如何用Python编写你最喜欢的R函数?
本文介绍了采用创建一个Python脚本,用该脚本模仿R风格的函数的方法来方便地进行统计。
是用R语言还是用Python语言?这是一个旷日持久的争论。在此,我们可以尝试采用折中路线:创建一个Python脚本,用该脚本模仿R风格的函数,来方便地进行统计!

简介
用R语言还是用Python语言?这是数据科学和机器学习的一场大的争论。毫无疑问,这两种语言在最近几年都取得了巨大的进展,成为数据科学、预测分析和机器学习的首选编程语言。事实上,在IEEE新近的一篇文章中,Python取代C++成为2018年的顶级编程语言,R已经牢牢地保住了它在前10名中的位置。
然而,这两种编程语言之间存在着一些本质的差异。R主要是为数据分析问题的统计分析和快速原型化而开发的工具。另一方面,Python作为一种通用的现代面向对象语言,与C或Java相似,它具有更简单的学习曲线和更为灵活的行为方式。因此,R在统计学家、定量生物学家、物理学家和经济学家中仍然非常受欢迎,而Python逐渐成为日常脚本、自动化、后端web开发、分析和通用机器学习框架的首选语言,Python语言的技术支持基础比较广泛,同时还有许多开源社区。
如何在Python环境中模仿函数式编程?
R语言的函数编程特性为用户提供了非常简单有效地界面,用于快速计算概率,并为数据分析问题提供必要的描述性/推理统计。例如,仅仅使用一个紧致函数调用就能回答下面的问题,这是不是很神奇?
♦ 如何计算数据向量的平均/中值/模型?
♦ 如何计算服从正态分布的某一事件的累积概率?如果该分布是泊松分布,则如何计算?
♦ 如何计算一系列数据点的四分位数间距?
♦ 如何根据学生的t分布生成少量随机数?
♦ 在R语言编程环境中,这些您都能实现。
另一方面,Python脚本编写能使分析人员在各种分析管线中创造性地使用这些统计数据。
为了结合这两种语言的优势,需要设计一个简单的基于Python的包装类库,它包含最常用的函数,这些函数涉及以R风格定义的概率分布和描述性统计信息,用户可以快速地调用这些函数,而无需调用Python统计库,并弄明白所有方法和参数。
最为便捷的R-函数的Python包装类脚本
我用Python编写了一个脚本,用来定义在简单统计分析中最为便捷和最被广泛使用的R函数。导入这个脚本之后,您将能够像在R编程环境中一样自然地使用那些R-函数。
这个脚本的目标是利用简单的Python子程序,来模仿R风格的统计函数,从而快速计算密度/点估计、累积分布、分位数,并为各种重要的概率分布生成随机变量。为了保持R的风格,没有使用类分层结构,只在该文件中定义了一些原始函数,这样用户便可以方便地导入这个Python脚本,并在需要时使用所有函数,而仅仅只需做一个名称的调用。
注意,在此使用了“模仿”这个词。我并没有声称要模仿R真正的功能编程范式:那些由深层次的环境设置和这些环境与对象之间组成的复杂的相互关系。这个脚本只允许我(同时也希望有无数其他Python用户)能够快速启动Python程序或Jupyter笔记本(一种交互式笔记本,支持运行 40 多种编程语言)导入脚本,并在短时间内开始进行简单的描述性统计。这就是目标,仅此而已。
或者,你可能已经会用R语言编码,刚开始学习和使用Python进行数据分析。你可以高兴地看到和使用Jupyter笔记本里的一些众所周知的函数,这些都和你使用的R语言环境中的方法类似。
简单实例
例如,如果需要计算数据点向量的TuKEY五数综合。你只需调用一个简单函数FiVunm并传递给向量,它便在一个Numpy数组中返回五数综合(最小值;第1四分位数(Q1);中位数(Q2);第3四分位数(Q3);最大值。)。

或者,你想知道以下问题的答案:
假设一台机器平均每小时输出10件成品,标准差为2,输出模式服从近似正态分布。在接下来的一小时内,机器输出至少7台但不超过12台的概率是多少?
答案基本上是这样,
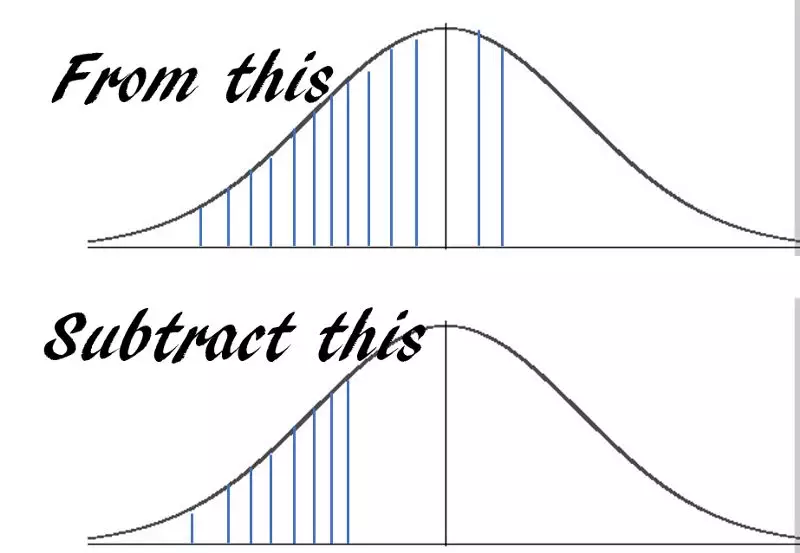
利用pNorm…,只需要一行代码就可以得到答案。
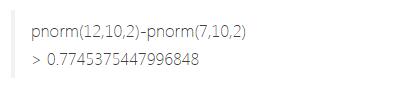
或者,对于如下问题:
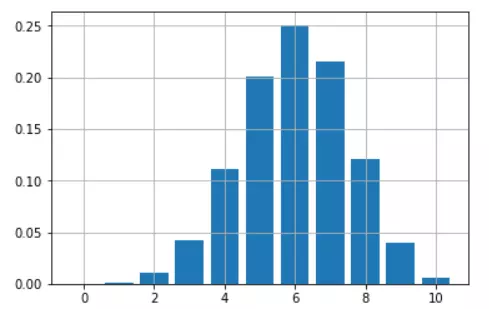
假设你有一枚硬币,每次抛硬币的时候,都有60%的转动概率,玩的是10次抛掷的游戏。如何用这枚硬币计算出所有可能的赢球数(从0到10)?
只需使用一个dbinom…函数和几行代码就可以获得一个很好的条形图。

目前已经实现的函数
目前,已经实现了的、可以用于快速调用的R风格函数在以下脚本中实现。
♦ 均值、中值、方差、标准差
♦ TuKEY五数综合、矩阵的IQR
♦ 矩阵的协方差或两个向量之间的协方差
密度、累积概率、分位函数和随机变量生成,用于下列分布:正态分布,均匀分布,二项分布,泊松分布,F分布,Student’s-t分布,卡方分布,Beta分布,和Gamma分布
后续工作
这项工作还正在进行之中,我计划在脚本中添加一些更为便捷的R-函数。例如,在R单行命令中,lm可以得到一个最小二乘拟合模型,该模型具有所有必要的推断统计量(P值、标准误差等)。这将是多么的简短和紧凑!另一方面,Python中的标准线性回归问题通常是使用Scikit-Learning来解决,需要用到更多的脚本来实现它。我计划使用Python的statsmodel后端结合这个单一函数线性模型来实现。

时间:2018-09-26 13:28 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]底层I/O性能大PK:Python/Java被碾压,Rust有望取代
- [数据挖掘]RedMonk语言排行:Python力压Java,Ruby持续下滑
- [数据挖掘]不得了!Python 又爆出重大 Bug~
- [数据挖掘]TIOBE 1 月榜单:Python年度语言四连冠,C 语言再次
- [数据挖掘]TIOBE12月榜单:Java重回第二,Python有望四连冠年度
- [数据挖掘]这个可能打败Python的编程语言,正在征服科学界
- [数据挖掘]2021年编程语言趋势预测:Python和JavaScript仍火热,
- [数据挖掘]Spark 3.0重磅发布!开发近两年,流、Python、SQL重
- [数据挖掘]Python 为什么推荐蛇形命名法?
- [数据挖掘]Python才是世界上最好的语言
相关推荐:
网友评论:















