数据挖掘领域十大经典算法之—朴素贝叶斯算法
简介
NaïveBayes算法,又叫朴素贝叶斯算法,朴素:特征条件独立;贝叶斯:基于贝叶斯定理。属于监督学习的生成模型,实现简单,没有迭代,并有坚实的数学理论(即贝叶斯定理)作为支撑。在大量样本下会有较好的表现,不适用于输入向量的特征条件有关联的场景。
基本思想
(1)病人分类的例子
某个医院早上收了六个门诊病人,如下表:

现在又来了第七个病人,是一个打喷嚏的建筑工人。请问他患上感冒的概率有多大?
根据贝叶斯定理:

因此,这个打喷嚏的建筑工人,有66%的概率是得了感冒。同理,可以计算这个病人患上过敏或脑震荡的概率。比较这几个概率,就可以知道他最可能得什么病。
这就是贝叶斯分类器的基本方法:在统计资料的基础上,依据某些特征,计算各个类别的概率,从而实现分类。
(2)朴素贝叶斯分类器的公式
假设某个体有n项特征(Feature),分别为F1、F2、…、Fn。现有m个类别(Category),分别为C1、C2、…、Cm。贝叶斯分类器就是计算出概率最大的那个分类,也就是求下面这个算式的最大值:
由于 P(F1F2…Fn) 对于所有的类别都是相同的,可以省略,问题就变成了求
的最大值。
朴素贝叶斯分类器则是更进一步,假设所有特征都彼此独立,因此
上式等号右边的每一项,都可以从统计资料中得到,由此就可以计算出每个类别对应的概率,从而找出最大概率的那个类。
虽然”所有特征彼此独立”这个假设,在现实中不太可能成立,但是它可以大大简化计算,而且有研究表明对分类结果的准确性影响不大。
(3)拉普拉斯平滑(Laplace smoothing)
也就是参数为1时的贝叶斯估计,当某个分量在总样本某个分类中(观察样本库/训练集)从没出现过,会导致整个实例的计算结果为0。为了解决这个问题,使用拉普拉斯平滑/加1平滑进行处理。
它的思想非常简单,就是对先验概率的分子(划分的计数)加1,分母加上类别数;对条件概率分子加1,分母加上对应特征的可能取值数量。这样在解决零概率问题的同时,也保证了概率和依然为1。
eg:假设在文本分类中,有3个类,C1、C2、C3,在指定的训练样本中,某个词语F1,在各个类中观测计数分别为=0,990,10,即概率为P(F1/C1)=0,P(F1/C2)=0.99,P(F1/C3)=0.01,对这三个量使用拉普拉斯平滑的计算方法如下:
1/1003 = 0.001,991/1003=0.988,11/1003=0.011
实际应用场景
• 文本分类
• 垃圾邮件过滤
• 病人分类
• 拼写检查
朴素贝叶斯模型
朴素贝叶斯常用的三个模型有:
• 高斯模型:处理特征是连续型变量的情况
• 多项式模型:最常见,要求特征是离散数据
• 伯努利模型:要求特征是离散的,且为布尔类型,即true和false,或者1和0
代码实现
基于多项式模型的朴素贝叶斯算法(在github获取)

测试数据集为MNIST数据集,获取地址train.csv
运行结果
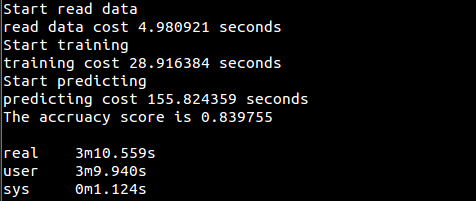

时间:2018-09-21 00:26 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















