基于Hadoop的数据分析平台搭建
企业发展到一定规模都会搭建单独的BI平台来做数据分析,即OLAP(联机分析处理),一般都是基于数据库技术来构建,基本都是单机产品。除了业务数据的相关分析外,互联网企业还会对用户行为进行分析,进一步挖掘潜在价值,这时数据就会膨胀得很厉害,一天的数据量可能会成千万或上亿,对基于数据库的传统数据分析平台的数据存储和分析计算带来了很大挑战。
为了应对随着数据量的增长、数据处理性能的可扩展性,许多企业纷纷转向Hadoop平台来搭建数据分析平台。Hadoop平台具有分布式存储及并行计算的特性,因此可轻松扩展存储结点和计算结点,解决数据增长带来的性能瓶颈。
随着越来越多的企业开始使用Hadoop平台,也为Hadoop平台引入了许多的技术,如Hive、Spark SQL、Kafka等,丰富的组件使得用Hadoop构建数据分析平台代替传统数据分析平台成为可能。
一、数据分析平台架构原理
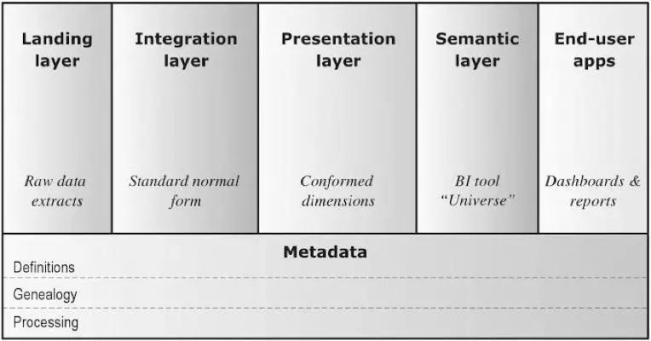
从概念上讲,我们可以把数据分析平台分为接入层(Landing)、整合层(Integration)、表现层(Persentation)、语义层(Semantic)、终端用户应用(End-user applications)、元数据(Metadata)。基于Hadoop和数据库的分析平台基本概念和逻辑架构是通用的,只是技术选型的不同:
• 接入层(Landing):以和源系统相同的结构暂存原始数据,有时被称为“贴源层”或ODS;
• 整合层(Integration):持久存储整合后的企业数据,针对企业信息实体和业务事件建模,代表组织的“唯一真相来源”,有时被称为“数据仓库”;
• 表现层(Presentation):为满足最终用户的需求提供可消费的数据,针对商业智能和查询性能建模,有时被称为“数据集市”;
• 语义层(Semantic):提供数据的呈现形式和访问控制,例如某种报表工具;
• 终端用户应用(End-user applications):使用语义层的工具,将表现层数据最终呈现给用户,包括仪表板、报表、图表等多种形式;
• 元数据(Metadata):记录各层数据项的定义(Definitions)、血缘(Genealogy)、处理过程(Processing)。
来自不同数据源的“生”数据(接入层),和经过中间处理之后得到的整合层、表现层的数据模型,都会存储在数据湖里备用。
数据湖的实现通常建立在Hadoop生态上,可能直接存储在HDFS上,也可能存储在HBase或Hive上,也有用关系型数据库作为数据湖存储的可能性存在。

下图说明了数据分析平台的数据处理流程:
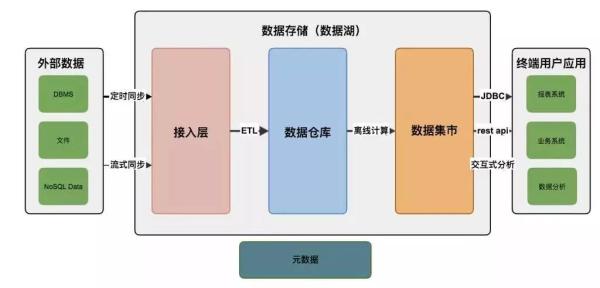
数据分析基本都是单独的系统,会将其他数据源的数据(即外部数据)同步到数据平台的存储体系来(即数据湖),一般数据先进入到接入层,这一层只简单的将外部数据同步到数据分析平台,没有做其他处理,这样同步出错后重试即可,有定时同步和流式同步两种:
• 定时同步即我们设定在指定时间触发同步动作;
• 流式同步即外部数据通过Kafka或MQ发送数据修改通知及内容。
• 数据分析平台执行对应操作修改数据。
接入层数据需要经过ETL处理步骤才会进入数据仓库,数据分析人员都是基于数据仓库的数据来做分析计算,数据仓库可以看作数据分析的唯一来源,ETL会将接入层的数据做数据清洗、转换,再加载到数据仓库,过滤或处理不合法、不完整的数据,并使用统一的维度来表示数据状态。有的系统会在这一层就将数据仓库构建成数据立方体、将维度信息构建成雪花或星型模式;也有的系统这一层只是统一了所有数据信息,没有做数据立方体,留在数据集市做。
数据集市是基于数据仓库数据对业务关心的信息做计算提取后得到的进一步信息,是业务人员直接面对的信息,是数据仓库的进一步计算和深入分析的结果,一般都会构建数据立方体。系统开发人员一般会开发页面来向用户展示数据集市的数据。
二、基于Hadoop构建数据分析平台
基于Hadoop构建的数据分析平台建构理论与数据处理流程与前面讲的相同。传统分析平台使用数据库套件构建,这里我们使用Hadoop平台的组件。
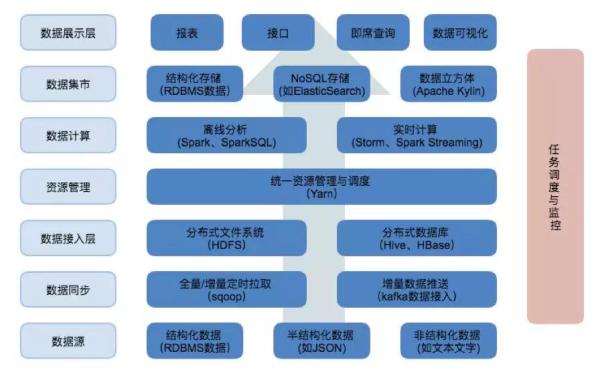
上面这张图是我们使用到的Hadoop平台的组件,数据从下到上流动,数据处理流程和上面说的一致。
任务调度负责将数据处理的流程串联起来,这里我选择使用的是Oozie,也有很多其它选择。
1、数据存储
基于Hadoop的数据湖主要用到了HDFS、Hive和HBase,HDFS是Hadoop平台的文件存储系统,我们直接操纵文件是比较复杂的,所以可以使用分布式数据库Hive或HBase用来做数据湖,存储接入层、数据仓库、数据集市的数据。
Hive和HBase各有优势:HBase是一个NoSQL数据库,随机查询性能和可扩展性都比较好;而Hive是一个基于HDFS的数据库,数据文件都以HDFS文件(夹)形式存放,存储了表的存储位置(即在HDFS中的位置)、存储格式等元数据,Hive支持SQL查询,可将查询解析成Map/Reduce执行,这对传统的数据分析平台开发人员更友好。
Hive数据格式可选择文本格式或二进制格式,文本格式有csv、json或自定义分隔,二进制格式有orc或parquet,他们都基于行列式存储,在查询时性能更好。同时可选择分区(partition),这样在查询时可通过条件过滤进一步减少数据量。接入层一般选择csv或json等文本格式,也不做分区,以尽量简化数据同步。数据仓库则选择orc或parquet,以提升数据离线计算性能。
数据集市这块可以选择将数据灌回传统数据库(RDBMS),也可以停留在数据分析平台,使用NoSQL提供数据查询或用Apache Kylin来构建数据立方体,提供SQL查询接口。
2、数据同步
我们通过数据同步功能使得数据到达接入层,使用到了Sqoop和Kafka。数据同步可以分为全量同步和增量同步,对于小表可以采用全量同步,对于大表全量同步是比较耗时的,一般都采用增量同步,将变动同步到数据平台执行,以达到两边数据一致的目的。
全量同步使用Sqoop来完成,增量同步如果考虑定时执行,也可以用Sqoop来完成。或者,也可以通过Kafka等MQ流式同步数据,前提是外部数据源会将变动发送到MQ。
3、ETL及离线计算
我们使用Yarn来统一管理和调度计算资源。相较Map/Reduce,Spark SQL及Spark RDD对开发人员更友好,基于内存计算效率也更高,所以我们使用Spark on Yarn作为分析平台的计算选型。
ETL可以通过Spark SQL或Hive SQL来完成,Hive在2.0以后支持存储过程,使用起来更方便。当然,出于性能考虑Saprk SQL还是不错的选择。

时间:2018-10-09 22:18 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















