Python数据预处理:使用Dask和Numba并行化加速
Python:60.9x | Dask:8.4x | Numba:5.8x |Numba+Dask:1x

作为旧金山大学的一名数据科学硕士,会经常跟数据打交道。使用Apply函数是我用来创建新特征或清理数据的众多技巧之一。现在,我只是一名数据科学家,而不是计算机科学方面的专家,但我是一个喜欢捣鼓并使得代码运行更快的程序员。现在,我将会分享我在并行应用上的经验。
大多Python爱好者可能了解Python实现的全局解释器锁(GIL),GIL会占用计算机中所有的CPU性能。更糟糕的是,我们主要的数据处理包,比如Pandas,很少能实现并行处理代码。
Apply函数vs Multiprocessing.map
Tidyverse已经为处理数据做了一些美好的事情,Plyr是我最喜爱的数据包之一,它允许R语言使用者轻松地并行化他们的数据应用。Hadley Wickham说过:
“plyr是一套处理一组问题的工具:需要把一个大的数据结构分解成一些均匀的数据块,之后对每一数据块应用一个函数,最后将所有结果组合在一起。”
对于Python而言,我希望有类似于plyr这样的数据包可供使用。然而,目前这样的数据包还不存在,但我可以使用并行数据包构成一个简单的解决方案。
Dask
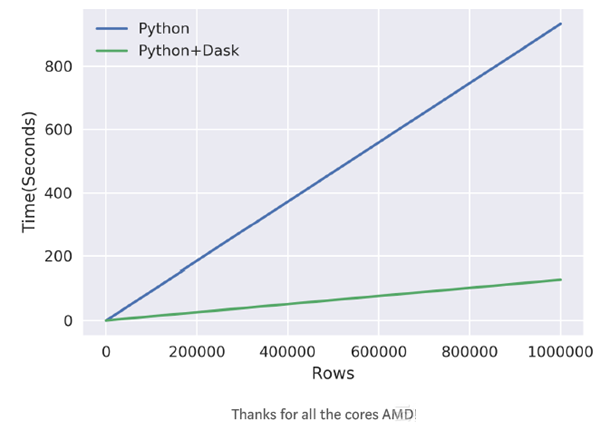
之前在Spark上花费了一些时间,因此当我开始使用Dask时,还是比较容易地掌握其重点内容。Dask被设计成能够在多核CPU上并行处理任务,此外也借鉴了许多Pandas的语法规则。
现在开始本文所举例子。对于最近的数据挑战而言,我试图获取一个外部数据源(包含许多地理编码点),并将其与要分析的一大堆街区相匹配。在计算欧几里得距离的同时,使用最大启发式将最大值分配给一个街区。
最初的apply:
Dask apply:
二者看起来很相似,apply核心语句是map_partitions,最后有一个compute()语句。此外,不得不对npartitions初始化。 分区的工作原理就是将Pandas数据帧划分成块,对于我的电脑而言,配置是6核-12线程,我只需告诉它使用的是12分区,Dask就会完成剩下的工作。
接下来,将map_partitions的lambda函数应用于每个分区。由于许多数据处理代码都是独立地运行,所以不必过多地担心这些操作的顺序问题。最后,compute()函数告诉Dask来处理剩余的事情,并把最终计算结果反馈给我。在这里,compute()调用Dask将apply适用于每个分区,并使其并行处理。
由于我通过迭代行来生成一个新队列(特征),而Dask apply只在列上起作用,因此我没有使用Dask apply,以下是Dask程序:
Numba、Numpy和Broadcasting
由于我是根据一些简单的线性运算(基本上是勾股定理)对数据进行分类,所以认为使用类似下面的Python代码会运行得更快一些。
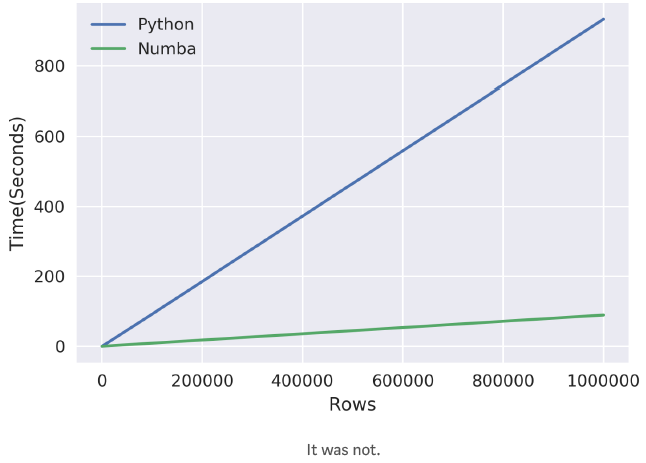
Broadcasting用以描述Numpy中对两个形状不同的矩阵进行数学计算的处理机制。假设我有一个数组,我会通过迭代并逐个变换每个单元格来改变它
相反,我完全可以跳过for循环,并对整个数组执行操作。Numpy与broadcasting混合使用,用来执行元素智能乘积(对位相乘)。
Broadcasting可以实现更多的功能,现在看看骨架代码:
从本质上讲,代码的功能是改变数组。好的一方面是运行很快,甚至能和Dask并行处理速度比较。其次,如果使用的是最基本的Numpy和Python,那么就可以及时编译任何函数。坏的一面在于它只适合Numpy和简单Python语法。我不得不把所有的数值计算从我的函数转换成子函数,但其计算速度会增加得非常快。
将其一起使用
简单地使用map_partition()就可以将Numba函数与Dask结合在一起,如果并行操作和broadcasting能够密切合作以加快运行速度,那么对于大数据集而言,将会看到其运行速度得到大幅提升。
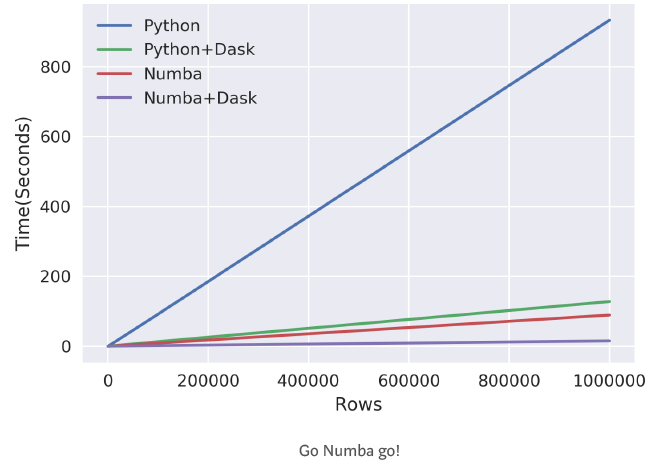
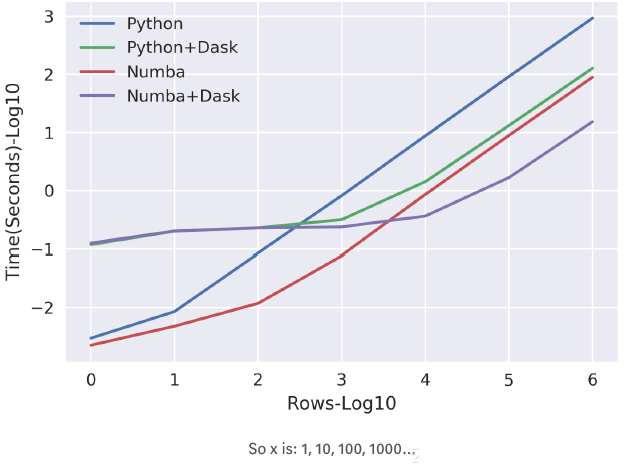
上面的第一张图表明,没有broadcasting的线性计算其表现不佳,并行处理和Dask对速度提升也有效果。此外,可以明显地发现,Dask和Numba组合的性能优于其它方法。
上面的第二张图稍微有些复杂,其横坐标是对行数取对数。从第二张图可以发现,对于1k到10k这样小的数据集,单独使用Numba的性能要比联合使用Numba+Dask的性能更好,尽管在大数据集上Numba+Dask的性能非常好。
优化
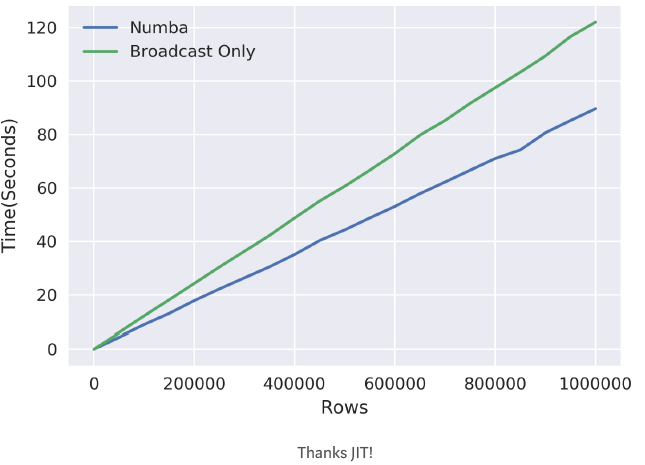
为了能够使用Numba编译JIT,我重写了函数以更好地利用broadcasting。之后,重新运行这些函数后发现,平均而言,对于相同的代码,JIT的执行速度大约快了24%。
作者信息:Ernest Kim,旧金山大学硕士生,专注于机器学习、数据科学。

时间:2018-10-09 22:18 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]底层I/O性能大PK:Python/Java被碾压,Rust有望取代
- [数据挖掘]RedMonk语言排行:Python力压Java,Ruby持续下滑
- [数据挖掘]不得了!Python 又爆出重大 Bug~
- [数据挖掘]TIOBE 1 月榜单:Python年度语言四连冠,C 语言再次
- [数据挖掘]TIOBE12月榜单:Java重回第二,Python有望四连冠年度
- [数据挖掘]这个可能打败Python的编程语言,正在征服科学界
- [数据挖掘]2021年编程语言趋势预测:Python和JavaScript仍火热,
- [数据挖掘]Spark 3.0重磅发布!开发近两年,流、Python、SQL重
- [数据挖掘]Python 为什么推荐蛇形命名法?
- [数据挖掘]Python才是世界上最好的语言
相关推荐:
网友评论:















