spark2.1.0之配置与源码分析
Spark作为一款优秀的计算框架,也配备了各种各样的系统配置参数(例如:spark.master,spark.app.name,spark.driver.memory,spark.executor.memory等)。通过这些配置参数可以定义应用的名称、使用的部署模式、调度模式、executor数量、executor的内核数、driver或executor的内存大小、采用的内存模型等。
SparkConf是Spark的配置类,这个类在Spark的历史版本中已经存在很久了,http://www.raincent.com/list-10-1.html中的每一个组件都直接或者间接的使用着它所存储的属性,这些属性都存储在如下的数据结构中:

由以上代码的泛型[1] 可以看出Spark的所有配置,无论是key还是value都是String类型。Spark的配置通过以下三种方式获取:
来源于系统参数(即使用System.getProperties获取的属性)中以spark.作为前缀的那部分属性;
使用SparkConf的API进行设置;
从其它SparkConf中克隆。
下面将具体说明这三种方式的实现。
系统属性中的配置
在SparkConf中有一个Boolean类型的构造器属性loadDefaults,当loadDefaults为true时将会从系统属性中加载Spark配置,代码如下:
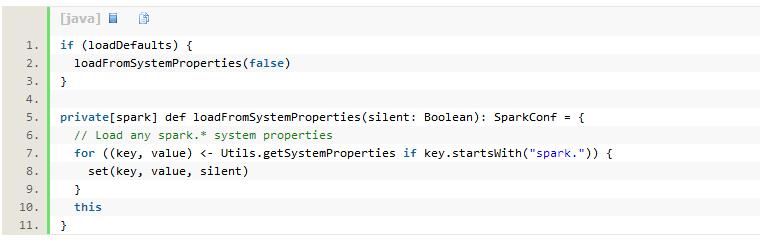
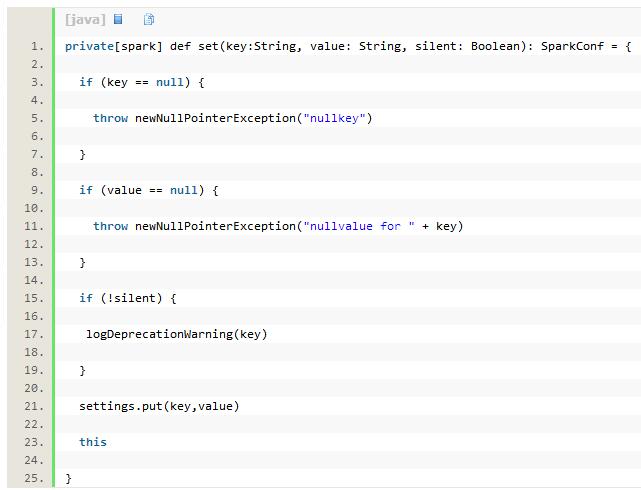
以上代码调用了Utils工具类[2] 的getSystemProperties方法,其作用为获取系统的键值对属性。loadFromSystemProperties方法在获取了系统属性后,使用Scala守卫过滤出其中以“spark.”字符串为前缀的key和value并且调用set方法(见代码清单3-1)最终设置到settings中。
代码清单3-1 SparkConf中set方法的实现
使用SparkConf配置的API
给SparkConf添加配置的一种常见方式是使用SparkConf中提供的API。其中有些API最终实际调用了set的重载方法,见代码清单3-2。
代码清单3-2 SparkConf中重载的set方法
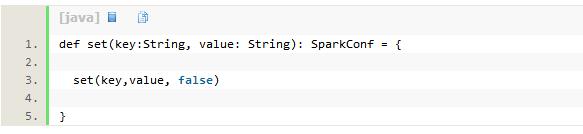
可以看到代码清单3-2中的set方法实际也是调用了代码清单3-1中的set方法。
SparkConf中的setMaster、setAppName、setJars、setExecutorEnv、setSparkHome、setAll等方法最终都是通过代码清单3-2中的set方法完成Spark配置的,本书以其中最为常用的setMaster和setAppName为例,用代码清单3-3和代码清单3-4来展示他们的实现。
代码清单3-3 设置Spark的部署模式的配置方法setMaster
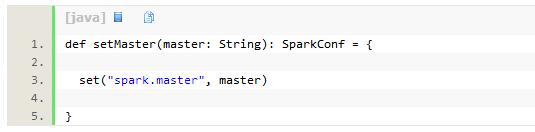
代码清单3-4 设置Spark的应用名称的配置方法setAppName

克隆SparkConf配置
有些情况下,同一个SparkConf实例中的配置信息需要被Spark中的多个组件共用,例如:组件A中存在一个SparkConf实例a,组件B中也很需要实例a中的配置信息,这时该如何处理?我们往往首先想到的方法是将SparkConf实例定义为全局变量或者通过参数传递给其它组件,但是这会引入并发问题。虽然settings是线程安全的ConcurrentHashMap类,而且ConcurrentHashMap也被证明是高并发下性能表现不错的数据结构,但是只要存在并发就一定会有性能的损失问题。我们可以新建一个SparkConf实例b,并将a中的配置信息全部拷贝到b中,这种方式显然不是最优雅的,复制代码会散落在程序的各个角落。现在是时候阅读下SparkConf的构造器了,代码如下所示:
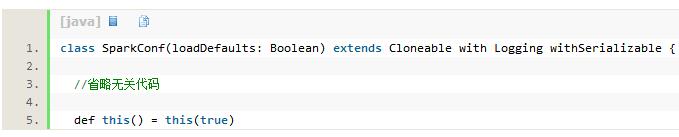
SparkConf继承了Cloneable特质并实现了clone方法,clone方法(见代码清单3-5)的实现跟我们所讨论的方式是一样的,并且通过Cloneable特质提高了代码的可复用性。
代码清单3-5 克隆SparkConf配置

这样我们就可以在任何想要使用SparkConf的地方使用克隆方式来优雅的编程了。
[1] Scala泛型的语法采用了方括号,而非Java中的尖括号。
[2] Utils是Spark中最常用的工具类,其每个方法实现的功能都比较单一,理解起来比较简单,所以本书只将相关的介绍放入附录A中单独进行介绍。如果不去阅读Utils中各个方法的实现,对阅读本书主干内容也不会有太多影响。如果是Spark的初学者或者是刚刚接触Scala语言的开发者还是建议阅读。

时间:2018-10-09 22:18 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]Spark 迁移到 K8S 在有赞的实践与经验
- [数据挖掘]盘点大数据处理引擎
- [数据挖掘]Spark Operator 初体验
- [数据挖掘]如何实现Spark on Kubernetes?
- [数据挖掘]Spark SQL 物化视图技术原理与实践
- [数据挖掘]Spark on K8S 的最佳实践和需要注意的坑
- [数据挖掘]Spark 3.0重磅发布!开发近两年,流、Python、SQL重
- [数据挖掘]Spark 3.0开发近两年终于发布,流、Python、SQL重大
- [数据挖掘]Apache Spark 3.0.0 正式版终于发布了,重要特性全面
- [数据挖掘]Spark 3.0 自适应查询优化介绍,在运行时加速 Sp
相关推荐:
网友评论:















