
同时jobGenerator在start时,判断ssc.isCheckpointPresent,实际就是判断ssc里面的cp_是否有值从而执行restart方法。restart方法首先从checkpoint的时间开始恢复任务,然后生成从最后时间到restartTime时间序列;
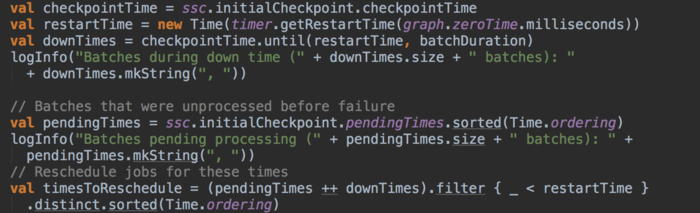
调用graph.generateJobs生成job,在方法内会调用DStream的generateJobs时,在getOrCompute方法通过上面还原的generatedRDDs获取对应时间的RDD源数据信息,如果没有再重新生成,最后提交任务。

创建与恢复区别
先看一下Checkpoint中包括哪些信息:
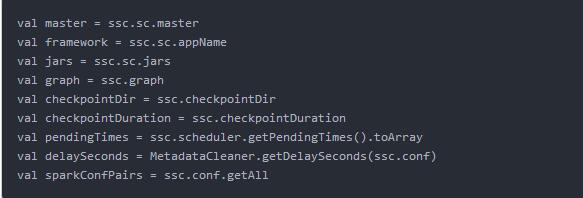
以上数据都是通过反序列化恢复得到的,对新程序的所有的配置都不会生效,比如队列、资源数等。
恢复checkpoint时,从文件系统反序列化数据成CheckPoint的具体代码为Checkpoint.deserialize(fis, conf),所以还原的信息要与当前编译的serialVersion一致,否则会出现异常
在jobGenerator中,新创建的StreamingContext调用的是startFirstTime方法,会初始化DStream的一些数据;而checkpoint恢复调用的是restart。

时间:2018-10-09 22:18 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















