Uber开源Manifold:机器学习可视化调试工具
在 2019 年 1 月,Uber 推出了 Manifold,这是一种与模型无关的机器学习可视化调试工具,用来识别机器学习模型中的问题。为了让其他机器学习从业者能够享受到这个工具带来的好处,日前,Uber 宣布 将 Manifold 作为开源项目发布。
根据介绍,Manifold 将帮助工程师和科学家识别机器学习数据切片和模型性能问题,并通过显示数据子集之间的特征分布差异来诊断问题的根本原因。在 Uber,Manifold 已经成为机器学习平台 Michelangelo 的一部分,并帮助 Uber 的各个产品团队分析和调试机器学习模型的性能。
自从去年早些时候 在 Uber Eng Blog 上重点介绍这个项目以来,Uber 已经收到了很多来自社区的反馈,这些反馈都是关于这个项目在通用机器学习模型调试场景中的潜力。在开源 Manifold 的独立版本中,Uber 认为,这个工具通过为机器学习工作流提供可解释性和可调试性,同样也会使机器学习社区受益。
版本 1 的新特性
在 Manifold 的第一个开源版本中,Uber 添加了各种特性,使模型调试比内部迭代更容易。
版本 1 的特性包括:
通用二进制分类和回归模型调试的模型无关性支持。 用户将能够分析并比较各种算法类型的模型,使他们能够辨别不同数据切片的性能差异。
对表格特征输入的可视化支持,包括数字、类别和地理空间特征类型。 利用每个数据切片的特征值分布信息,用户可以更好地了解某些性能问题的潜在原因,例如,模型的预测损失与其数据点的地理位置和分布之间是否存在相关性。
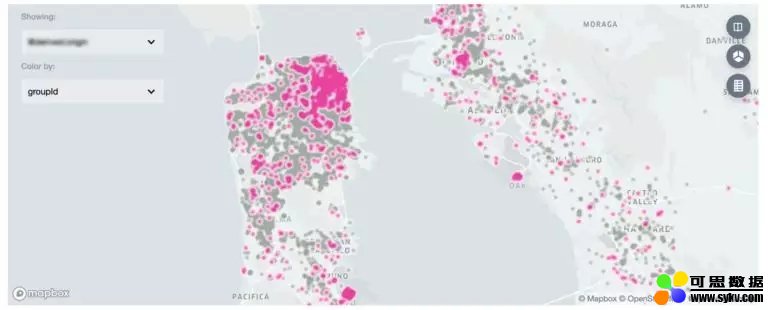
图 1. Manifold 新的升级包括对地理空间特征的可视化支持
与 Jupyter Notebook 集成。Manifold 接受作为 Pandas DataFrame 对象的数据输入,并在 Jupyter 中呈现该数据的可视化效果。由于 Jupyter Notebook 是数据科学家和机器学习工程师使用最广泛的数据科学平台之一,因此这种集成让用户得以能够在不中断正常工作流的情况下分析他们的模型。
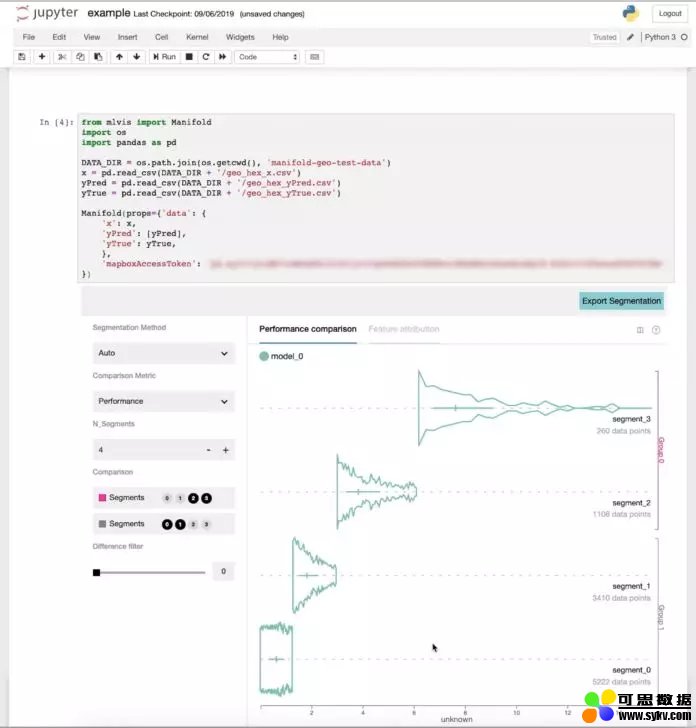
图 2. Manifold 的 Jupyter Notebook 集成接受作为 Pandas DataFrame 对象的数据输入,并在 Jupyter Notebook UI 中呈现可视化效果
基于每个实例预测损失和其他特征值的交互式数据切片和性能比较。 用户将能够根据预测损失、基准真相(Ground Truth)或其他感兴趣的特征对数据进行切片和查询。这个特性将使用户能够通过通用的数据切片逻辑快速验证或拒绝其假设。
译注:基准真相(Ground Truth,又称:地面实况、上帝真相)是一个相对概念;它是指相对于新的测量方式得到的测量值,作为基准的,由已有的、可靠的测量方式得到的测量值(即经验证据)。人们往往会利用基准真相,对新的测量方式进行校准,以降低新测量方式的误差和提高新测量方式的准确性。机器学习领域借用了这一概念。使用训练所得模型对样本进行推理的过程,可以当做是一种广义上的测量行为。因此,在有监督学习中,Ground Truth 通常指代样本集中的标签。
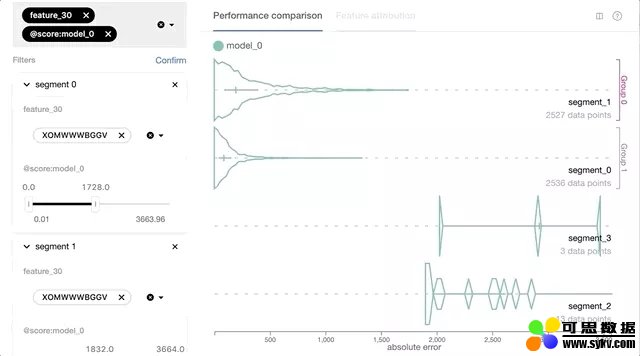
图 3. 基于每个实例预测损失和特征值的交互式数据切片允许用户更好地理解机器学习模型的性能问题
下一步
Manifold 的开源版本提供了 npm 软件包版本,而对于 Jupyter Notebook 的绑定,则提供了一个 Python 包版本。要开始使用 Manifold,请按照 GitHub Repo 中的文档进行操作并在本地安装,或者查看 Uber 的演示网站。
作者简介:Lezhi Li,Uber 机器学习平台团队的软件工程师。
原文链接:https://eng.uber.com/manifold-open-source/

时间:2020-01-19 00:05 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]轻松快速地调整Kubernetes的CPU和内存
- [数据挖掘]Kubernetes 如果是个水族馆
- [数据挖掘]Mirantis及时现身,接过Kubernetes dockershim支持大旗
- [数据挖掘]什么?Kubernetes已然弃用Docker?
- [数据挖掘]如何用Prometheus监控十万container的Kubernetes集群
- [数据挖掘]如何实现Spark on Kubernetes?
- [数据挖掘]Uber为什么放弃Postgres选择迁移到MySQL?
- [数据挖掘]关于 Kubernetes 的这些原理,你一定要了解
- [数据挖掘]使用Kubernetes两年来的经验教训
- [数据挖掘]Kubernetes与GlusterFS的爱恨情仇
相关推荐:
网友评论:















