比拼生态和未来,Spark和Flink哪家强?

在前一篇文章《Spark 比拼 Flink:下一代大数据计算引擎之争,谁主沉浮?》中,作者对 Spark 和 Flink 的引擎做了对比。但对于用户来说,引擎并不是考虑数据产品的唯一方面。开发和运维相关的工具和环境、技术支持、社区等等,对能不能在引擎上面做出东西来都很重要,这些构成了一个产品的生态。可以说,引擎决定了功能和性能的极限,而生态能让这些能力真正发挥出作用。
概 况

Spark 是最活跃的 Apache 项目之一。从 2014 年左右开始得到广泛关注。Spark 的开源社区一度达到上千的活跃贡献者。最主要推动者是 Databricks,由最初的 Spark 创造者们成立的公司。今年 6 月的 Spark+AI 峰会参加人数超过 4000。 Spark 因为在引擎方面比 MapReduce 全面占优,经过几年发展和 Hadoop 生态结合较好,已经被广泛视为 Hadoop MapReduce 引擎的取代者。

Flink 也是 Apache 顶级项目,创始者们成立了 Data Artisans。社区规模还无法和 Spark 相比。不过在业界,特别是流处理方面,有不错的口碑。在大规模流处理方面走在最前沿,也是需求最强的几个美国公司,包括 Netflix、 LinkedIn、Uber、Lyft 等,除 LinkedIn 有自己的 Samza 外,都已经采用 Flink 作为流处理引擎或者有了较大投入。
阿里集团在 Flink 社区也有较大影响力。最近 Flink 1.3 到 1.5 里都有几个重磅功能是阿里和 Data Artisans 合作或者独立开发的。阿里还有可能是世界上最大的流计算集群,也是在 Flink 的基础上开发的。
Unified Analytic platform
最近的 Spark+AI 峰会上, Databricks 主打的主题是统一分析平台(Unified Analytics Platform)。三大新发布:Databricks delta、Databricks Runtime for ML和 ML flow,都是围绕这一主题。随着近年来机器学习(包括深度学习)在数据处理中占比越来越高,可以说 Databricks 又一次把握住了时代的脉搏。
统一分析平台回应了 Spark 的初衷。经过几年的探索,对初始问题,即用户可以在一个系统里解决绝大部分大数据的需求,有了一个比较明确具体的解决方案。
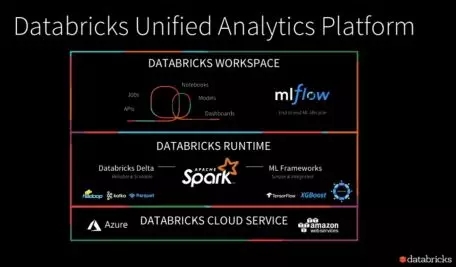
不过有意思的是可以看出 Databricks 在 AI 方面策略的转变。在深度学习流行前,Spark 自带的 MLLib 功能上应该是够用的,但是可能是由于兼容性原因并没有取得预期中的广泛采用。
对深度学习的新宠 TensorFlow,Spark 曾经推出过 TensorFrames 和 Spark 引擎做了一些集成。结果应该不是很成功,可能还没有 Yahoo 从外面搭建的 TensorFlowOnSpark 影响力大。
从这次来看,Spark 转向了集成的策略。Databricks Runtime for ML 实际上就是预装了各个机器学习框架,然后支持在 Spark 任务里启动一个比如 TensorFlow 自己的集群。Spark 引擎方面做的主要改进就是 gang scheduling,即支持一次申请多个 executor 以便 TensorFlow 集群能正常启动。
MLFlow 更是和 Spark 引擎无关。作为一个工作流工具,MLFlow 的目标是帮助数据科学家提高工作效率。主要功能是以项目为单位记录和管理所做的机器学习试验,并支持分享。设计要点是可重复试验,以及对各种工具的灵活易用的支持。看起来 Spark 暂时在作为 AI 引擎方面可能没什么大动作了。
Flink 的目标其实和 Spark 很相似。包含 AI 的统一平台也是 Flink 的发展方向。Flink 从技术上也是可以支持较好的机器学习集成和整条链路的,而且有一些大规模线上学习的使用实例。不过看起来在现阶段 Flink 这方面的平台化还没有 Spark 成熟。值得一提的是 Flink 由于流处理引擎的优势,在线上学习方面可能能支持得更好一些。
数据使用者
产品和生态归根结底是要解决大数据使用者的问题,从数据中产生价值。了解数据的使用者和他们的需求可以帮助我们在在讨论生态的各方面时有一个比较清晰的脉络。
数据相关的工作者大致可以分为以下角色。实际情况中一个组织里很可能几个角色在人员上是重合的。各个角色也没有公认的定义和明确的界限。
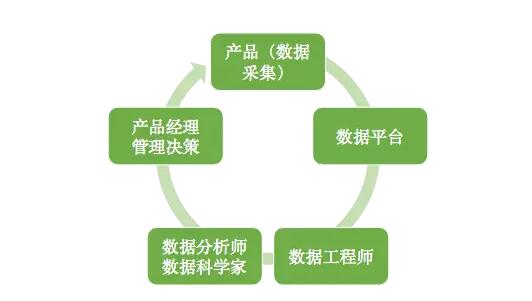
数据采集:在产品和系统中合适的地方产生或收集数据发送到数据平台。
平台:提供数据导入,存储,计算的环境和工具等等。
数据工程师:使用数据平台把原始数据加工成可以供后续高效使用的数据集。把分析师和数据科学家创建的指标和模型等等生产化成为高效可靠的的自动处理。
数据分析师和数据科学家(关于这两者的异同有很多讨论。感兴趣的可以自行搜索。https://www.jianshu.com/p/cfd94d9e4466 这里的译文可以提供一个视角):为数据赋予意义,发现内含的价值。 下文再不特别区分的地方统称为数据分析。
产品经理,管理和决策层:根据以上产生的数据调整产品和组织行为。
这些构成了一个完整的环。上面的顺序是数据流动的方向,而需求的驱动是反过来的方向。
本文所说的 Spark 和 Flink 的生态主要是对应到数据平台这一层。直接面向的用户主要是数据工程师、数据分析师和数据科学家。好的生态能够大大简化数据平台和数据工程师的工作,并使得数据分析师和数据科学家更加自主化同时提高效率。
开发环境
API
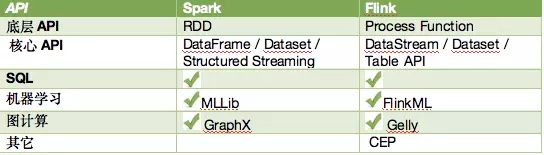
从 API 上来看,Spark 和 Flink 提供的功能领域大致相当。当然具体看各个方向支持的程度会有差异。总体来看 Spark 的 API 经过几轮迭代,在易用性,特别是机器学习的集成方面,更强一些。Flink 在流计算方面更成熟一些。
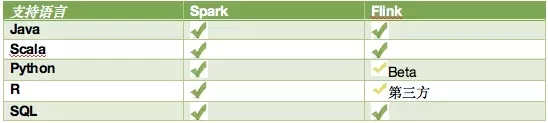
支持的语言也大致相当。Spark 发展的时间长一些还是有优势,特别是数据分析常用的 Python 和 R。
Connectors
有了 API,再有数据就可以开工了。Spark 和 Flink 都能对接大部分比较常用的系统。如果暂时还没有支持的,也都能比较好地支持自己写一个 connector。
https://databricks.com/spark/about
https://www.slideshare.net/chobeat/data-intensive-applications-with-apache-flink
集成开发工具
这方面数据工程师和数据分析的需求有一些不同。
数据分析的工作性质比较偏探索性,更强调交互性和分享。Notebook 能比较好地满足这些需求,是比较理想的开发工具,用来做演示效果也相当不错。比较流行的 Notebook 有 Apache Zeppelin,Jupyter 等。Databricks 更是自己开发了 Databricks Notebook 并将之作为服务的主要入口。Zeppelin 支持 Spark 和 Flink,Jupyter 还只支持 Spark。
数据工程师的工作更倾向于把比较确定的数据处理生产化,能快速把代码写出来是一方面。另外还有项目管理,版本管理,测试,配置,调试,部署,监控等等工作,需求和传统的集成开发工具比较相似。 还经常出现需要复用已有的业务逻辑代码库的情况。Notebook 对其中一些需求并不能很好地满足。比较理想的开发工具可能是类似 IntelliJ 加上 Spark/Flink 插件,再加上一些插件能直接提交任务到集群并进行调试,并对接 Apache Oozie 之类的工作流管理等等。在开源社区还没有见到能把这些集成到一起的。在商业产品中倒是见过一些比较接近的。Spark 和 Flink 在这方面差不多。
运行环境
部署模式 / 集群管理 / 开源闭源
应用开发完后要提交到运行环境。Spark 和 Flink 都支持各种主流的部署环境,在这方面都算做得比较好的。
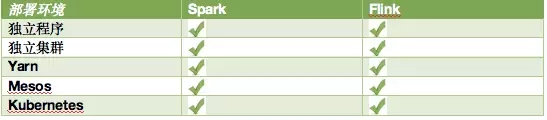
企业级平台
既然 Spark 和 Flink 都支持各种部署方式,那一个企业是否可以使用开源代码快速搭建一个支持 Spark 或者 Flink 的平台呢?
这个要看想要达到什么效果了。最简单的模式可能是给每个任务起一个独占集群,或着给小团队一个独立集群。这个确实可以很快做到,但是用户多了以后,统一运维的成本可能太高,需要用户参与运维。还有一个缺点是资源分配固定,而负载会有变化,导致资源利用率上不去。比较理想的是多租户的共享大集群,可以提高运维效率的同时最大限度地提高资源利用率。而这就需要一系列的工作,比如不同的作业提交方式,数据安全与隔离等等。对一些企业来说,可能利用托管服务(包括云服务)是一种值得考虑的开始方式。
社 区
Spark 社区在规模和活跃程度上都是领先的,毕竟多了几年发展时间。而且作为一个德国公司,Data Artisans 想在美国扩大影响力要更难一些。不过 Flink 社区也有一批稳定的支持者,达到了可持续发展的规模。
在中国情况可能会不一样一些。比起美国公司,中国公司做事情速度更快,更愿意尝试新技术。中国的一些创新场景也对实时性有更高的需求。这些都对 Flink 更友好一些。
近期 Flink 的中国社区有一系列动作,是了解 Flink 的好机会。
Spark 的中文文档在 http://www.apachecn.org/bigdata/spark/27.html。
Flink 的中文社区在 http://flink-china.org/。
另外,今年年底 Flink 中文社区也会在北京举办 Flink Forward China 大会,感兴趣的朋友可以关注。
未来发展趋势
近两年一个明显的趋势就是机器学习在数据处理中的比重增长。Spark 和 Flink 都能支持在一个系统中做机器学习和其它数据处理。谁能做得更好就能掌握先机。
另一个可能没有那么明显的趋势是,随着 IOT 的增长以及计算资源和网络的持续发展,实时处理需求会越来越多。现在其实真正对低延迟有很高追求的业务并没有那么多,所以每一次流计算新技术的出现都能看到那几家公司的身影。随着新应用场景的出现和竞争环境的发展,实时处理可能会变得越来越重要。Flink 现在在这方面是领先的,如果发挥得好可以成为核心优势。
还有一点值得一提的是,因为用户不想锁定供应商,担心持续的支持等原因,是否开源已经成为用户选择数据产品的一个重要考量。闭源产品如果没有决定性优势会越来越难和基于开源技术的产品竞争。
总 结
Spark 和 Flink 都是通用的开源大规模处理引擎,目标是在一个系统中支持所有的数据处理以带来效能的提升。两者都有相对比较成熟的生态系统。是下一代大数据引擎最有力的竞争者。Spark 的生态总体更完善一些,在机器学习的集成和易用性上暂时领先。Flink 在流计算上有明显优势,核心架构和模型也更透彻和灵活一些。在易用性方面两者也都还有一些地方有较大的改进空间。接下来谁能尽快补上短板发挥强项就有更多的机会。
作者
:王海涛,曾经在微软的 SQL Server 和大数据平台组工作多年。带领团队建立了微软对内的 Spark 服务,主打 Spark Streaming。

时间:2018-09-21 00:23 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]Apache Hudi 0.8.0 版本发布,Flink 集成有重大提升以
- [数据挖掘]Spark 迁移到 K8S 在有赞的实践与经验
- [数据挖掘]Spark Operator 初体验
- [数据挖掘]如何实现Spark on Kubernetes?
- [数据挖掘]基于Flink+Hive构建流批一体准实时数仓
- [数据挖掘]Spark SQL 物化视图技术原理与实践
- [数据挖掘]Spark on K8S 的最佳实践和需要注意的坑
- [数据挖掘]Spark 3.0重磅发布!开发近两年,流、Python、SQL重
- [数据挖掘]深度解读:Flink 1.11 SQL 流批一体的增强与完善
- [数据挖掘]深入分析 Flink SQL 工作机制
相关推荐:
网友评论:















