一文读懂PySpark数据框(附实例)
本文中我们将探讨数据框的概念,以及它们如何与PySpark一起帮助数据分析员来解读大数据集。
数据框是现代行业的流行词。人们往往会在一些流行的数据分析语言中用到它,如Python、Scala、以及R。 那么,为什么每个人都经常用到它呢?让我们通过PySpark数据框教程来看看原因。在本文中,我将讨论以下话题:
• 什么是数据框?
• 为什么我们需要数据框?
• 数据框的特点
• PySpark数据框的数据源
• 创建数据框
• PySpark数据框实例:国际足联世界杯、超级英雄
什么是数据框?
数据框广义上是一种数据结构,本质上是一种表格。它是多行结构,每一行又包含了多个观察项。同一行可以包含多种类型的数据格式(异质性),而同一列只能是同种类型的数据(同质性)。数据框通常除了数据本身还包含定义数据的元数据;比如,列和行的名字。

我们可以说数据框不是别的,就只是一种类似于SQL表或电子表格的二维数据结构。接下来让我们继续理解到底为什么需要PySpark数据框。
为什么我们需要数据框?
1. 处理结构化和半结构化数据

数据框被设计出来就是用来处理大批量的结构化或半结构化的数据。各观察项在Spark数据框中被安排在各命名列下,这样的设计帮助Apache Spark了解数据框的结构,同时也帮助Spark优化数据框的查询算法。它还可以处理PB量级的数据。
2. 大卸八块

数据框的应用编程接口(API)支持对数据“大卸八块”的方法,包括通过名字或位置“查询”行、列和单元格,过滤行,等等。统计数据通常都是很凌乱复杂同时又有很多缺失或错误的值和超出常规范围的数据。因此数据框的一个极其重要的特点就是直观地管理缺失数据。
3. 数据源

数据框支持各种各样地数据格式和数据源,这一点我们将在PySpark数据框教程的后继内容中做深入的研究。它们可以从不同类的数据源中导入数据。
4. 多语言支持

它为不同的程序语言提供了API支持,如Python、R、Scala、Java,如此一来,它将很容易地被不同编程背景的人们使用。
数据框的特点
数据框实际上是分布式的,这使得它成为一种具有容错能力和高可用性的数据结构。
惰性求值是一种计算策略,只有在使用值的时候才对表达式进行计算,避免了重复计算。Spark的惰性求值意味着其执行只能被某种行为被触发。在Spark中,惰性求值在数据转换发生时。
数据框实际上是不可变的。由于不可变,意味着它作为对象一旦被创建其状态就不能被改变。但是我们可以应用某些转换方法来转换它的值,如对RDD(Resilient Distributed Dataset)的转换。
数据框的数据源
在PySpark中有多种方法可以创建数据框:
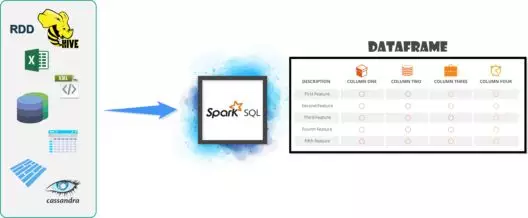
可以从任一CSV、JSON、XML,或Parquet文件中加载数据。还可以通过已有的RDD或任何其它数据库创建数据,如Hive或Cassandra。它还可以从HDFS或本地文件系统中加载数据。
创建数据框
让我们继续这个PySpark数据框教程去了解怎样创建数据框。
我们将创建 Employee 和 Department 实例:
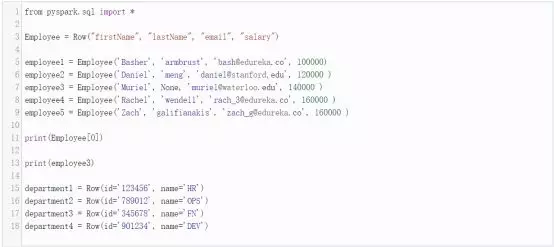
接下来,让我们通过Employee和Departments创建一个DepartmentWithEmployees实例。

让我们用这些行来创建数据框对象:

PySpark数据框实例1:国际足联世界杯数据集
这里我们采用了国际足联世界杯参赛者的数据集。我们将会以CSV文件格式加载这个数据源到一个数据框对象中,然后我们将学习可以使用在这个数据框上的不同的数据转换方法。

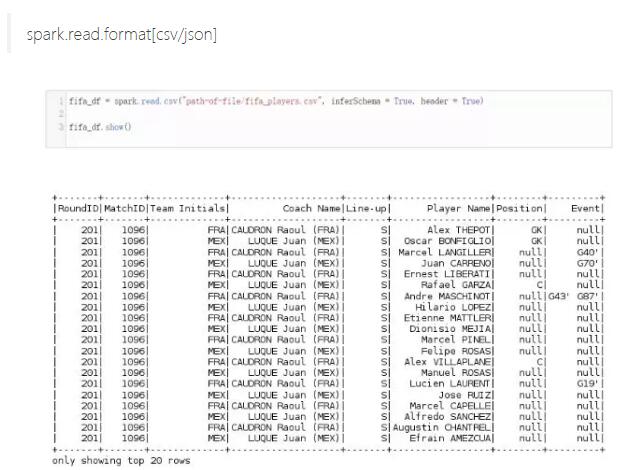
1. 从CSV文件中读取数据
让我们从一个CSV文件中加载数据。这里我们会用到spark.read.csv方法来将数据加载到一个DataFrame对象(fifa_df)中。代码如下:
2. 数据框结构
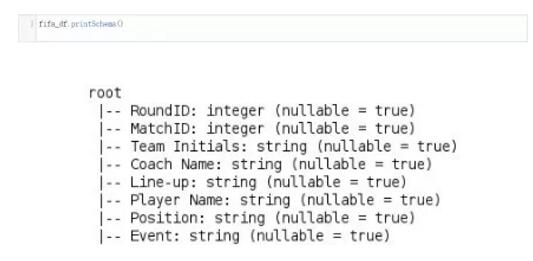
来看一下结构,亦即这个数据框对象的数据结构,我们将用到printSchema方法。这个方法将返回给我们这个数据框对象中的不同的列信息,包括每列的数据类型和其可为空值的限制条件。
3. 列名和个数(行和列)
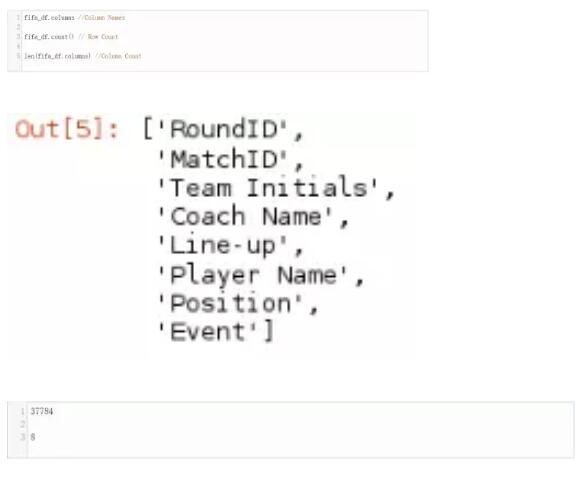
当我们想看一下这个数据框对象的各列名、行数或列数时,我们用以下方法:
4. 描述指定列
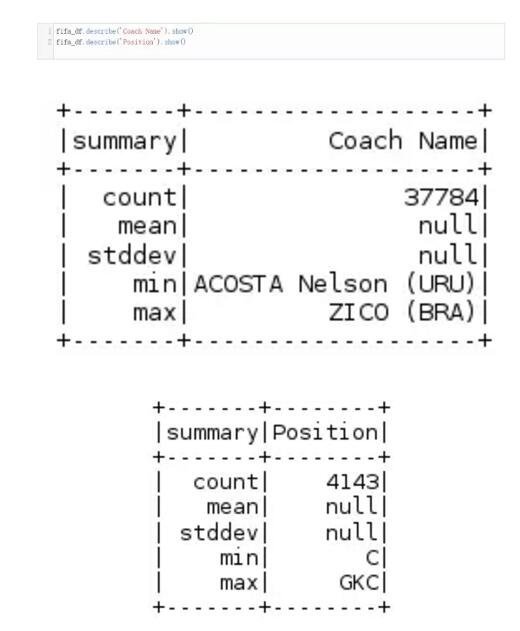
如果我们要看一下数据框中某指定列的概要信息,我们会用describe方法。这个方法会提供我们指定列的统计概要信息,如果没有指定列名,它会提供这个数据框对象的统计信息。
5. 查询多列
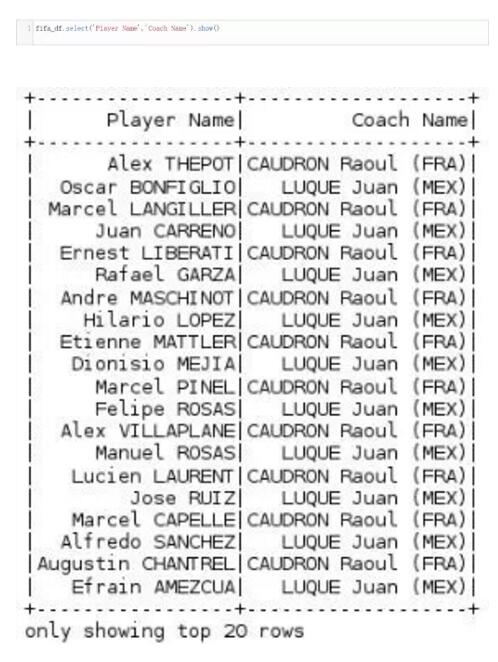
如果我们要从数据框中查询多个指定列,我们可以用select方法。
6. 查询不重复的多列组合
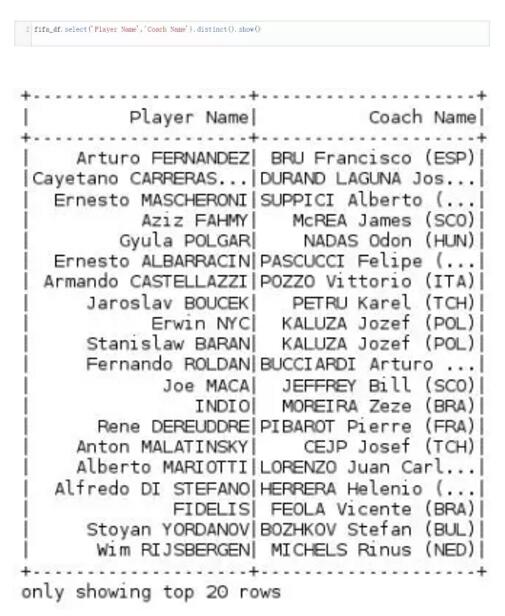
7. 过滤数据
为了过滤数据,根据指定的条件,我们使用filter命令。 这里我们的条件是Match ID等于1096,同时我们还要计算有多少记录或行被筛选出来。

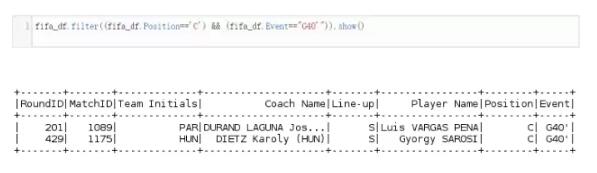
8. 过滤数据(多参数)
我们可以基于多个条件(AND或OR语法)筛选我们的数据:
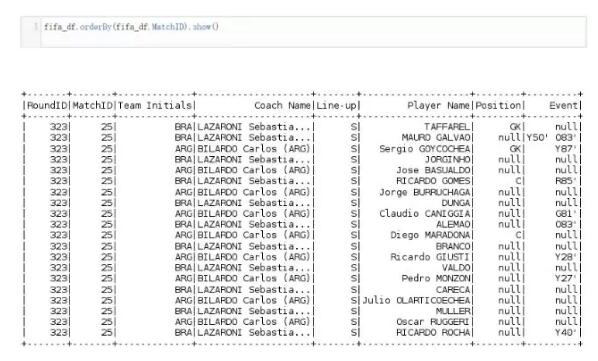
9. 数据排序 (OrderBy)
我们使用OrderBy方法排序数据。Spark默认升序排列,但是我们也可以改变它成降序排列。
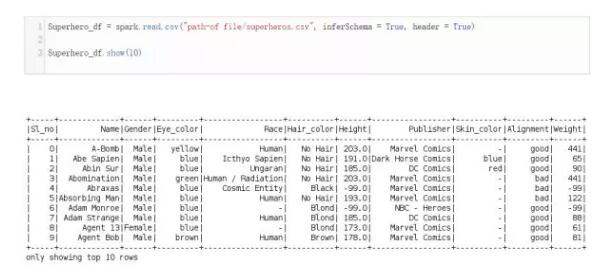
PySpark数据框实例2:超级英雄数据集
1. 加载数据
这里我们将用与上一个例子同样的方法加载数据:
2. 筛选数据

3. 分组数据
GroupBy 被用于基于指定列的数据框的分组。这里,我们将要基于Race列对数据框进行分组,然后计算各分组的行数(使用count方法),如此我们可以找出某个特定种族的记录数。

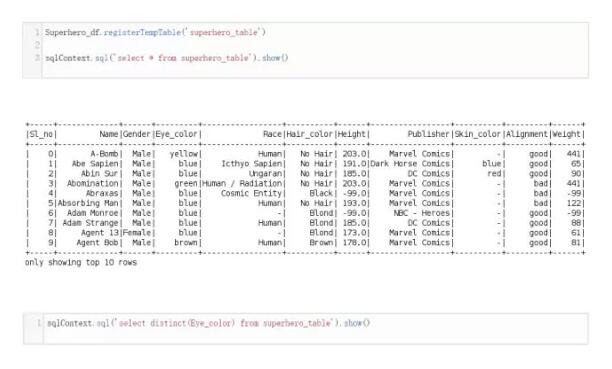
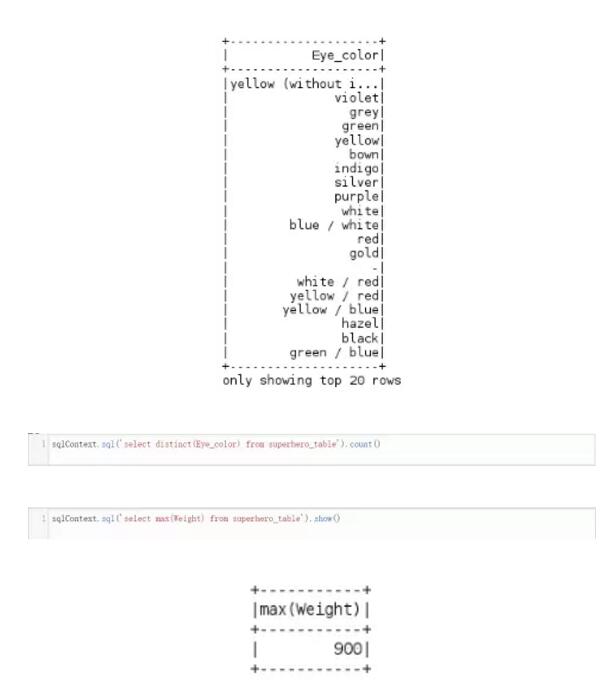
4. 执行SQL查询
我们还可以直接将SQL查询语句传递给数据框,为此我们需要通过使用registerTempTable方法从数据框上创建一张表,然后再使用sqlContext.sql()来传递SQL查询语句。
到这里,我们的PySpark数据框教程就结束了。
我希望在这个PySpark数据框教程中,你们对PySpark数据框是什么已经有了大概的了解,并知道了为什么它会在行业中被使用以及它的特点。恭喜,你不再是数据框的新手啦!

时间:2018-09-21 00:24 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















