数据挖掘领域十大经典算法之—SVM算法
简介
SVM(Support Vector Machine)中文名为支持向量机,是常见的一种判别方法。在机器学习领域,是一个有监督的学习模型,通常用来进行模式识别、分类以及回归分析。
相关概念
• 分类器:分类器就是给定一个样本的数据,判定这个样本属于哪个类别的算法。例如在股票涨跌预测中,我们认为前一天的交易量和收盘价对于第二天的涨跌是有影响的,那么分类器就是通过样本的交易量和收盘价预测第二天的涨跌情况的算法。
• 特征:在分类问题中,输入到分类器中的数据叫做特征。以上面的股票涨跌预测问题为例,特征就是前一天的交易量和收盘价。
• 线性分类器:线性分类器是分类器中的一种,就是判定分类结果的根据是通过特征的线性组合得到的,不能通过特征的非线性运算结果作为判定根据。还以上面的股票涨跌预测问题为例,判断的依据只能是前一天的交易量和收盘价的线性组合,不能将交易量和收盘价进行开方,平方等运算。
线性分类器起源
在实际应用中,我们往往遇到这样的问题:给定一些数据点,它们分别属于两个不同的类,现在要找到一个线性分类器把这些数据分成两类。
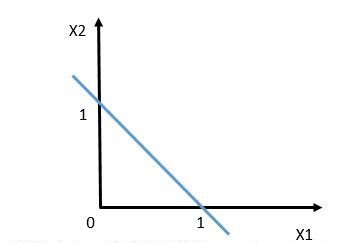
怎么分呢?把整个空间劈成两半呗(让我想到了盘古)。用二维空间举个例子,如上图所示,我们用一条直线把空间切割开来,直线左边的点属于类别-1(用三角表示),直线右边的点属于类别1(用方块表示)。
如果用数学语言呢,就是这样的:空间是由X1和X2组成的二维空间,直线的方程是X1+X2 = 1,用向量符号表示即为[1,1]^{T}[X1,X2]-1=0 。点x在直线左边的意思是指,当把x放入方程左边,计算结果小于0。同理,在右边就是把x放入方程左边,计算出的结果大于0。都是高中数学知识。
在二维空间中,用一条直线就把空间分割开了:
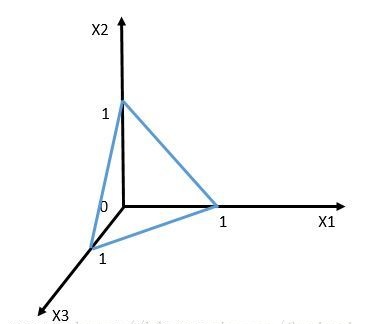
在三维空间中呢,需要用一个平面把空间切成两半,对应的方程是X1+X2+X3=1,也就是[1,1,1]^{T}[X1,X2,X3]-1=0 。
在高维(n>3)空间呢?就需要用到n-1维的超平面将空间切割开了。那么抽象的归纳下:
如果用x表示数据点,用y表示类别(y取1或者-1,代表两个不同的类),一个线性分类器的学习目标便是要在n维的数据空间中找到一个超平面(hyper plane),把空间切割开,这个超平面的方程可以表示为(W^{T}中的T代表转置):
W^{T}X+b=0
感知器模型和逻辑回归:
• 常见的线性分类器有感知器模型和逻辑回归。上一节举出的例子是感知器模型,直接给你分好类。有时候,我们除了要知道分类器对于新数据的分类结果,还希望知道分类器对于这次分类的成功概率。逻辑回归就可以做这件事情。
• 逻辑回归(虽然称作回归,但是不是一个回归方法,却是一个分类算法。很蛋疼的说)将线性分类器的超平面方程计算结果通过logistic函数从正负无穷映射到0到1。这样,映射的结果就可以认为是分类器将x判定为类别1的概率,从而指导后面的学习过程。
举个例子,看天气预报,用感知器的天气预报只会告诉你明天要下雨(y=1),或者明天不下雨(y=-1);而用了逻辑回归的天气预报就能告诉你明天有90%的概率要下雨,10%的概率不下雨。
逻辑回归的公式是g(z)=\frac{1}{1+e^{-z}} ,图像大概长这个样子:
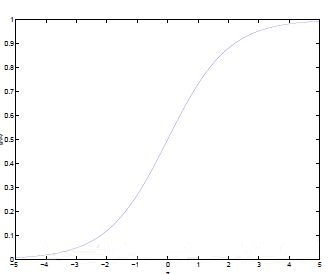
怎么用呢?比如感知器模型中,将特征代入判别方程中,如果得到的值是-3,我们可以判定类别是-1(因为-3<0)。而逻辑回归中呢,将-3代入g(z),我们就知道,该数据属于类别1的概率是0.05(近似数值,谢谢),那么属于类别-1的概率就是1 – 0.05 = 0.95。也就是用概率的观点描述这个事情。
支持向量机 VS 感知器和逻辑回归
根据上面的讨论,我们知道了在多维空间下,用一个超平面就把数据分为了两类。这个超平面我们叫它为分离超平面。但是这个分离超平面可以有很多个,那么用哪个呢?
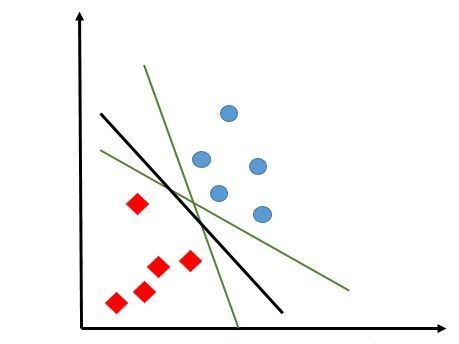
上图中,对于目前的训练数据,绿色和黑色的直线(二维特征空间,分离超平面就是直线啦)都可以很可以很好的进行分类。但是,通过已知数据建立分离超平面的目的,是为了对于未知数据进行分类的。在下图中,蓝色的星星图案就是新加入的真实数据。
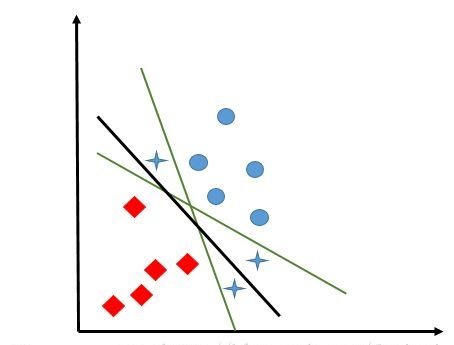
这时候我们就可以看出不同的分离超平面的选择对于分类效果的影响了。有的绿线会将三个点都划归蓝色圆圈,有的绿线会将三个点都划归红色正方形。
那么绿线和黑线留下谁?我们认为,已有的训练数据中,每个元素距离分离超平面都有一个距离。在添加超平面的时候,尽可能的使最靠近分离超平面的那个元素与超平面的距离变大。这样,加入新的数据的时候,分的准的概率会最大化。感知器模型和逻辑回归都不能很好的完成这个工作,该我们的支持向量机(support vector machine,SVM)出场了。
首先,SVM将函数间隔(\left| W^{T}X+b \right| ,将特征值代入分离超平面的方程中,得到的绝对值)归一化,归一化的目的是除掉取值尺度的影响;其次,对所有元素求到超平面的距离,(这个距离是\frac{\left| W^{T}X+b \right| }{\left| W \right| } ,也就是几何间隔)。给定一个超平面P,所有样本距离超平面P的距离可以记为d_{ij}=\frac{\left| W^{T}X+b \right| }{\left| W \right| } ,这其中最小的距离记为D_{P},SVM的作用就是找到D_{P}最大的超平面。
可以看出,大部分数据对于分离超平面都没有作用,能决定分离超平面的,只是已知的训练数据中很小的一部分。这与逻辑回归有非常大的区别。上图中,决定黑色的这条最优分离超平面的数据只有下方的两个红色的数据点和上方的一个蓝色的数据点。这些对于分离超平面有着非常强大影响的数据点也被称为支持向量(看没看到,这就是传说中的支持向量啦,原来如此)。
引入黑科技-核函数
上面说的都是在原始特征的维度上,能直接找到一条分离超平面将数据完美的分成两类的情况。但如果找不到呢?
比如,原始的输入向量是一维的,0< x <1的类别是1,其他情况记做-1。这样的情况是不可能在1维空间中找到分离超平面的(一维空间中的分离超平面是一个点,aX+b=0)。你用一个点切一下试试?
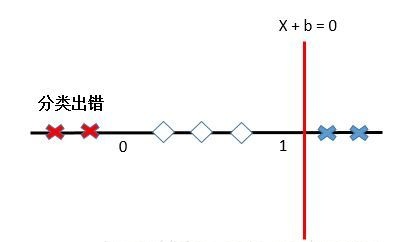
这就要说到SVM的黑科技—核函数技巧。核函数可以将原始特征映射到另一个高维特征空间中,解决原始空间的线性不可分问题。
继续刚才那个数轴。

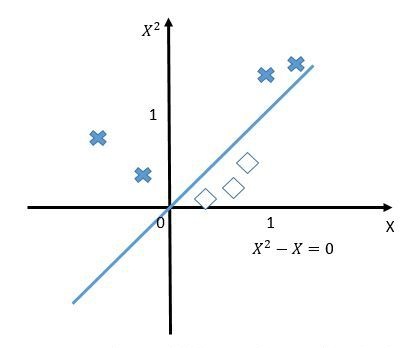
如果我们将原始的一维特征空间映射到二维特征空间X^{2}和x,那么就可以找到分离超平面X^{2}-X=0。当X^{2}-X<0的时候,就可以判别为类别1,当X^{2}-X>0 的时候,就可以判别为类别0。如下图:
再将X^2-X=0映射回原始的特征空间,就可以知道在0和1之间的实例类别是1,剩下空间上(小于0和大于1)的实例类别都是0啦。
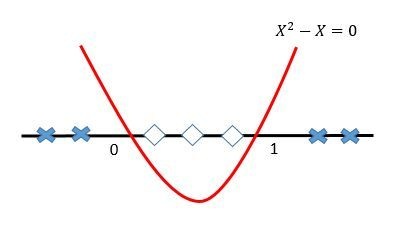
利用特征映射,就可以将低维空间中的线性不可分问题解决了。是不是很神奇,这就是特征映射的牛逼之处了。核函数除了能够完成特征映射,而且还能把特征映射之后的内积结果直接返回,大幅度降低了简化了工作,这就是为啥采用核函数的原因。
SVM三种模型
SVM有三种模型,由简至繁为
• 当训练数据训练可分时,通过硬间隔最大化,可学习到硬间隔支持向量机,又叫线性可分支持向量机
• 当训练数据训练近似可分时,通过软间隔最大化,可学习到软间隔支持向量机,又叫线性支持向量机
• 当训练数据训练不可分时,通过软间隔最大化及核技巧(kernel trick),可学习到非线性支持向量机
代码
代码已在github上实现,这里也贴出来

测试数据集为经过二分类处理后的MNIST数据集,获取地址train_binary.csv
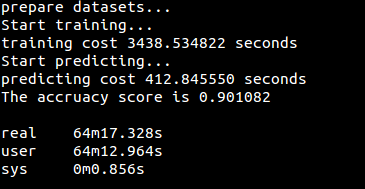
运行结果

时间:2018-09-21 00:24 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















