Flume + kafka + HDFS构建日志采集系统
1)Flume:作为agent部署在每个application server,指定需要收集的日志文件列表,日志文件通常为application通过logback等生成。(本文基于Flume 1.7.0)
2)kafka:基于Flume,将“准实时”数据发送给kafka;比如“tail”某个文件的实时数据。对于实时数据分析组件或者同类型的数据消费者,可以通过kafka获取实时数据。(kafka 0.9.0)
3)HDFS:基于Flume,将“历史数据”保存在HDFS,“历史数据”比如“每天rotate生成的日志文件”,我们熟悉的catalina.out文件,每天都rotate生成一个新的。当然对于“准实时”数据也可以保存在HDFS中,Flume支持将“tail”的数据每隔?小时生成一个HDFS文件等。通常情况下,我们将“历史数据”保存在HDFS,而不是“实时数据”。(hadoop 2.6.5)
4)对于历史数据,我们基于Flume的Spooling方式将数据转存在HDFS中;对于“准实时”数据,我们基于Flume的Tail方式将数据转存在kafka中。
一、HDFS准备
首先,我们需要一个hadoop平台,用于保存历史数据,我们所采集的数据通常为“日志数据”,搭建hadoop平台过程此处不再赘言。
我们规划的5台hadoop,2个namenode基于HA方式部署,3个datanode;其中namenode为4Core、8G、200G配置,datanode为8Core、16G、2T配置,blockSize为128M(日志文件大小普遍为2G左右,每个小时,大概在100M左右),replication个数为2。
二、Kafka准备
kafka的目的就是接收“准实时”数据,受限于kafka的本身特性,我们尽量不要让kafka存储太多的数据,即消息消费端尽可能的快(尽可能短的中断时间)。我们的集群为4个kafka实例,8Core、16G、2T配置,replication个数为2,数据持久时间为7天。kafka和hadoop都依赖于zookeeper集群,zk的集群是额外搭建的。
比较考验设计的事情,是如何设计Topic;当kafka集群上topic数量过多时,比如一个“tail”的文件分配一个topic,将会对kafka的性能带来巨大挑战,同时Topic太多会导致消息消费端编码复杂度较高;另一个方面,如果Topic过少,比如一个project中所有的“tail”的文件归属一个Topic,那么次topic中的数据来自多个文件,那么数据分拣的难度就会变大。
我个人的设计理念为:一个project中,每个“tail”的文件一个topic,无论这个project部署了多少实力,同一个“tail”文件归为一个topic;比如order-center项目中有一个业务日志pay.log,此project有20台实例,我们的topic名字为order-center-pay,那么这20个实例中的order.log会被收集到此topic中,不过为了便于数据分拣,order.log中每条日志都会携带各自的“local IP”。
kafka的配置样例(server.properties):
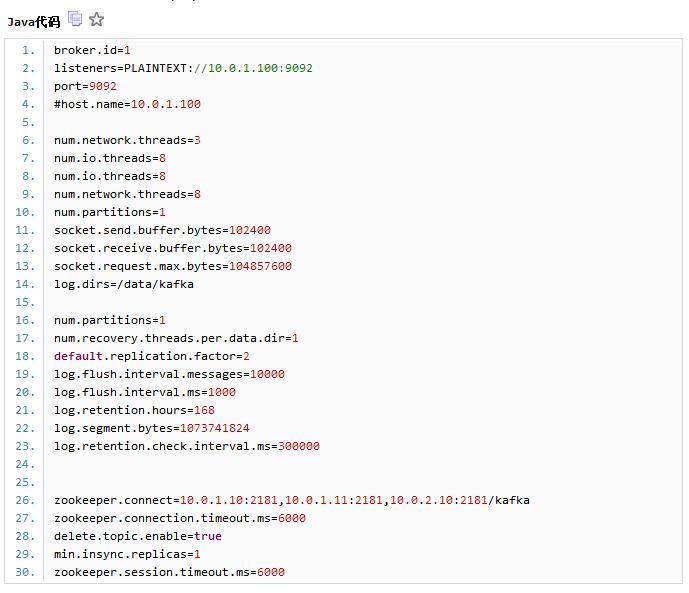
上述配置中,有2个地方需要特别注意:listeners和host.name,我们在listeners中指定kafka绑定的地址和端口,通常为本机的内网IP,将host.name设置为空,此处如果设置不当,会导致Flume无法找到kafka地址(address resolve失败);第二点就是zookeeper.connect地址,我们在地址后面增加了root path,此后Flume作为producer端发送消息时,指定的zookeeper地址也要带上此root path。此外,还有一些重要的参数,比如replicas、partitions等。
kafka不是本文的介绍重点,所以请你参考本人的其他博文获取更多的资讯。
三、Flume配置
根据我们的架构设计要求,实时数据发给kafka,历史数据发给HDFS;Flume完全可以满足我们这些要求,在Flume中,Spooling模式可以扫描一个文件目录下所有的文件,并将新增的文件发送给HDFS;同时其TAILDIR模式中,可以扫描一个(或者多个)文件,不断tail其最新追加的信息,然后发送给kafka。基本概念:
1、source:源文件、源数据端,指定Flume从何处采集数据(流)。Flume支持多种source,比如“Avro source”(类似RPC模式,接收远端Avro客户端发送的数据Entity)、“Thrift Source”(Thrift客户端发送的数据)、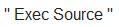 (linux指令返回的数据条目)、“Kafka Source”、“Syslog Source”、“Http Source”等等。
(linux指令返回的数据条目)、“Kafka Source”、“Syslog Source”、“Http Source”等等。
我们本文主要涉及到Spooling和Taildir两种,Taildir是1.7新增的特性,在此之前,如果想实现tail特性,需要使用“”来模拟,或者自己开发代码。
2、channel:通道,简单而言就是数据流的缓冲池,多个source的数据可以发送给一个channel,在channel内部可以对数据进行cache、溢出暂存、流量整形等。目前Flume支持“Memory Channel”(数据保存在有限空间的内存中)、“JDBC Channel”(数据暂存在数据库中,保障恢复)、“Kafka Channel”(暂存在kafka中)、“File Channel”(暂存在本地文件中);除Memory之外,其他的channel都支持持久化,可以在故障恢复、sink离线或者无sink等场景下提供有效的担保机制,避免消息丢失和流量抗击。
3、sink:流输出端,每个channel都可以对应一个sink,每个sink可以指定一种类型的存储方式,目前Flume支持的sink类型比较常用的有“HDFS Sink”(将数据保存在hdfs中)、“Hive Sink”、“Logger Sink”(特殊场景,将数据以INFO级别输出到控制台,通常用于测试)、“Avro Sink”、“Thrift Sink”、“File Roll Sink”(转存到本地文件系统中)等等。
本文不详细介绍Flume的特性,我们只需要简单知道一些概念即可,source、channel、sink这种模型就是pipeline,一个source的数据可以“复制”到多个channels(扇出),当然多个source也可以聚集到一个channel中,每个channel对应一个sink。每种类型的source、channel、sink都有各自的配置属性,用于更好的控制数据流。
Flume是java语言开发,所以我们在启动Flume之前,需要设定JVM的堆栈大小等选参,以免Flume对宿主机器上的其他application带来负面影响。在conf目录下,修改flume-env.sh:

本人限定Flume的JVM堆大小为1G,如果你的机器内存空闲较多或者收集的数据文件较多,可以考虑适度增大此值。
除此之外,就是flume的启动配置文件了(flume-conf.properties),如下配置我们模拟一个收集nginx日志的场景:

这是一个很长的配置文件,各个配置项的含义大家可以去官网查阅,我们需要注意几个地方:
1)checkpoint、data目录,最好指定,这对以后排查问题很有帮助
2)channel,我们需要显示声明其类型,通常我们使用file,对流量抗击有些帮助,前提是指定的目录所在磁盘空间应该相对充裕和高速。
3)header并不会真的会写入sink,header信息只是在source、channel、sink交互期间有效;我们可以通过header标记一个event流动的特性。
4)对于spooling source,建议开启basename,即文件的实际名称,我们可以将此header传递到sink阶段。
5)所有涉及到batchSize的特性,都是需要权衡的:在发送效率和延迟中做出合理的决策。
6)interceptor是Flume很重要的特性,可以帮助我们在source生命周期之后做一些自定义的操作,比如增加header、内容修正等;此时我们需要关注一些性能问题。
7)对于taildir,filegroups中可以指定多个值,我的设计原则是一个tail文件对应一个group名称,目前还没有特别好的办法来通配tail文件,只能逐个声明。
8)对于kafka sink,topic信息可以通过“kafka.topic”指定,也可以在通过header指定(headers.www.topic,“www”对应group名称,“topic”是header的key名称)。为了灵活性,我更倾向于在headers中指定topic。
9)hdfs sink需要注意其roll的时机,目前影响roll时机的几个参数“minBlockReplicas”、“rollInterval”(根据时间间隔)、“rollSize”(根据文件尺寸)、“rollCount”(根据event条数);此外“round”相关的选项也可以干预滚动生成新文件的时机。
关于hdfs sink折磨了我很久,flume每次flush都将生成一个新的hdfs文件,最终导致生成很多小文件,我希望一个tail的文件最终在hdfs中也是一个文件;后来经过考虑,使用基于rollSize来滚动生成文件,通常本人的nginx日志文件不超过1G,那么我就让rollSize设置为1G,这样就可以确保不会roll。此外,hdfs每个文件都会有一个“数字”后缀,这个数字是一个内部的counter,目前没有办法通过配置的方式来“消除”,我们先暂且接受吧。
如下为nginx中log_format样例,我们在每条日志的首个位置,设置了$hostname用于标记此文件的来源机器,便于kafka消息消费者分拣数据。

对于flume的配置,我们可以通过zookeeper来保存,这是1.7版本新增的特性,配置中心化,这种方式大家可以参考。不过本人考虑到配置的可见性,我并没有将配置放在zookeeper中,而是放在了一台配置中控机上,通过jenkins来部署flume,每个project分布式部署,每个节点一个flume实例,它们使用同一个配置文件,在部署flume时从中控机上scp新配置即可。(这需要先有一个自动化部署平台)
我们看到配置文件中的配置项都以“nginx”开头,这个前缀表示agent的名称,我们可以根据实际业务来命名即可,但是在启动flume时必须制定,原则上一个flume-conf.properties文件中可以声明多个agent的配置项,不过我们通常不建议这么用。
我们把flume部署在nginx所在机器上,调整好配置文件,即可启动,flume启动脚本:

上述启动指令中,--config-file就是指定配置文件的路径和名称,--name指定agent名称(与配置文件中的配置项前缀保持一致),logger信息我们在线上为INFO,在测试期间可以指定为“DEBUG,LOGFILE”便于我们排查问题。
四、tomcat业务日志收集
关于Flume收集tomcat业务日志,需要调整的点比较多;本人的设计初衷是:
1)HDFS中收集所有的历史日志,包括catalina、access_log、业务日志等。
2)kafka只实时收集access_log和指定的业务日志;我们可以用这些数据做业务监控等。
1、tomcat日志格式
我们首先调整tomcat中的logging.properties:
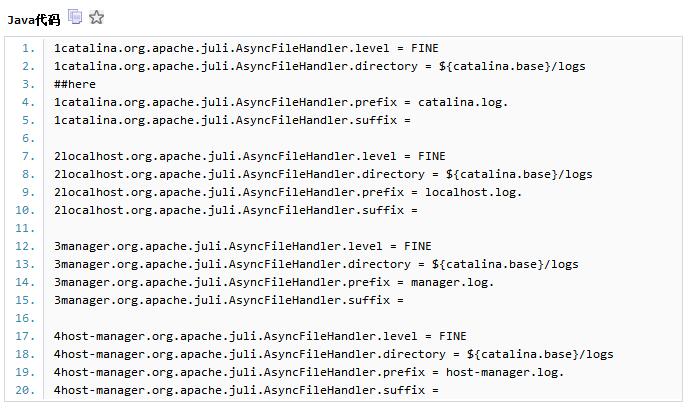
因为tomcat日志文件滚动格式默认为“catalina.
Flume的配置文件与nginx基本类似,此处不再赘言。
2、业务日志
我们约定application的业务日志也打印在${tomcat_home}/logs目录下,即与catalina.out在一个目录,每个业务日志每天滚动生成新的历史文件,文件后缀以“.yyyy-MM-dd”结尾,这类文件称为历史文件,被同步到HDFS中。对于实时的日志信息,我们仍然发送给kafka,kafka topic的设计思路跟nginx一样,每个project一种文件对应一个topic,每种文件的日志来自多个application实例,它们混淆在kafka topic中,为了便于日志分拣,我们需要在每条日志中增加一个IP标志项。本人整理发现,在logback中打印local ip默认是不支持的,所以我们需要变通一下,我们在tomcat的启动脚本中定义一个LOCAL_IP这个环境变量,然后再logback.xml中引入即可解决。

在项目中的logback.xml中即可通过${LOCAL_IP}变量声明即可
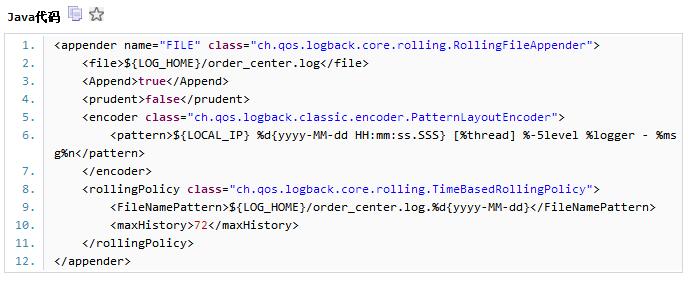
3、access_log日志
tomcat的access_log非常重要,可以打印很多信息来帮助我们分析业务问题,所以我们需要将acess_log日志整理规范;我们在server.xml中通过修改如下内容即可:

“renameOnRotate”表示是否在rotate时机重命名access_log,我们设定为true,这样access_log文件名默认不带日期格式,时间格式在rotate期间才添加进去。“%A”表示本机的local ip地址,也是用于kakfa分拣日志的标记,X-Request-ID是nginx层自定义的一个trace-ID用于跟踪请求的,如果你没有设定,则可以去掉。
到此为止,我们基本上可以完成这一套日志采集系统了,也为kafka分拣日志信息做好了铺垫,后续接入ELK、storm实时数据分析等也将相对比较容易。
五、问题总结:
1、flume + hdfs:
1)我们首先将hdfs-site.xml,core-site.xml复制到${flume_home}/conf目录下。且flume机器能够与hdfs所有节点通信(网络隔离、防火墙都可能导致它们无法正常通信)。
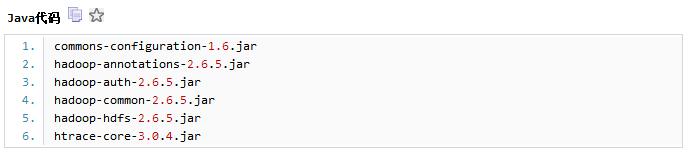
2)在Flume根目录下,创建一个plugins.d/hadoop目录,创建lib、libext、native子目录;并将hadoop的相关依赖包复制到libext目录中:
同时将如下文件复制到native目录中:
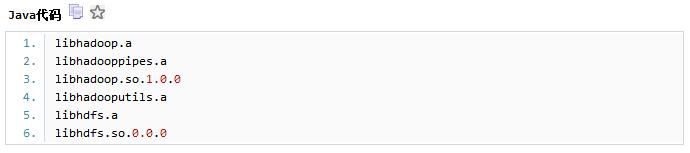
这些依赖包,都可以在hadoop的部署包中找到。
2、启动异常:
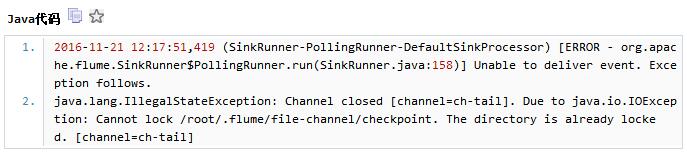
错误描述为:文件已经被lock,无法继续加锁。解决办法:如果一个flume中有多个channel为file类型,它们应该使用不同的数据目录,通过修改默认配置即可。
3、hdfs sink:
hdfs.fileSuffix的值不支持参数化,本人希望在fileSuffix中使用header,比如hdfs.fileSuffix=%{filename},后来多次尝试发现Flume暂时不支持。
4、在Spooling模式中,已经收集的日志文件,将会被重名为“.COMPLATED”后缀,如果人为的再次创建同名的文件,此时Flume将会报错且停止采集数据。
5、运行时异常:

出现这种错误的问题,就是flume无法与kafka集群建立连接,无法获取meta信息导致的;通常情况下,你需要修改kafka中的server.properties文件,调整“listeners”、“host.name”配置项即可;其中“listeners”中明确指定绑定到本机的内网IP,"host.name"保持默认或者不声明。

时间:2018-10-09 22:18 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]流数据并行处理性能比较:Kafka vs Pulsar vs Praveg
- [数据挖掘]实时数据仓库必备技术:Kafka 知识梳理
- [数据挖掘]Twitter 把 Kafka 当作存储系统使用
- [数据挖掘]盘点大数据处理引擎
- [数据挖掘]HBase数据迁移到Kafka?这种逆向操作你懵逼了吗?
- [数据挖掘]因为一次 Kafka 宕机,我明白了 Kafka 高可用原理!
- [数据挖掘]Kafka面试知识点深度剖析
- [数据挖掘]图文了解 Kafka 的副本复制机制
- [数据挖掘]Kafka 集群在马蜂窝大数据平台的优化与应用扩展
- [数据挖掘]Kafka加Flink不是终点!下一代大数据平台Pravega
相关推荐:
网友评论:















